
图谱讲义 | 第一讲-第4节-知识图谱的技术内涵
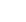
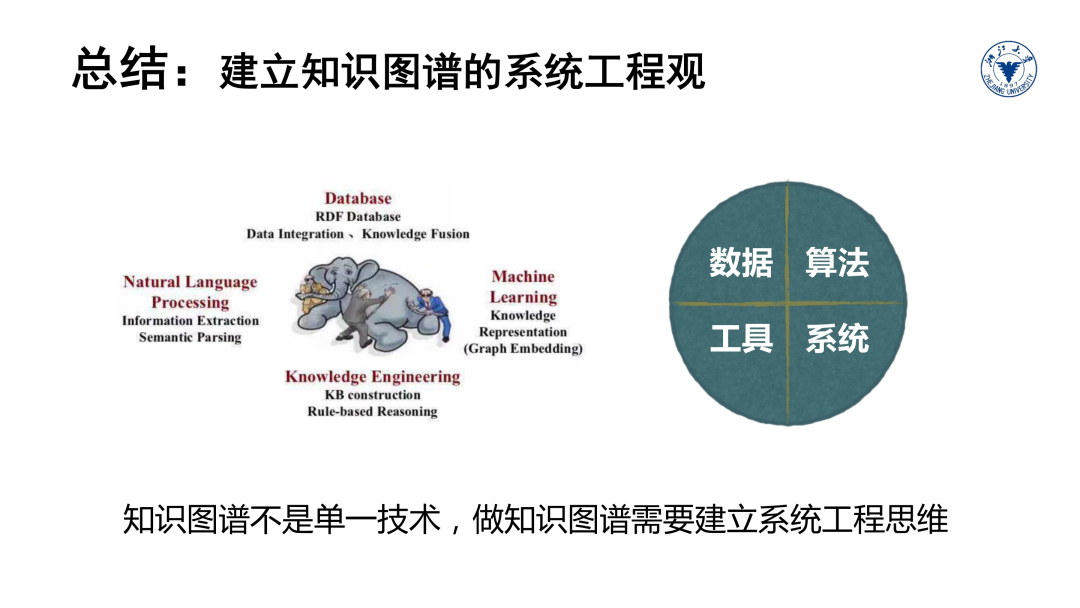
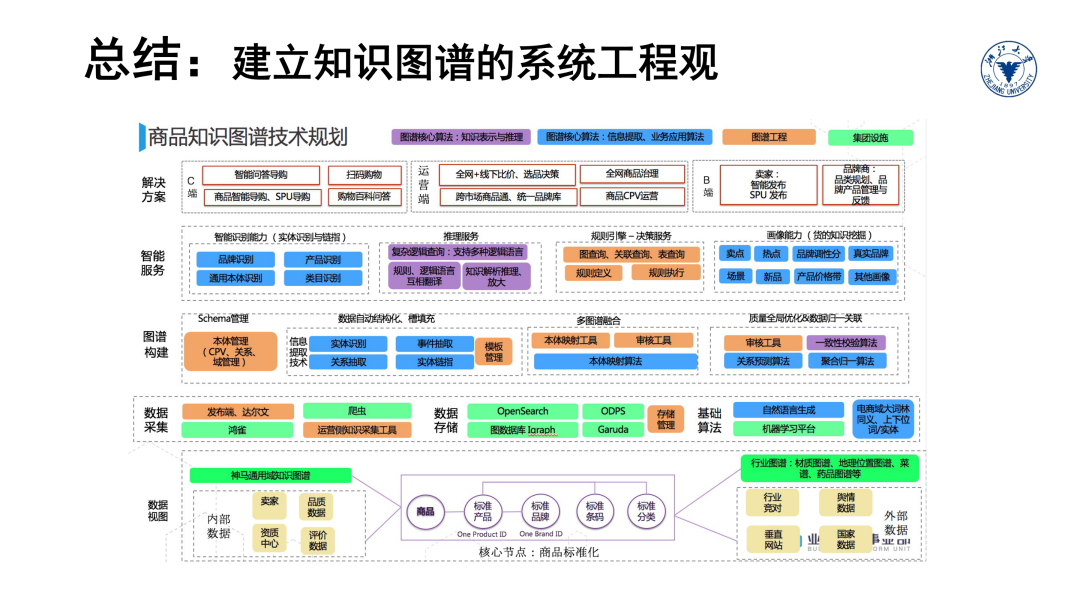
本讲义系列主要整理自浙江大学《知识图谱导论》(浙江省优秀研究生课程)的课程讲义。作为一门导论性质课程,该课程希望帮助初学者梳理知识图谱基本知识点和关键技术要素,帮助技术决策者建立知识图谱的整体视图和系统工程观,帮助前沿科研人员拓展创新视野和研究方向。
本次推文主要介绍讲义的“第一讲 知识图谱概论 第4节 知识图谱的技术内涵”,更多相关内容请点击上方“话题”或文末“往期推荐”。

我们首先要强调的是知识图谱是典型的交叉技术领域。从人工智能的视角,传统符号知识表示是知识图谱的重要基础技术,同时深度学习、表示学习等领域与知识图谱的交叉产生了知识图谱嵌入、可微知识图谱推理等交叉领域。
