
许式伟:相比 Python,我们可能更需要 Go+
技术编辑:鸣飞丨发自 思否编辑部
SegmentFault 思否报道丨公众号:SegmentFault
ECUG(Effective Cloud User Group,实效云计算用户组)主办的 2021 ECUG Con 于 2021 年 4 月 10 日 - 11 日在上海举办。会上,七牛云 CEO 许式伟以 “数据科学与 Go+” 为主题发表了主题分享,讲述了对数据科学变迁的理解,对新语言 Go+ 的设想和规划,并大胆指出数据科学正迎来爆发期,像字节跳动一样的新型公司只会越来越多。以下为演讲内容整理。

刚才在闲聊说 ECUG 变得越来越高大上,其实我也变得越来越像一个单纯的讲师。今年是 ECUG 社区的第 14 个年头,这场活动也是第 14 届 ECUG Con。其实这一届本来应该在去年办,但因为疫情延后了。
语言的发展 数据科学的发展 Go+ 的设计理念 Go+ 实现的迭代
SegmentFault 思否
语言的发展
首先,我们讲讲语言的发展,程序员对这个话题非常感兴趣。我把语言的发展史分为三个部分来说。
第一,静态语言的发展史。我选的是 TOP20 的语言,这个是根据现在最火的语言排行榜排名选的,前 20 名的语言我排了一下大概是这样的,最早发布的是 C,到现在其实还在排行榜前三的位置。第二是 C++,Objective-C、Java、C#、Go、Swift、Go+。我们可以看到一个比较有趣的现象,差不多每 6-8 年会出现一轮新的、具备影响力的静态语言,这是生产力迭代的表征。

第二,脚本语言的发展。你会发现它们非常不一样。最早是 Visual Basic,然后是 Python、PHP、JavaScript、Ruby,脚本语言是集中大爆发的,差不多全在 Java 出现的前后,来自 90 年代的前 5 个年头。这是非常有趣的一件事情,也是非常值得思考的,背后一定有一些内在的原因。

第三,数据科学相关语言的发展。但数据科学我选的是 TOP50,因为 TOP20 实在太少了。也蛮有意思的,最早的是 SQL,第二个 SAS,MATLAB、Python、R、Julia。Python 最早从来没想过自己会是数据科学语言,但最终变成了人工智能领域最火的语言。

这里又存在一个很明显的特征:它的跨度跟静态语言一样大,所以数据科学发展其实是古老而漫长的,但发展得没有那么快。静态语言差不多每 6-8 年有一个迭代,但数据科学语言不是,中间跨度特别大。但我觉得现在正进入数据科学的加速期。

SegmentFault 思否
数据科学的发展

第二个时期我叫做“数据科学的基建时期”,真正让数据科学成为了基础设施,最典型的代表是大数据的兴起。Map/Reduce 是 Google 2004 年发布的一篇论文,2006 年就出现了 Hadoop,2009 年出现了 Spark。我认为这算是大数据兴起的一个阶段,也是数据科学基础设施化的开始。这个时期跟刚才的数学软件不一样,是以大规模处理能力为先,并不是以功能强大为先,它的功能相对局限。

深度学习的兴起和大数据的兴起间隔时间比较长,深度学习 2015 年开始有 TensorFlow,2017 年开始有 Torch,这是两个知名度最高的深度学习框架,深度学习本质就是通过数据自动推导 y=F(x)中的 F 函数。我们平常通常都是程序员实现这个 F,但深度学习最核心的概念是如何让机器自动产生这个 F,来达成最佳曲线拟合。它其实是基于测量结果的自动计算。

