
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
AI编辑:深度眸
0 摘要
论文题目:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
论文地址:https://arxiv.org/abs/1912.02424
ATSS简单来说就是
(1) 对于anchor-free典型算法FCOS,希望消除回归范围regress_ranges和中心扩展比例参数center_sample_radius这两个核心超参,使其在anchor-free领域变成真正的自适应算法
(2) 对于anchor-base经典算法retinanet,希望借鉴fcos的正负样本分配策略思想来弥补和fcos的性能差异,同时也能够自适应,无须设置正负样本阈值
从此anchor-base和anchor-free都不需要调核心参数,岂不美滋滋!
不仅如此,本文还通过实验回答了一个问题:anchor-base和anchor-free算法的核心差异是啥?是啥原因导致两者性能差异?结论就是:正负样本定义规则的不同导致性能差异。
本文通俗易懂,正如本文标题Bridging the Gap所示,为了清楚理解anchor-base和anchor-free特点,本文是非常值得分析的一篇目标检测算法。
贴一下框架github地址:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
1 anchor-base和anchor-free本质差别
为了说明这个问题,作者结合retinanet和fcos算法并采用了非常公平的一系列对比实验进行论证。
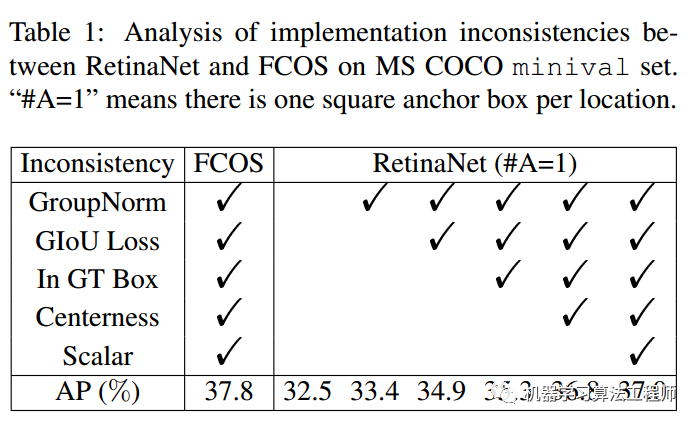
两个算法其余参数都是相同的,除了表格中的。首先FCOS在开所有训练trick时候mAP是37.8,为了公平比较retinanet设置anchor个数为1,anchor比例是正方形,可以发现当采用相同trick后,mAP是37.0,大概差了1个点,差距蛮大的。
排除上述trick因素后,现在两个算法的区别是1.正负样本定义;2.回归分支中从point回归还是从anchor回归。其中从point回归就是指的每个点预测距离4条边的距离模式,而从anchor回归是指的retinanet那种基于anchor回归的模式。
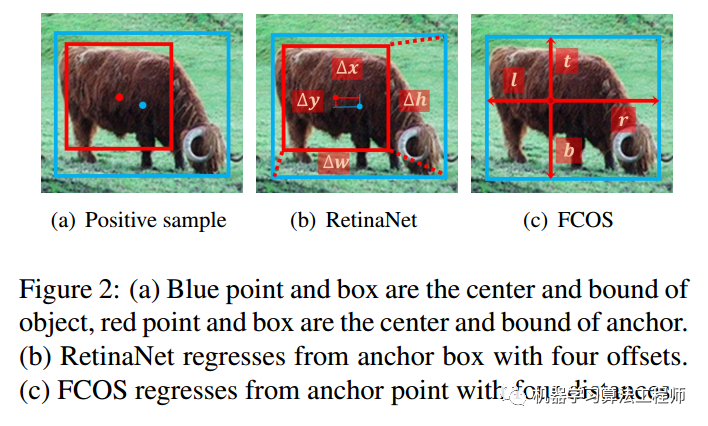
结果如下表所示:
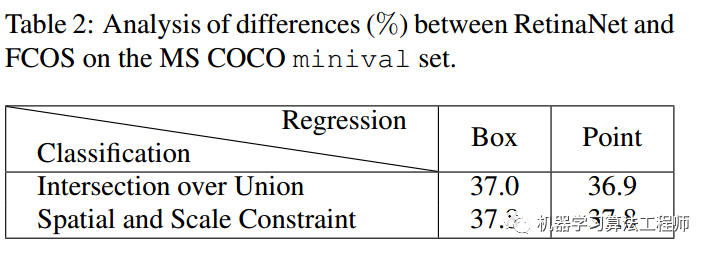
首先看行方向,可以发现不管是采用point还是box回归模式,mAP都是非常接近的,说明回归分支中从point回归还是从anchor回归对结果影响很小。再看列方向,可以发现差别就在于在定义正负样本的时候采用的策略不一样,一个是基于iou准则,一个是基于空间scale约束,而且很明显可以看出,fcos的正负样本定义策略比retinanet的max iou策略好的多。
到目前为止,我们可以知道:anchor-base和anchor-free的性能差异本质区别在于正负样本定义不同。那么其不同具体在哪里?
