
2020年,那些已经死亡的公司

文 | 某某白米饭
来源:Python 技术「ID: pythonall」

大家都知道 2020 年因为新冠疫情的原因,有些公司为了生存下去做了降薪、裁员、加班等一系列动作,还有一部分公司直接死亡了,大家一起来看看吧。
登录
数据来源于 IT 桔子网站的死亡公司公墓(https://www.itjuzi.com/deathCompany),IT桔子网站访客只能看到 1 页数据,需要注册登录才能看到更多的数据,首先注册一个账号登录,在登录页(https://www.itjuzi.com/login)用 F12 找到登录表单,selenium 模块模拟用户登录。
def login():
driver = webdriver.Chrome()
driver.get('https://www.itjuzi.com/login')
driver.implicitly_wait(10)
driver.find_element_by_xpath('//form/div[1]/div/div[1]/input').clear()
driver.find_element_by_xpath('//form/div[1]/div/div[1]/input').send_keys('用户名')
driver.find_element_by_xpath('//form/div[2]/div/div[1]/input').clear()
driver.find_element_by_xpath('//form/div[2]/div/div[1]/input').send_keys('密码')
driver.find_element_by_class_name('el-button').click()
driver.switch_to.default_content()
time.sleep(5)
return driver
抓取数据
模拟鼠标从首页导航栏的公司库到死亡公司连接的跳转,只抓取 2020 年的数据,大概有 100 页左右。把抓取的数据存放在 csv 文件中。
def link(driver):
ActionChains(driver).move_to_element(driver.find_elements_by_class_name('more')[0]).perform() # 把鼠标移到公司库导航上面
driver.find_element_by_link_text('死亡公司').click() # 点击死亡公司超链接
driver.switch_to.window(driver.window_handles[1]) # 切换到新开的标签页
driver.implicitly_wait(10)
time.sleep(5)
def crawler(driver):
next_page=driver.find_element_by_class_name('btn-next') #下一页
# 只抓 2020 年的数据
for page in range(1, 101):
result = []
deadCompany = driver.find_element_by_tag_name("tbody").find_elements_by_tag_name("tr")
num = len(deadCompany)
for i in range(1,num + 1):
gsjc = deadCompany[i - 1].find_element_by_xpath('td[3]/div/h5/a').text # 公司简称
chsj = deadCompany[i - 1].find_element_by_xpath('td[3]/div/p').text # 存活时间
gbsj = deadCompany[i - 1].find_element_by_xpath('td[4]').text # 关闭时间
hy = deadCompany[i - 1].find_element_by_xpath('td[5]').text # 所属行业
dd = deadCompany[i - 1].find_element_by_xpath('td[6]').text # 公司地点
clsj = deadCompany[i - 1].find_element_by_xpath('td[7]').text # 关闭时间
htzt = deadCompany[i - 1].find_element_by_xpath('td[8]').text # 融资状态
result.append(','.join([gsjc, chsj, gbsj, hy, dd, clsj, htzt]))
with open('itjuzi/deadCompany.csv', 'a') as f:
f.write('\n'.join('%s' % id for id in result)+'\n')
print(result)
print("第 %s 页爬取完成" % page)
next_page.click() # 点击下一页
time.sleep(random.uniform(2, 10))
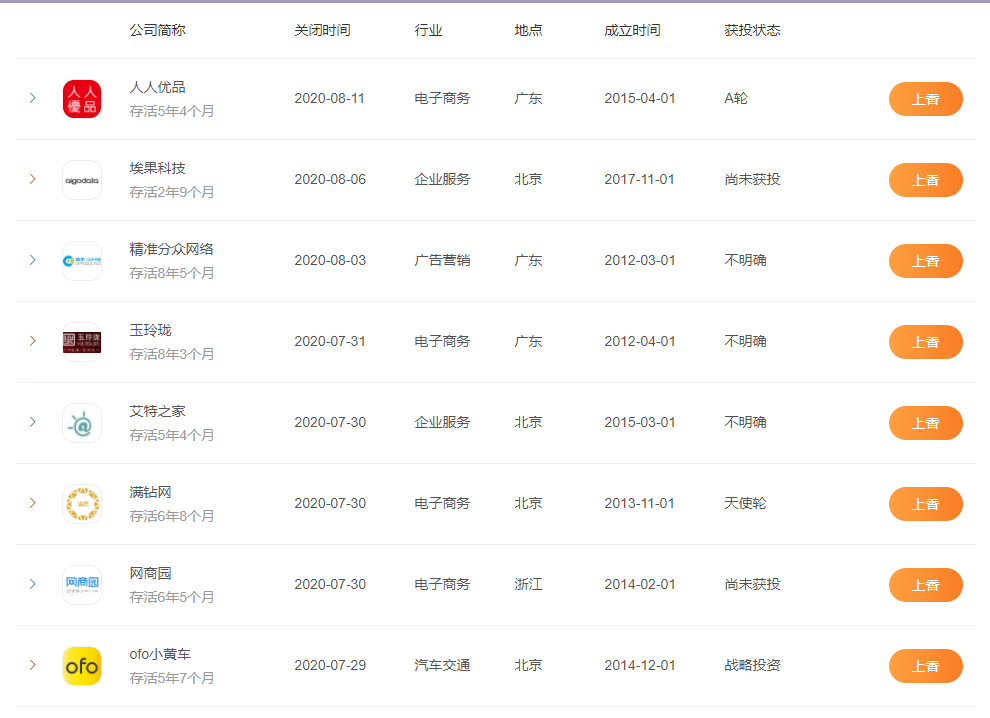
示例截图:
图表
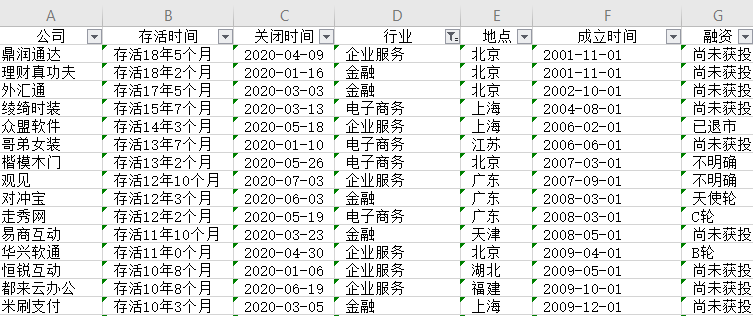
我们已经把死亡公司数据放在了 csv 文件中,先解析到内存并使用 pyecharts 模块制成图表。
def parse_csv():
deadCompany_list = []
with open('itjuzi/deadCompany.csv', 'r') as f:
for line in f.readlines():
a = line.strip()
deadCompany_list.append(a)
return deadCompany_list
从存活时长年限来看有 64% 的公司都没有超过 4 年,有 4% 存在了超过 10 年的老牌公司也在今年关停了。
def lifetime_pie(deadCompany_list):
lifetime_dict = {}
for i in deadCompany_list:
info = i.split(',')
lifetime = info[1].replace('存活', '').split('年')[0]
if int(lifetime) >= 10:
lifetime = '>=10'
lifetime_dict[lifetime] = lifetime_dict.get(lifetime, 0) + 1
(
Pie()
.add("", [list(z) for z in zip(lifetime_dict.keys(), lifetime_dict.values())],
radius=["40%", "75%"], )
.set_global_opts(
title_opts=opts.TitleOpts(
title="公司存活年限",
pos_left="center",
pos_top="20"),legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"), )
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"), )
.render("存活时间.html")
)
示例截图:

