
问鼎ImageNet和CIFAR-100双料冠军,这个中国团队是如何做到的?

新智元报道
编辑:张佳
【新智元导读】在前不久结束的NeurIPS 2019上,由Google、Facebook、OpenAI等机构共同主办的神经网络压缩与加速竞赛备受瞩目。历经五个多月的厮杀,中国科学院自动化研究所及中国科学院自动化研究所南京人工智能芯片创新研究院联合团队获得ImageNet和CIFAR-100双项冠军。今天为大家奉上技术解读。现在戳右边链接上新智元小程序 了解更多!
以模型压缩和加速为代表的深度学习计算优化技术是近几年学术界和工业界最为关注的焦点之一。随着人工智能技术不断地落地到各个应用场景中,在终端上部署深度学习方案面临了新的挑战:模型越来越复杂、参量越来越多,但终端的算力、功耗和内存受限,如何才能得到适用于终端的性能高、速度快的模型?
在前不久结束的神经信息处理系统大会(NeurIPS 2019)上,由Google、Facebook、OpenAI等机构在NeurIPS2019上共同主办的神经网络压缩与加速竞赛(MicroNet Challenge)备受瞩目。
竞赛旨在通过优化神经网络架构和计算,达到模型精度、计算效率和硬件资源占用等方面的平衡,实现软硬件协同优化发展,启发新一代硬件架构设计和神经网络架构设计等。
历经五个多月的厮杀,中国科学院自动化研究所及中国科学院自动化研究所南京人工智能芯片创新研究院联合团队获得ImageNet和CIFAR-100双项冠军。
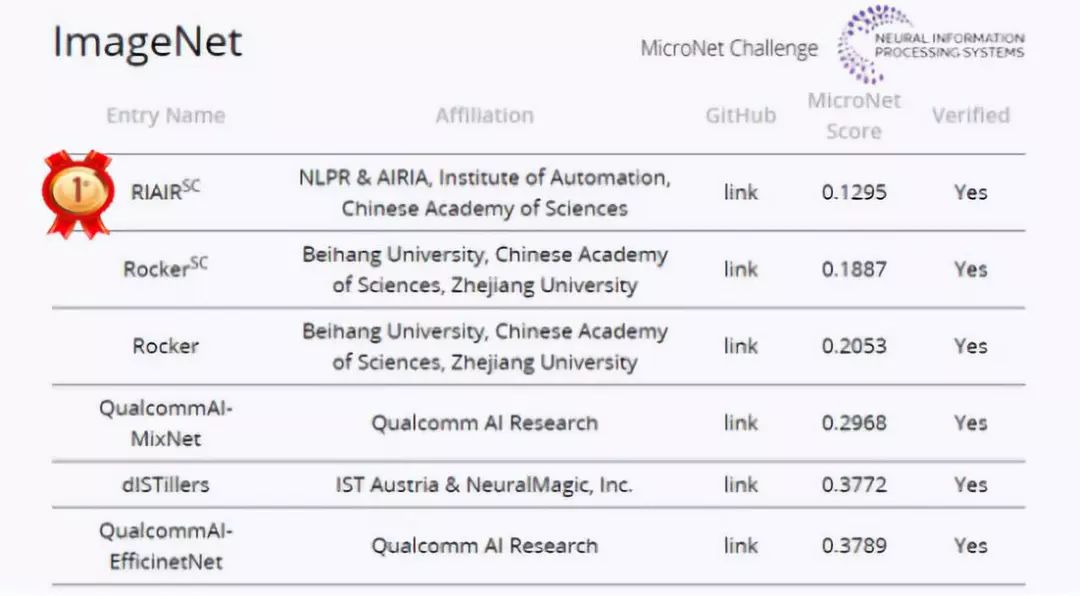
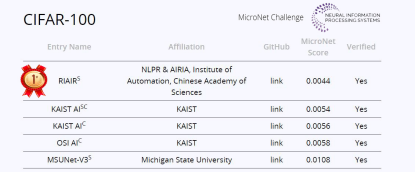
结合极低比特量化技术和稀疏化技术,他们团队在ImageNet任务上相比主办方提供的基准模型取得了20.2倍的压缩率和12.5倍的加速比,在CIFAR-100任务上取得了732.6倍的压缩率和356.5倍的加速比,遥遥领先两个任务中的第二名队伍。接下来为大家奉上技术解读。
技术解读:如何实现732.6倍的压缩率和356.5倍的加速比?