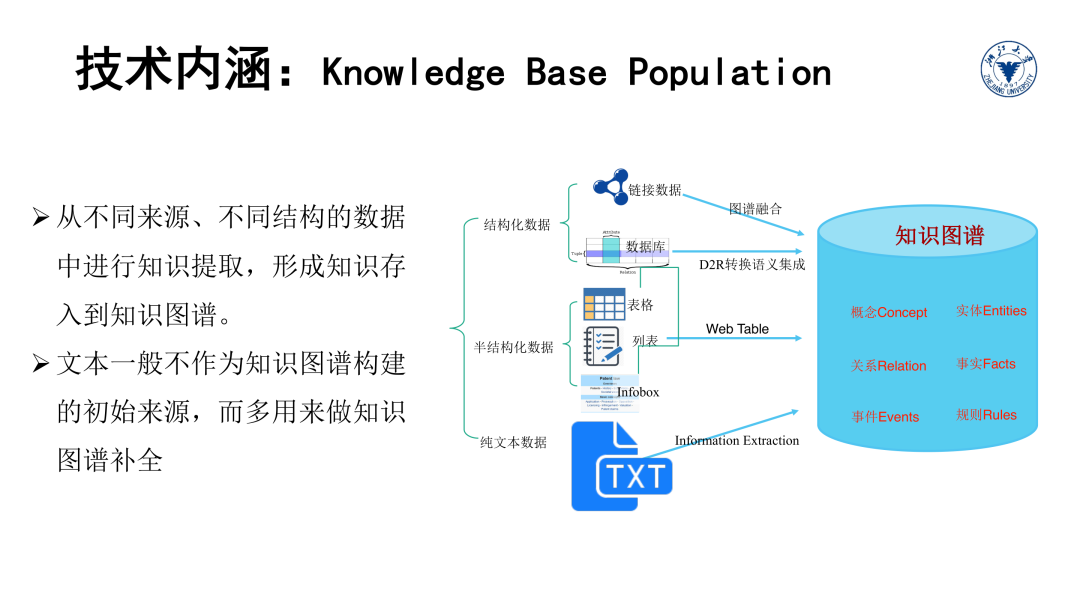
在传统的NLP领域,怎样从文本自动化识别实体、抽取关系、检测事件等信息一直是经久不衰的研究热题,Knowledge Base Population即是知识图谱与NLP之间产生的交叉领域。从数据库领域看,知识图谱与数据库的交叉又产生了图数据库,而图嵌入、图挖掘等数据挖掘领域的方法也广泛的被用来处理知识图谱数据。
同时,知识图谱也具有互联网基因,其最早的商业落地应用即是搜索引擎,因此在互联网和信息获取等领域的顶会中也会看到很多知识图谱相关的学术论文。此外,计算机视觉、物联网、区块链等领域也都能时常见到知识图谱的身影。知识图谱鲜明的交叉特征也表明它实际居于计算机领域非常核心的位置。
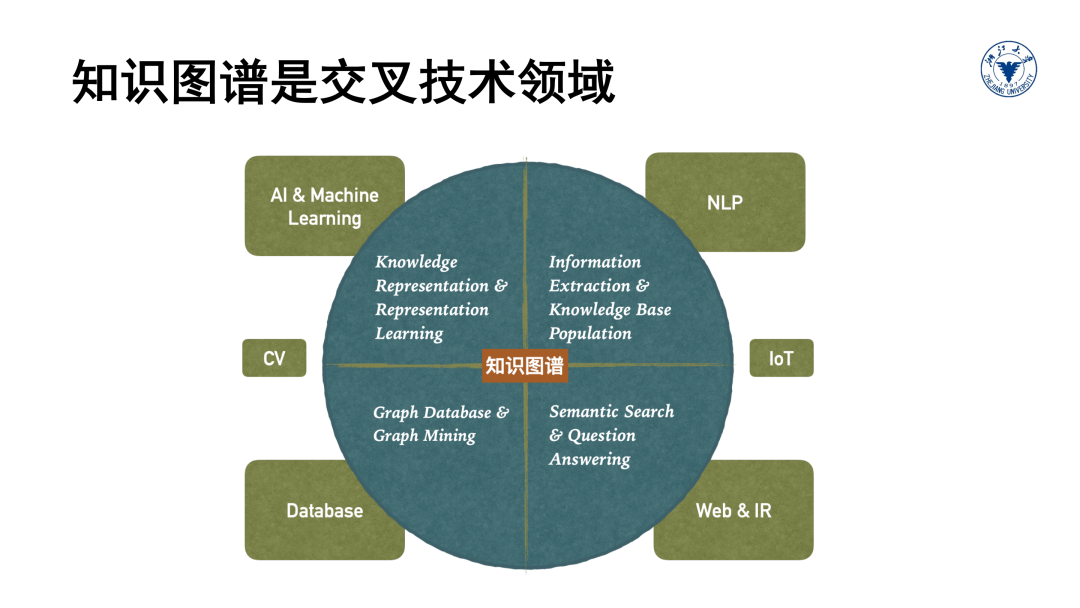
知识图谱的交叉特征导致知识图谱相关技术点繁多,但知识图谱始终有两个比较核心的技术基因。