假设今天没有牛顿三大定理,但我有一堆测量数据,理论上应该能够发现牛顿三大定理,这就是深度学习的核心逻辑。它跟大数据并不是相互取代的关系,而是一种能力的加强,更多其实是如何让大数据的能力更进一步,更强悍。
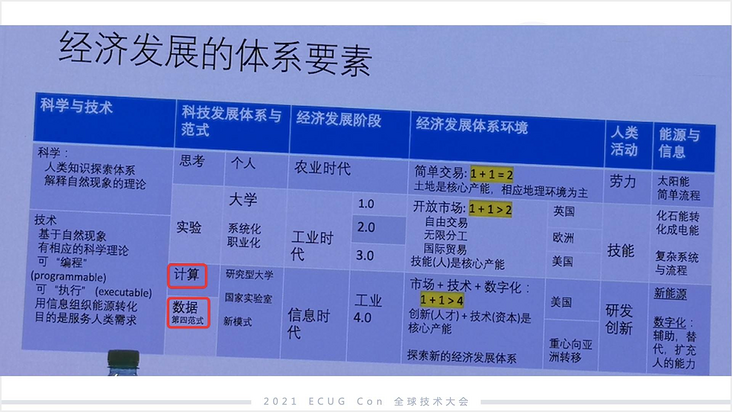
前面是数据科学的两个阶段,那么第三个阶段是什么?我觉得是数据科学的大爆发时期,也就是今天,用马云的话说是“DT 时代”。原始时期是在有限的领域,有限的数据规模下去做的一种能力。未来首先是全领域的,首先领域不局限于的商业智能( BI )这样的范畴,第二个是大规模的数据,第三个是随处可见,随处可见包括云、智能手机、嵌入式设备等,这些都会植入我们所谓的数据智能。

这就意味着,今天移动互联网的兴起已经让很多公司非常牛,互联网的平民化或互联网应用的诞生,催生了 BAT。但是我们知道,现在新兴的、比较牛的公司,像字节跳动这种,其实不是互联网的成功,而是数据科学的成功。今天仍然不能说,数据科学是平民化的,它的门槛非常高。

数据科学的未来一定是通用语言和数学软件的融合,从而完成真正意义上的数据科学的基础设施化。但在今天,数据科学的基础设施化还远没有完全完成,这是我自己的判断。

今天的 Python 已经很好了,为何需要 Go+?

这是我们今天需要 Go+ 的原因!前面主要讲我自己为什么认为 Go+有商业化的机会。当然我所说的商业化不一定是赚钱,大家不要误会这一点,语言可能在大多数人心目中是一个不赚钱的东西,但是这不代表它不重要,它非常重要。
SegmentFault 思否
Go+ 的设计理念
聊完数据科学的发展,接下来我们聊聊 Go+ 的设计理念。Go+为什么是今天这个样子?计算背后要的是程序员,而数据科学背后要的是数据科学家或者叫分析师。这两个角色其实还是不一样的,虽然都是技术工作。我认为培养程序员是相对容易的,今天程序员的数量是非常庞大的,但数据科学家的数量相对较少,这也是为什么前几年深度学习兴起以后,所谓的 AI 工程师薪资被炒翻了,比程序员贵很多。其实就是因为数据科学家不容易找。
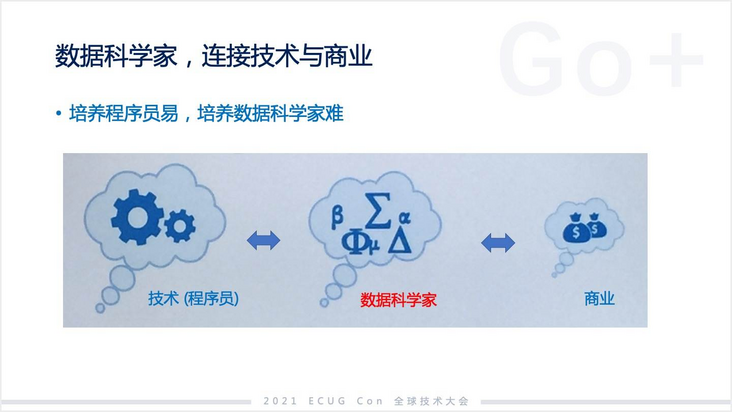
那么 Go+ 的核心理念又是什么呢?

在这个基础上,我们延伸了一些设计逻辑。首先,Go+ 是一个静态语言,语法是完全兼容 Go 的;第二,形式上要比 Go 更像脚本,有更低的学习门槛。Go 虽然在静态语言里,可能学习门槛是低的,但还不够低,没有 Python 那么低;第三,很自然的,我们要做一个数据科学的语言,所以它必然要有更简洁的、数学运算上的语言文法支持;第四是双引擎,同时支持静态编译为可执行文件,也支持编译成字节码来解释执行。

为什么我们会选择语法完全兼容 Go 呢?首先我个人很坚定地认为,静态语言拥有更强的生命力,更能跨越历史的周期。大家也都很容易理解,语言是需要跨越周期的,语言的生命周期通常都非常长。我们不能很局限地说,当前在流行些什么东西,我就如何决定语言的设计,实际上我们要找到那些能够跨越周期的元素。