赛题介绍
本比赛总共包括三个赛道:ImageNet分类、CIFAR-100分类、WikiText-103语言模型。在三个赛道上,参赛团队要求构建轻量级网络,在精度满足官方要求的条件下,尽可能降低网络计算量和存储。对于ImageNet分类,要求至少达到75%的top-1精度,而对于CIFAR-100,top-1精度需要达到80%以上。
评测指标
最终评分指标包括存储压缩和计算量压缩两部分,均采用理论计算量和存储进行计算。
对于存储,所有在推理阶段需要使用的参数均需要计算在内,比如稀疏化中的mask、量化中的字典、尺度因子等。对于存储,32比特位算作一个参数,低于32比特的数按照比例计算,例如8比特数算作1/4个参数。
对于计算量,乘法计算量和加法计算量分别计算。对于稀疏而言,稀疏的位置可以认为计算量为0。对于定点量化,32比特操作算作一个操作,低于32比特的操作按照比例计算。操作的比特数认为是两个输入操作数中较大的那一个,例如一个3比特数和一个5比特数进行计算,输出为7比特数,那么该操作数为5/32。
对于ImageNet,以MobileNet-V2-1.4作为基准(6.9M参数,1170M计算量,精度大约为75%)。所以,如果参数量记为Param,计算量记为Operation,则最终评分Score为:
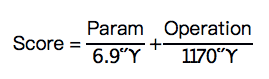
对于CIFAR-100,以WideResNet-29-10为基准(36.5M参数,10.49B计算量,精度大约为80%),评分公式为:
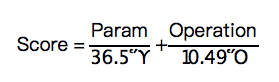
解决方案
主要采用稀疏化+量化的方式,主要包括模型选择、网络剪枝、定点量化、算子融合等操作,实现大规模稀疏和极低比特压缩。
首先是模型选择,复杂的模型往往具有更高的精度,参数量和计算量较大,但同时压缩空间也比较大;轻量级模型精度相对较低,但参数量和计算量相对较小,同时对网络压缩也比较敏感,因此需要在模型复杂度和精度之前进行权衡。团队选择轻量级、同时精度略高于比赛要求的网络。最终在ImageNet上选择了MixNet-S模型(精度75.98%),在CIFAR-100上选择了DenseNet-100(精度81.1%)。