第一个是从知识即Knowledge的视角,这来源于传统AI的知识表示与推理领域,我们关心怎么表示概念和实体,怎样刻画它们之间的关系,怎样进一步表示Axiom、Rules等更加复杂的知识,随着深度学习的兴起,怎样利用向量来表示实体和关系产生了KG Embedding的技术领域,怎样利用神经网络来实现逻辑推理产生了Neural Symbolic Reasoning等新技术领域。
第二个视角是从图的视角,这来源于知识图谱的互联网基因,我们关心图中的节点、边、路径、子图结构,怎样存储大规模的图数据,怎样利用图的结构对图数据进行推理、挖掘与分析等等。Knowledge Graph一方面比Pure Graph表达能力更强,因而能建模和解决更加复杂的问题,另外一方面又比传统知识表示所采用的formal logic要简单,同时容忍知识中存在噪音,构建过程更加容易扩展,因此得到了更为广泛的认可和应用。

进一步细分,知识图谱涉及的技术要素可以分为表示、存储、抽取、融合、推理、问答、分析等七个方面,例如,从表示的维度,涉及最基本的属性图表示和RDF图模型,以及更复杂知识的OWL本体表示和规则知识建模。
从存储的维度,涉及怎样利用已有的关系数据库来存储知识图谱,也涉及性能更高的原生图存储,图查询语言等。
从抽取的维度,涉及怎样从文本中抽取概念、识别实体、以及抽取三元组和事件等更为复杂的结构化知识。
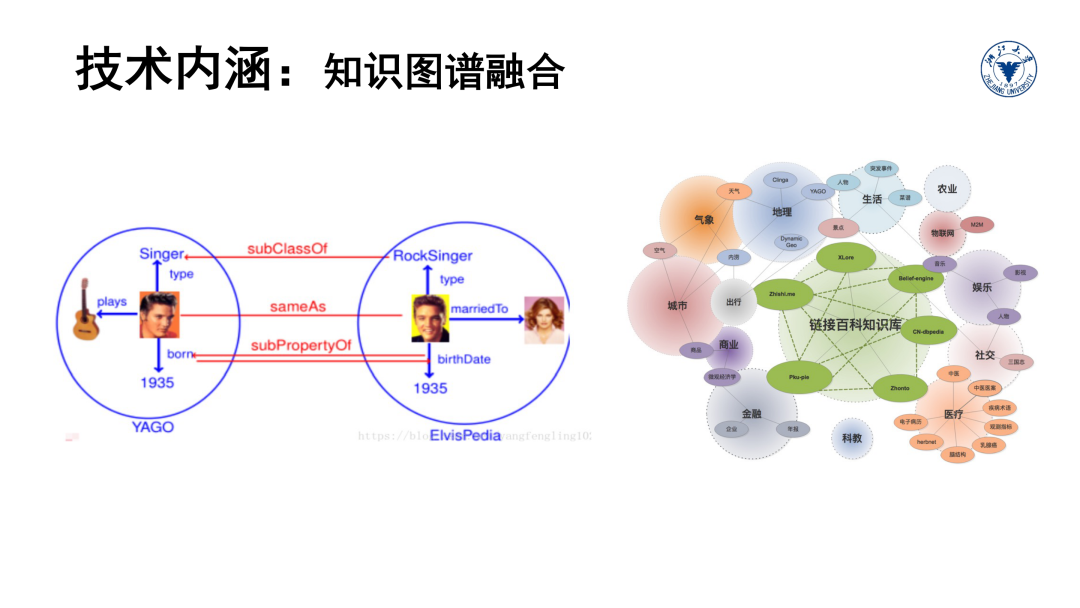
从融合的角度,涉及怎样实现本体层的概念映射,以及实例层的实体对齐等技术。
从推理的角度,涉及基于传统符号逻辑的推理技术,以及新兴的基于表示学习和神经网络的推理技术。
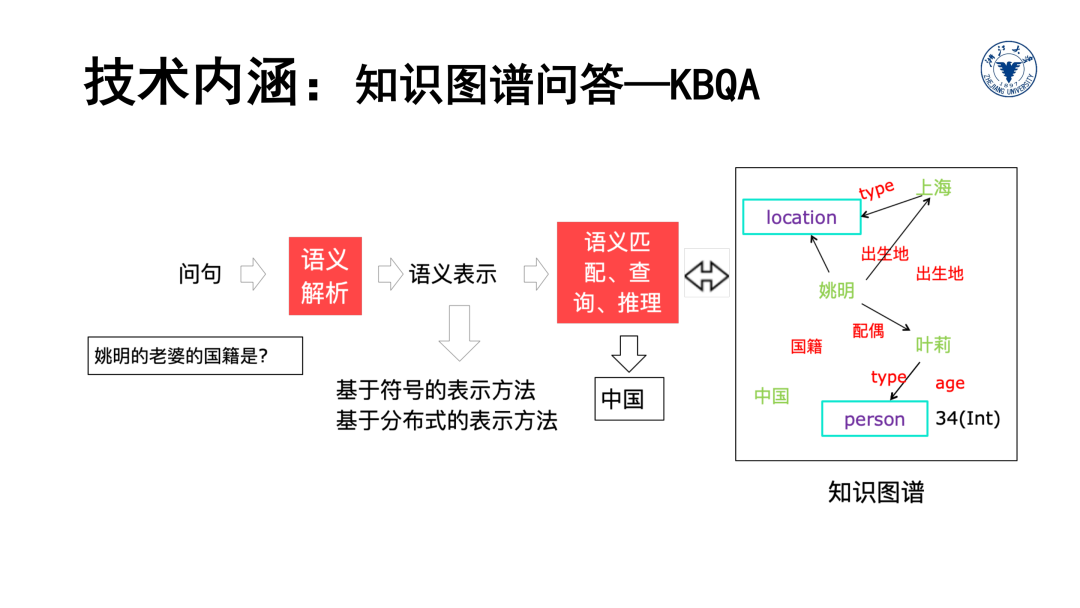
从问答的角度,涉及怎样正确理解问句、匹配答案和生成问答结果。
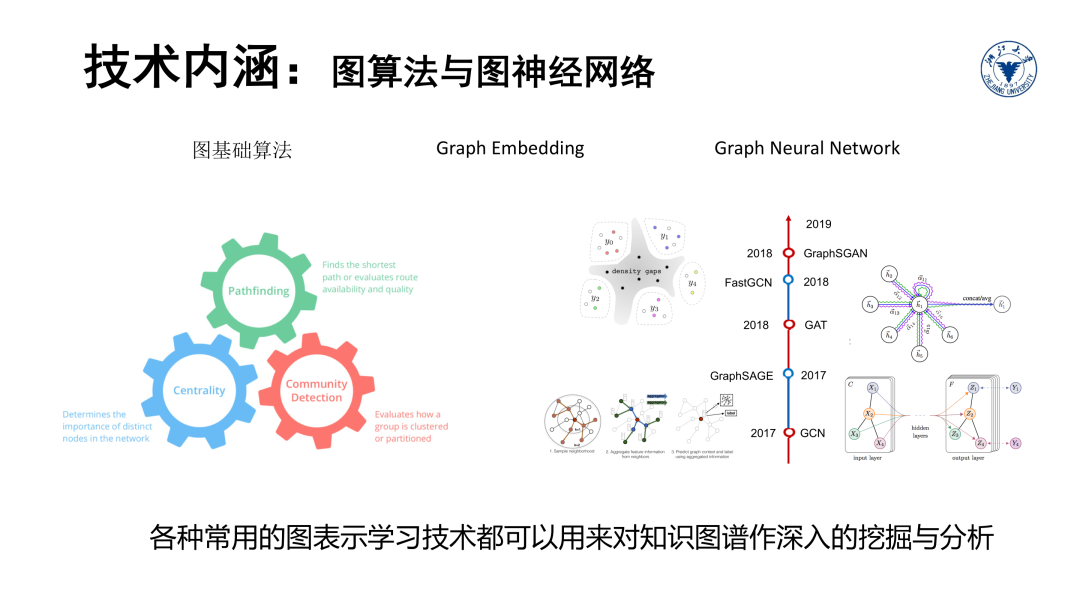
从分析的角度,涉及图算法,利用图嵌入、图神经网络等技术对知识图谱数据进行深度挖掘和分析等。