在融资方面没有融资的公司死亡率在 75%,融资的公司死亡率是 23%,前者是后者的 3.2 倍
def rongzi_pie(deadCompany_list):
rongzi_dict = {}
norongzi_list = ['尚未获投', '不明确', '尚未获']
rongzi_list = ['天使轮', 'A轮', 'B轮', 'C轮', 'D轮', 'E轮', 'D+轮', '种子轮', 'A+轮', '新三板', '战略投资', 'B+轮', 'Pre-A轮']
for i in deadCompany_list:
info = i.split(',')
rongzi = info[6].strip()
if rongzi in norongzi_list:
rongzi = '没有融资'
elif rongzi in rongzi_list:
rongzi = '已融资'
rongzi_dict[rongzi] = rongzi_dict.get(rongzi, 0) + 1
(
Pie()
.add("", [list(z) for z in zip(rongzi_dict.keys(), rongzi_dict.values())],
radius=["40%", "75%"], )
.set_global_opts(
title_opts=opts.TitleOpts(
title="融资情况",
pos_left="center",
pos_top="20"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"), )
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"), )
.render("融资情况.html")
)
示例截图:

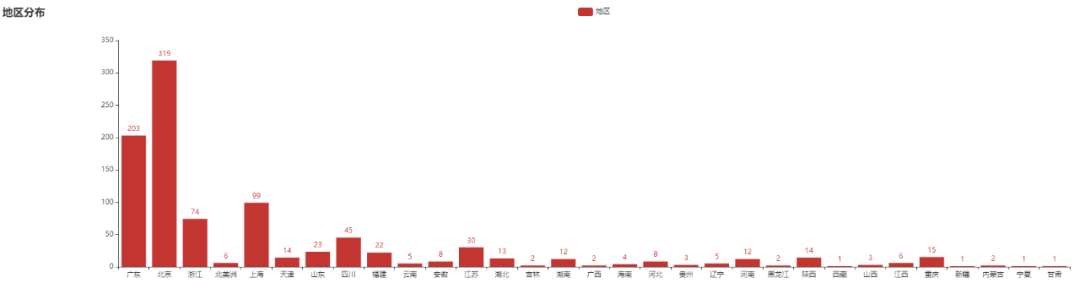
从公司地区分布情况看,北上广的死亡公司数就占到了一半以上死亡了 621 家公司。
def place_bar(deadCompany_list):
place_dict = {}
for i in deadCompany_list:
info = i.split(',')
place = info[4].strip()
place_dict[place] = place_dict.get(place, 0) + 1
( Bar(init_opts=opts.InitOpts(width='2000px'))
.add_xaxis(list(place_dict.keys()))
.add_yaxis("地区", list(place_dict.values()), )
.set_global_opts(
title_opts=opts.TitleOpts(title="地区分布")
)
.render("地区.html")
)
示例截图:
总结
从死亡公司数据中得出创业并不是一件容易的事情,创业公司在前 4 年是最容易死亡的,在地区方面北上广超一线城市的公司竞争率是最高的。在融资方面获得融资的公司存活率远远大于没有融资的公司。大家在找工作的时候可以找存活年限长并且得到融资的公司。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】