在确定好模型之后,先对网络进行剪枝,去掉不重要的参数量和计算。在这之前,对每一层进行了鲁棒性分析。具体而言,对于每一层,团队进行稀疏度从0.1到0.9的剪枝,然后测试网络精度。图1显示了网络各层对不同稀疏度的影响,可以看出某几层对网络剪枝特别敏感,而其余一些层对剪枝却很鲁棒。基于此,确定了每一层的稀疏度,然后删除不重要的节点,再对剩余连接进行重新训练。可以实现在稀疏度大概为60%的情况下,精度损失只有0.4%。
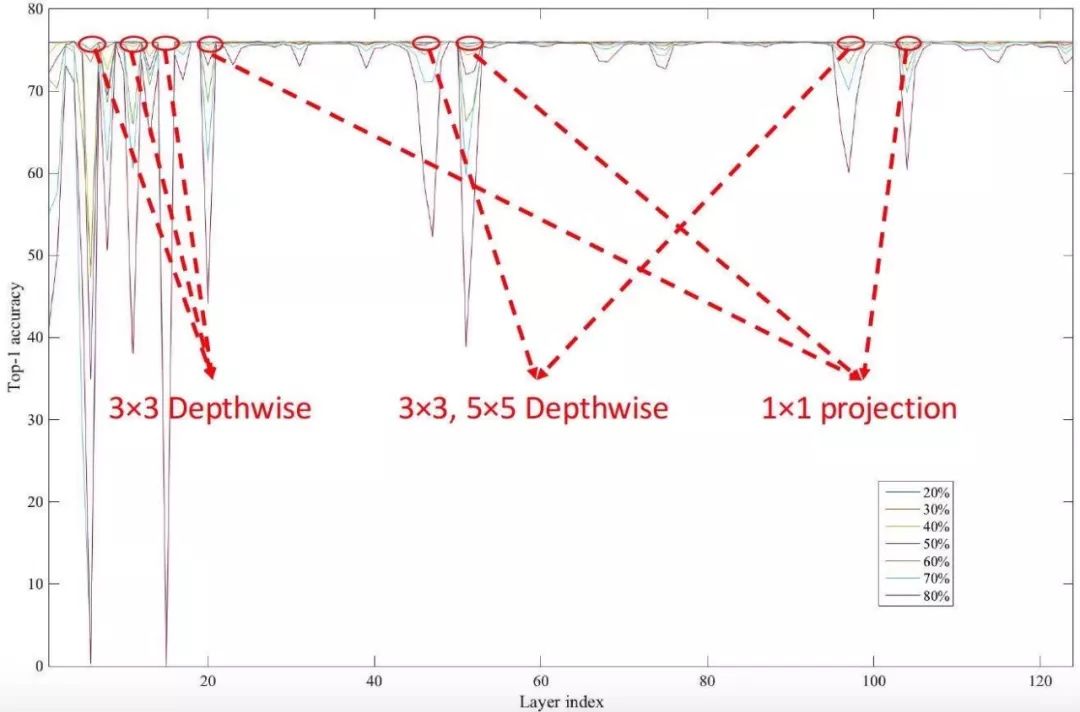
图1 网络各层对剪枝操作的鲁棒性分析
在对网络进行剪枝以后,再对网络进行定点量化。采用了均匀量化策略,量化公式如下:
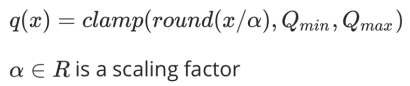
对于激活,每层引入一个浮点数尺度因子;而对于权值,每个3D卷积核引入一个浮点数尺度因子。在给定比特数的情况下,以上优化公式唯一的待求解参数就是尺度因子,即优化目标为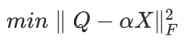 ,采用迭代优化的方式计算出每一层的尺度因子。在求解尺度因子之后,与网络剪枝类似,需要对网络进行微调来恢复精度,在网络微调阶段,我们保持尺度因子一直不变。通过以上方式,可以实现在激活7比特,参数大部分为3、4、5比特的情况下,网络精度损失为0.5个点,最终网络模型top-1精度为75.05%。
,采用迭代优化的方式计算出每一层的尺度因子。在求解尺度因子之后,与网络剪枝类似,需要对网络进行微调来恢复精度,在网络微调阶段,我们保持尺度因子一直不变。通过以上方式,可以实现在激活7比特,参数大部分为3、4、5比特的情况下,网络精度损失为0.5个点,最终网络模型top-1精度为75.05%。
最后,团队进行了算子融合,把量化中的尺度因子、卷积层偏置、BN层参数等融合成一个Scale层,以进一步降低网络的存储和计算量。最终,自动化所团队的方法在ImageNet上只有0.34M参数和93.7M计算量,相对于基准模型实现20.2倍的压缩和12.5倍的加速;而在CIFAR-100上,模型存储仅有49.8K,计算量为29.4M,相对于基准模型压缩732.6倍,加速365.5倍。
寒冬里,这个最酷AI创新平台招人啦!新智元邀你2020勇闯AI之巅
在新智元你可以获得:
- 与国内外一线大咖、行业翘楚面对面交流的机会
- 掌握深耕人工智能领域,成为行业专家
- 远高于同行业的底薪
- 五险一金+月度奖金+项目奖励+年底双薪
- 舒适的办公环境(北京融科资讯中心B座)
- 一日三餐、水果零食