其它还包括知识图谱的众包技术,在CV领域的Scene Graph的构建,以及Semantic IoT等等。在后面的课程中,我们尝试对这些繁多的技术要素进行系统性的梳理和初步的介绍。当然,在解决一个实际问题时,通常仅需要用到其中若干技术的组合,但对它们进行整理的了解和全面把握对于我们提出系统的解决方案会有很大帮助。
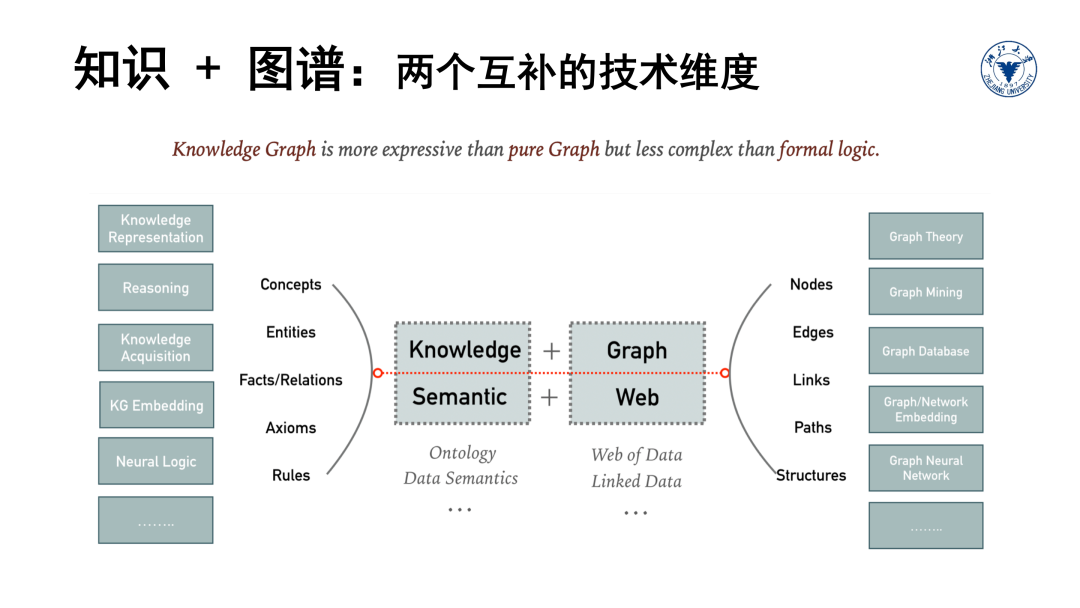
接下来,我们对各个技术维度做一个概览性的介绍,后面每一个技术维度都会有一个单独章节对应具体介绍。首先我们来看表示。最常用的知识图谱表示方法有属性图和RDF图两种。这两种表示方法都基于一个共同的图模型——即有向标记图,知识图谱就是基于有向标记图的知识表示方法。我们以RDF图模型为例来具体介绍。
知识图谱的最基本组成单元是三元组,一个三元组包含(Subject,Predicate,Object)三个部分,即主语、谓语、宾语。例如,浙江大学 位于杭州就可以简单的用一个三元组来表示。一条三元组代表了对客观世界某个逻辑事实的陈述。这些三元组头尾相互连接就形成了一张描述万物关系的图谱。