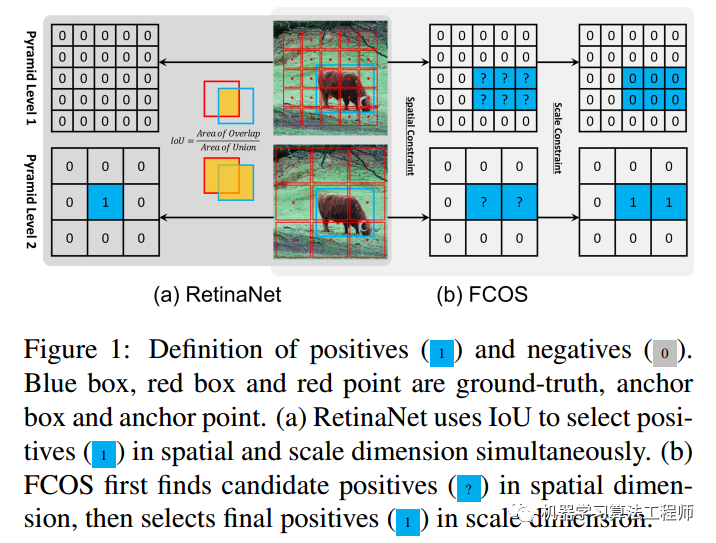
对于1和2两个输出预测层,retinanet采用统一阈值iou,可以确定上图蓝色1位置是正样本,而对于fcos来说,有2个蓝色1,其表明fcos的定义方式会产生更多的正样本区域,这种细微差距就会导致retinanet的性能比fcos低一些。关于fcos和retinanet的正负样本定义规则请参考以前微信公众号文章。
2 ATSS算法
前面我们已经知道了正负样本定义对最终性能影响很大,很明显fcos的正负样本定义规则优于retinanet,但是我们在前文说过fcos的定义规则存在两个超参:多尺度输出回归范围regress_ranges用于限制每一层回归的数值范围;中心扩展因子center_sample_radius用于计算每个输出层哪些位置属于正样本区域。这两个超参在不同的数据集上面可能要重新调整,而且不一定好设置。而本文ATSS就希望消除这两个超参,达到自适应的功能。
其定义规则也比较简单,通俗易懂,流程为:

需要注意由于依然需要计算iou,故anchor设置不能少,只不过anchor仅仅用于计算正负样本区域而已(对于fcos来说是这样,但是对于retinanet来说,anchor设置必不可少),在计算loss时候可以是anchor-free中特征图上点距离4条边的距离或者是anchor-base中基于anchor的变换回归,anchor默认设置为1。主要是理解思想:
计算每个gt bbox和多尺度输出层的所有anchor的iou
计算每个gt bbox中心和多尺度输出层的所有anchor中心的l2距离
对于任何一个输出层,遍历每个gt,找出topk(默认是9)个最小l2距离的anchor点。假设一共有l个输出层,那么对于任何一个gt bbox,都会挑选出topk×l个候选位置
对于每个gt bbox,计算所有后续位置iou的均值和标准差,两者相加得到该gt bbox的独特阈值
