
揭示世界本质的「机器科学家」,比深度神经网络还强?

来源:AI科技评论 本文约5800字,建议阅读10分钟 机器科学家能够发现一些我们没有发现的东西。




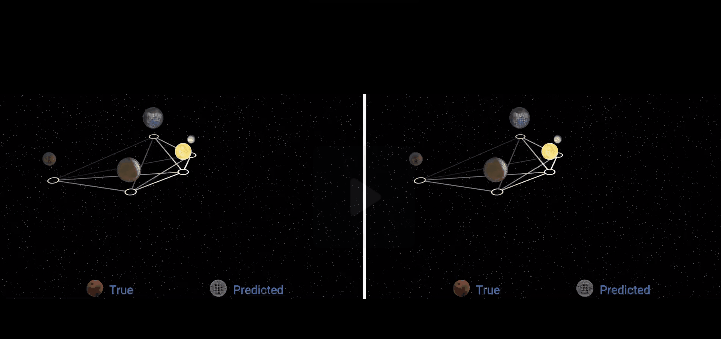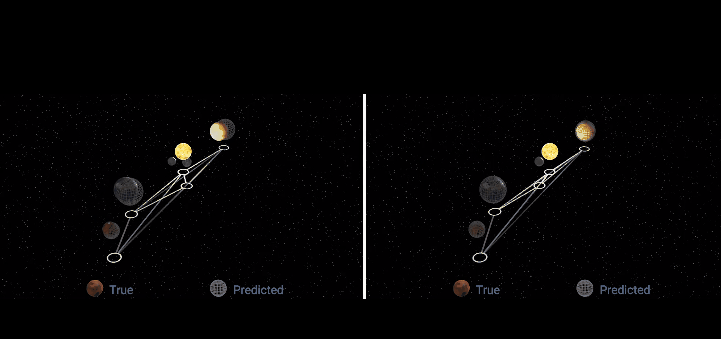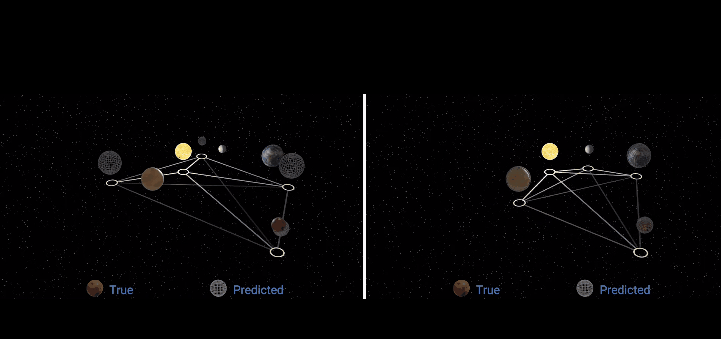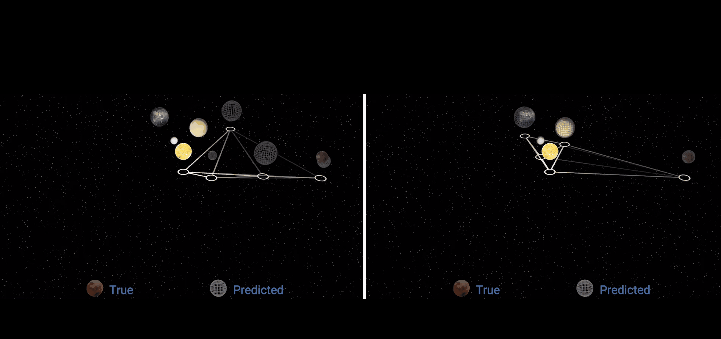

论文地址:
https://www.science.org/doi/10.1126/sciadv.aay2631

论文链接:
https://arxiv.org/abs/2112.10755
参考链接:
https://www.quantamagazine.org/machine-scientists-distill-the-laws-of-physics-from-raw-data-20220510/
https://www.icrea.cat/Web/ScientificStaff/roger-guimera-manrique-512
Marta Sales-Pardo (0000-0002-8140-6525)
Hod Lipson
https://www.science.org/doi/10.1126/science.1165893
https://laurezanna.github.io/
评论