从这个角度来看,三元组实际上是最简单,而且最接近于人的自然语言的数据模型,而图的信息组织方式又更加接近于人脑的记忆存储方式。当然,三元组的表达能力也是有限的,在后面的章节中我们还会介绍更加复杂的知识,比如本体公理、规则逻辑等应该怎么建模和表示。
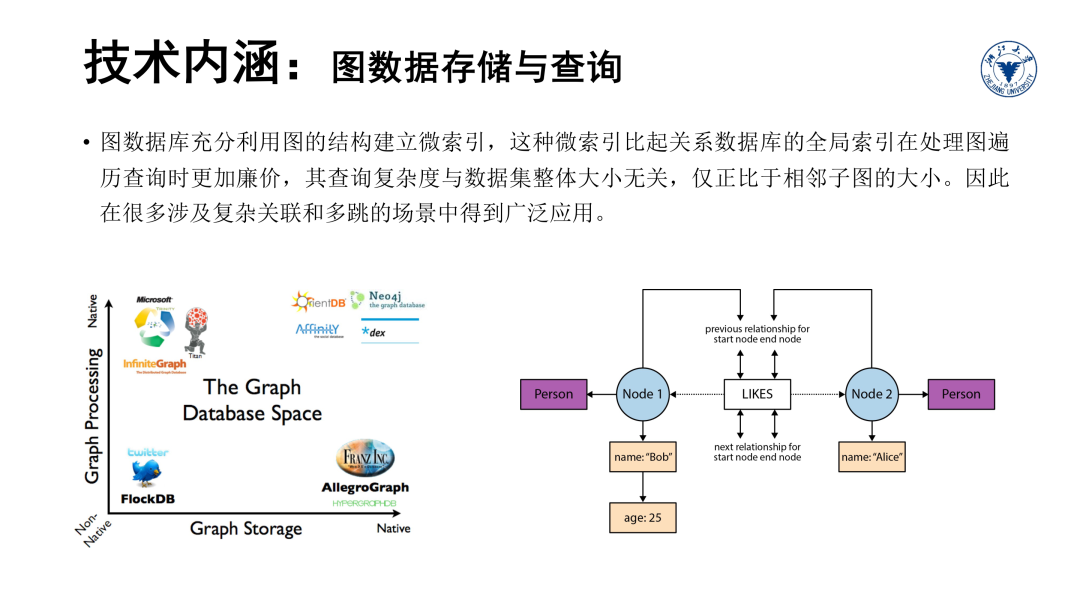
接下来介绍第二个技术维度——存储。图数据库充分利用图的结构建立微索引,这种微索引比起关系数据库的全局索引在处理图遍历查询时更加廉价,其查询复杂度与数据集整体大小无关,仅正比于相邻子图的大小。
因此在很多涉及复杂关联和多跳的场景中得到广泛应用。这里需要说明的是,图数据库并非知识图谱存储的必选方案,在后面的章节中,我们会介绍常见的知识图谱存储的各种解决方案。
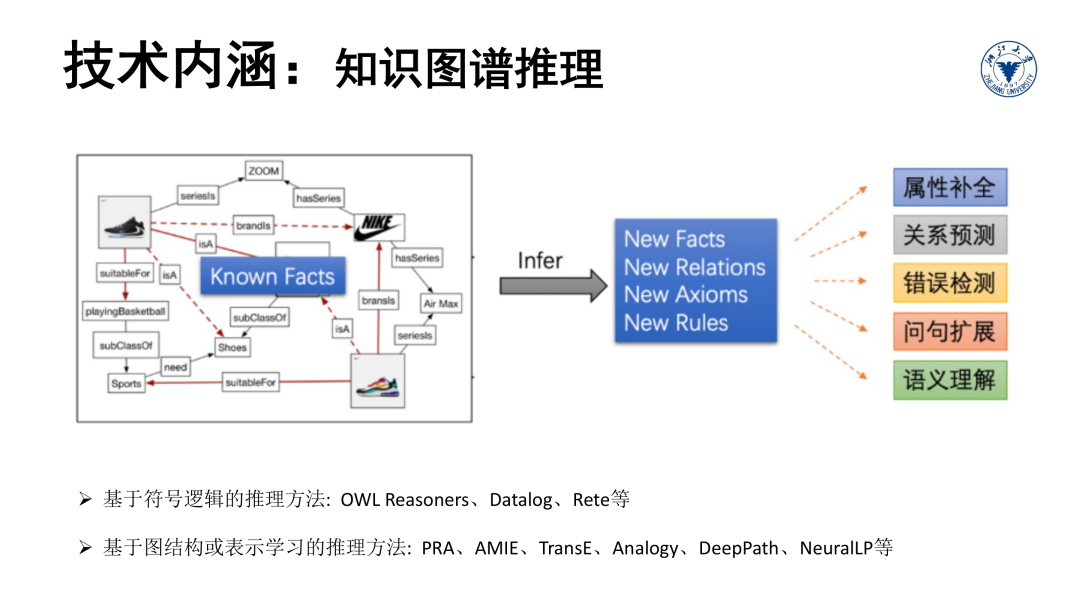
推理是知识图谱的核心技术和任务。简而言之,知识图谱推理的目标是利用图谱中已经存在的关联关系或事实来推断未知的关系或事实,在知识图谱的各项应用任务中发挥着重要作用。
如图所示,推理可以用来实现链接预测、补全缺失属性、检测错误描述和识别语义冲突,以提升图谱质量等;在查询和问答中,推理可以用来拓展问句语义和提高查询召回;在推荐计算中,推理可用来提升推荐的精准性和可解释性。此外,推理在深度语言语义理解和视觉问答中也扮演必不可少的角色。
凡是包含深度语义理解的任务都会涉及推理的过程。当前在知识图谱上实现推理大致可以分为基于符号逻辑的方法和基于表示学习的方法两类。传统基于符号逻辑的方法主要优点是具备可解释性,主要缺点是不易于处理隐含和不确定的知识;基于表示学习的方法主要优点是推理效率高且能表征隐含知识,主要缺点是丢失可解释性。在推理的章节中,我们将展开具体的介绍。
# 最佳论文奖 | “联邦知识图谱表示学习”获IJCKG国际知识图谱联合会议Best Paper Award
# AAAI2022 | KCL: 化学元素知识图谱指导下的分子图对比学习

浙江大学知识图谱创新研究团队