对于每个gt bbox,选择出候选位置中iou大于阈值的位置,该位置认为是正样本,负责预测该gt bbox
如果topk参数设置过大,可能会导致某些正样本位置不在gt bbox内部,故需要过滤掉这部分正样本,设置为背景样本
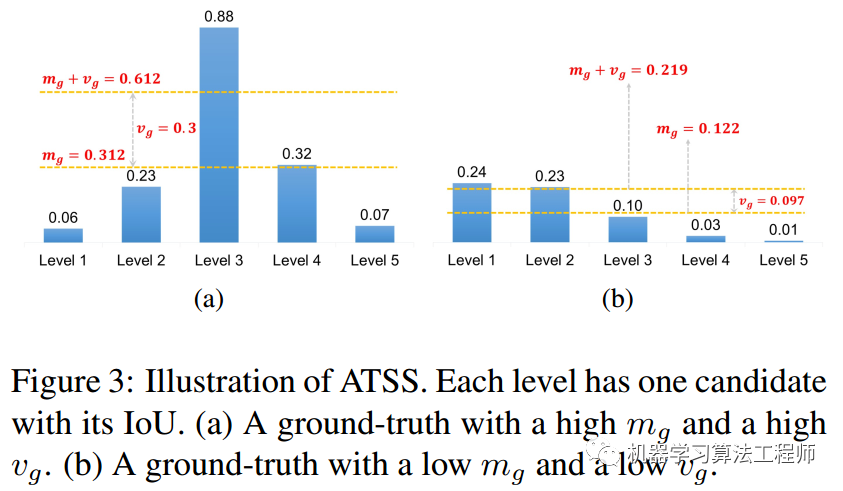
他是如何做到自适应的呢?原因是均值(所有层的候选样本算出一个均值)代表了anchor对gt衡量的普遍合适度,其值越高,代表候选样本质量普遍越高,iou也就越大,而标准差代表哪一层适合预测该gt bbox,标准差越大越能区分层和层之间的anchor质量差异。均值和标准差相加就能够很好的反应出哪一层的哪些anchor适合作为正样本。一个好的anchor设计,应该是满足高均值、高标准差的设定。
如上图所示,(a)的阈值计算出来是0.612,采用该阈值就可以得到level3上面的才是正样本,是高均值高方差的。同样的如果anchor设置和gt不太匹配,计算出来的阈值为0.219,依然可以选择出最合适的正样本区域,虽然其属于低均值、低方差的。采用自适应策略依然可以得到相对好的正负样本,至少可以保证每个GT一定有至少一个anchor负责对应。
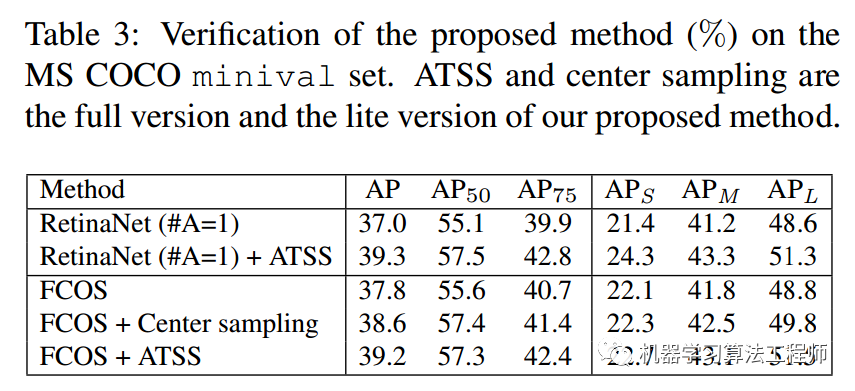
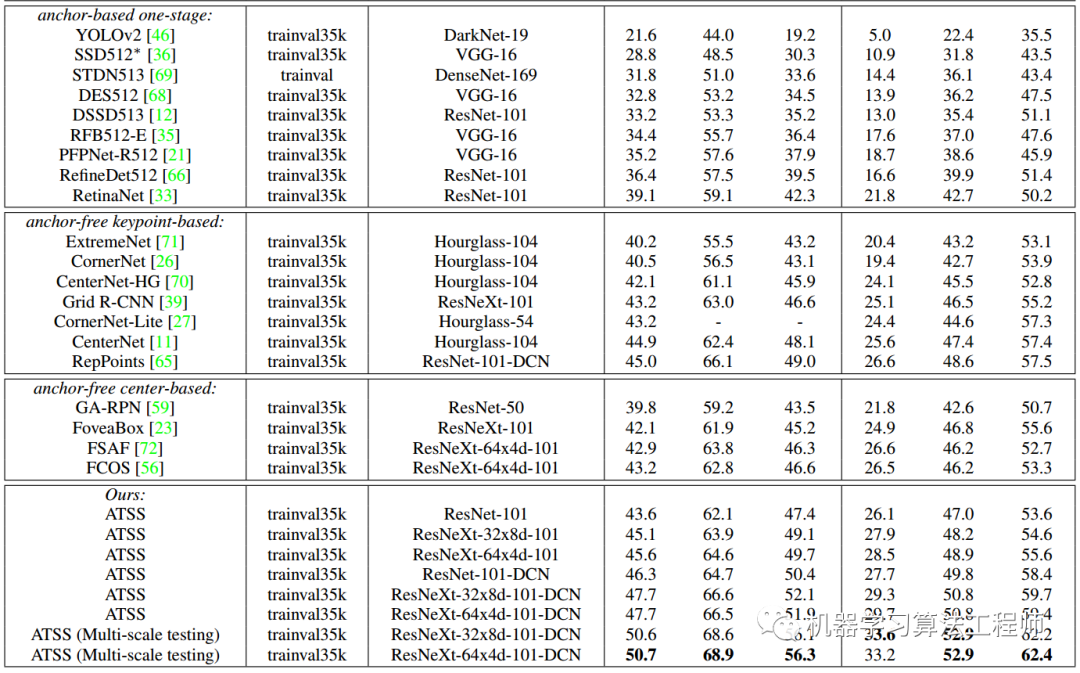
从上表可以看出,ATSS美滋滋,而且ATSS就一个topk的超参,当然实验表明参数设置不敏感(但是应该不能太小)。

3 正样本区域可视化及其参数topk分析
使用方法非常简单,在对应的train_cfg里面将debug标志设置为True即可,效果如下所示:
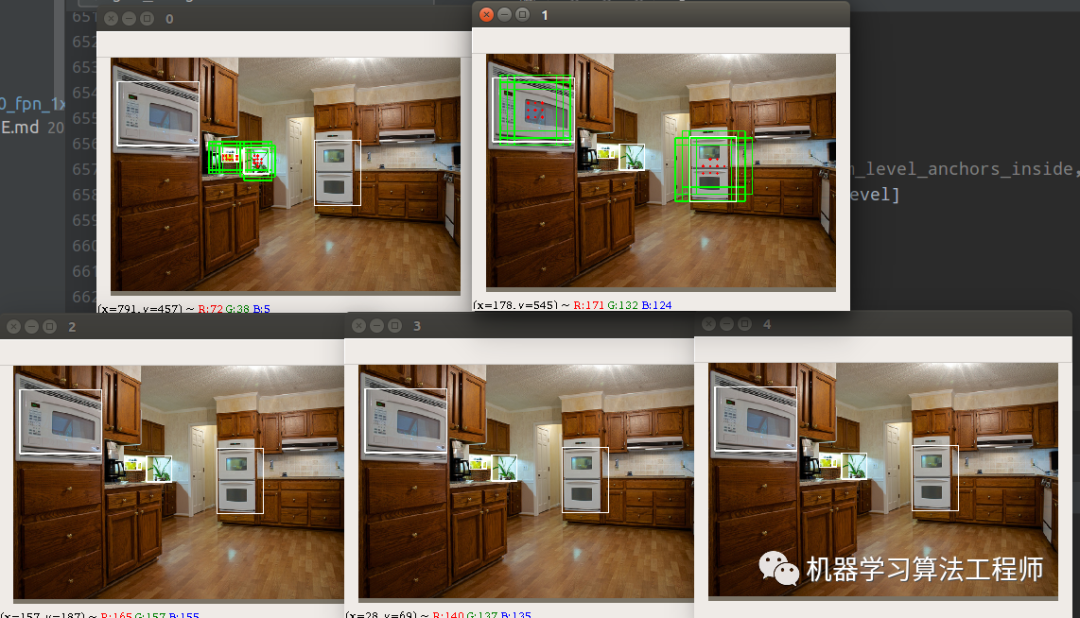
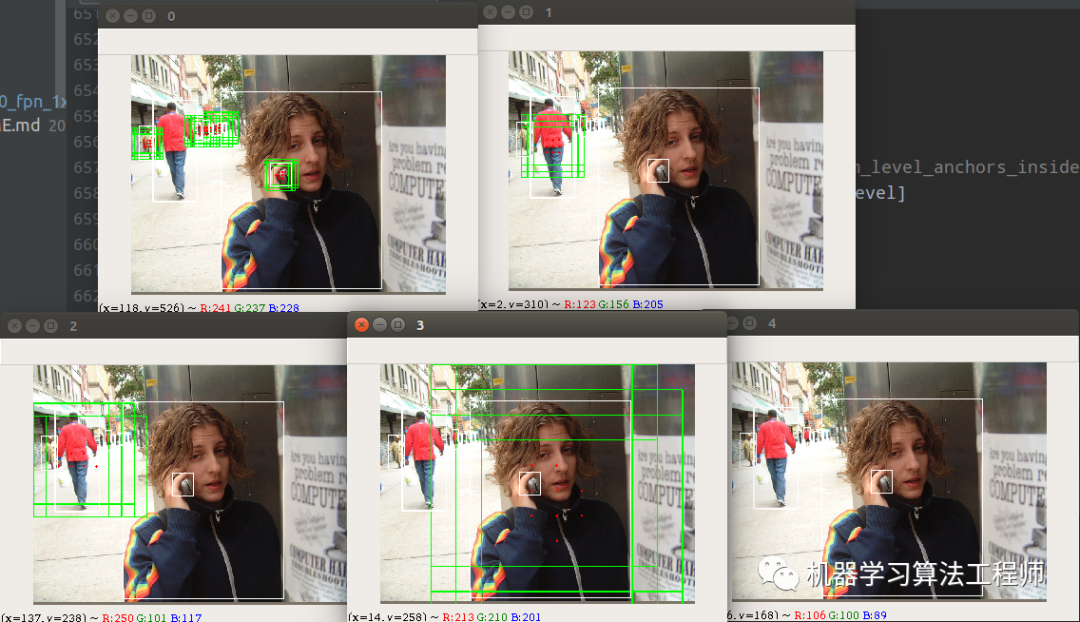