第二,为什么是 Go?我个人认为,在静态语言里,Go 的语法设计最为精简,学习门槛也是最低的,哪怕你以前没有学过静态语言,也很容易学会 Go。我们公司是最早招聘 Go 程序员的,但大部分招进来的人都不会 Go。我们用 Go 的时候,世界上真没多少人认为 Go 是未来的流行语言。我们自己实践的经验表明,Go 语言两周的学习基本上够了,是门槛非常低的一门静态语言。

我这里简单列了一些 Go+ 的语法,当然不是全部,只是一些我认为还是相对比较简洁的表达。有理数 Python 里面没有,我们认为有理数在数据科学里,尤其在无损数值运算里,还是会非常常见。Go+ 内置了有理数的支持。当然 Map、Slice 基本上 Python 都有。
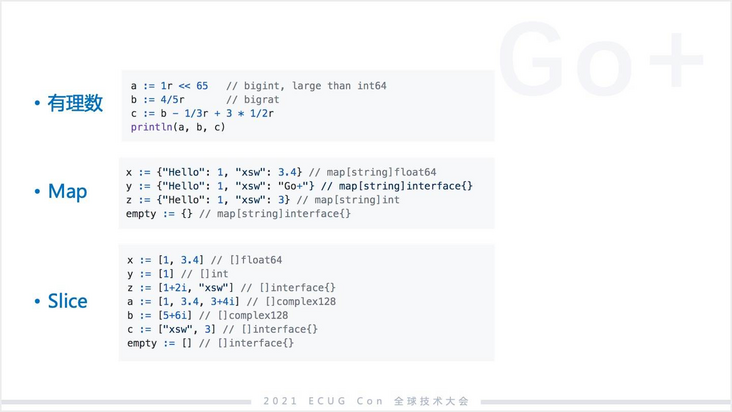
列表理解(List comprehesion)其实也是 Python 有的,但我们对列表理解的支持非常的完整,基本上理解了 Go+ 中 for 循环怎么写也就理解了列表理解。更多的还是数据科学的一些常规操作的简洁表达。以上是一个大概语法示意,如果有朋友没看过 Go+,希望可以大概对 Go+ 有个理解。

Go+ 非常有意思的一点,它是唯一一个选择了双引擎的语言,既支持静态编译,也支持可解析执行。

SegmentFault 思否
Go+ 实现上的迭代
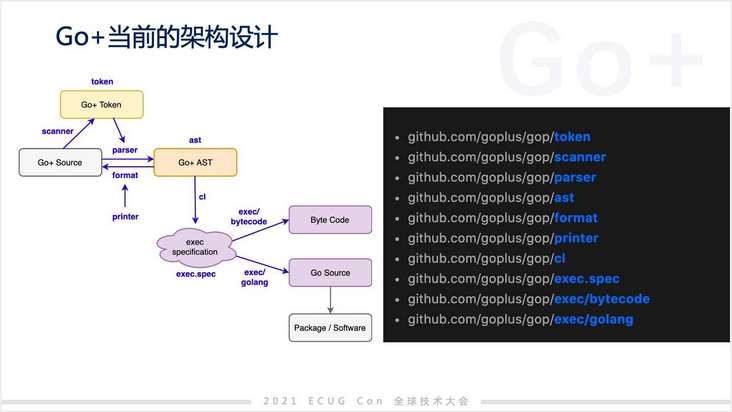
当前,我个人在迭代的过程中发现了一个问题,对一个初步加入 Go+ 团队的人来说,是需要一段时间熟悉整个业务的。Go+ 执行规范的部分,其实是一种抽象的 SAX 接口,也就是基于事件驱动,我有一个事件发送给接受方,接受方按自己的需要处理这个事件,这在文本处理里面比较常见。

下面我想讲一下 Go+ 下一步做的重心是什么。

最后,我们希望用商业化的方式来运作 Go+,也会招聘 Go+ 的团队成员,欢迎大家加入 Go+ 团队!

这是联系我们的方法,第一个是项目的地址(https://github.com/goplus),第二个投简历的邮箱(jobs@qiniu.com),第三个是我推特的地址(@xushiwei)。

权威发布丨2020 中国开源先锋 33 人之心尖上的开源人物
ECUG 社区发起人许式伟:对编程语言的选择无关阵营,关乎品味
技术人攻略访谈三十八|许式伟:十一年逆流顺流,首席架构师到 CEO