从0-4分别代表stride从小到大的预测层,分别负责从小到大物体的检测。白色的gt bbox,红色点是正样本点,绿色是anchor size,对于fcos来说实际训练时候是不需要的,这里仅仅是为了好看而已。看起来其自适应规则还是蛮不错的,不仅正样本数比较多,而且正样本点都是在物体中心点附近。
在topk=9时候,随机统计结果如下:
单张图片中正样本anchor个数 56单张图片中正样本anchor个数 153单张图片中正样本anchor个数 18单张图片中正样本anchor个数 28单张图片中正样本anchor个数 37单张图片中正样本anchor个数 9单张图片中正样本anchor个数 15单张图片中正样本anchor个数 9单张图片中正样本anchor个数 27单张图片中正样本anchor个数 195单张图片中正样本anchor个数 9单张图片中正样本anchor个数 78单张图片中正样本anchor个数 68
在topk=3时候,随机统计结果如下:
单张图片中正样本anchor个数 6单张图片中正样本anchor个数 90单张图片中正样本anchor个数 12单张图片中正样本anchor个数 3单张图片中正样本anchor个数 22单张图片中正样本anchor个数 8单张图片中正样本anchor个数 13单张图片中正样本anchor个数 9单张图片中正样本anchor个数 6单张图片中正样本anchor个数 21单张图片中正样本anchor个数 53单张图片中正样本anchor个数 35
相对正样本数量会少很多。topk参数设置原则应该是在不要引入大量低质量回归正样本的前提下应该尽量提高该阈值。
4 代码实现细节
4.1 训练模式
前面说过atss自适应分配策略可以作用于anchor-base和anchor-free,在mmdet框架中复现的是retinanet模式,也就是说整个ATSS算法实现采用的是style='pytorch',retinanet训练模式(注意fcos是caffe模式),此时anchor的设置就必不可少了(不仅要用于自适应计算正样本,还需要用于变换预测),并且FPN层采用的是fcos中用的P5下采样模式,而不是原始retinanet中的C5下采样模式。
4.2 anchor设置
在retinanet算法中,为了在自适应统计正负样本阶段能够计算iou,需要设置anchor,并且参与训练,配置如下所示:
anchor_generator=dict(type='AnchorGenerator',ratios=[1.0],octave_base_scale=8,scales_per_octave=1,strides=[8, 16, 32, 64, 128]),
意思是每个特征图仅仅设置一个尺度的anchor,且anchor大小是strides * octave_base_scale,从上面的可视化分析图中也可以看出。
4.3 centerness分支
该分支和fcos一样,也是挂在bbox回归分支,其余设置和fcos完全相同即分类分支是focal loss;回归分支是giou loss;centerness分支是bce loss。
bbox回归分支的target是anchor和gt bbox的变换值,如下所示:
bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[.0, .0, .0, .0],target_stds=[0.1, 0.1, 0.2, 0.2]),
如果是fcos模式,那么bbox回归分支的target应该是特征图上面点距离4条边的距离。
再次贴一下框架github地址:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
推荐阅读
mmdetection最小复刻版(二):RetinaNet和YoloV3分析
机器学习算法工程师
一个用心的公众号
