
Flink 对线面试官(二):6k 字,8 个面试高频实战问题(没有实战过...
1.前言
本文主要是整理博主收集的 Flink 高频面试题。之后每周都会有一篇。
这一期的主题是 实战经验,这一期讲的内容其实是面试官非常看重的,为什么这么说呢?
因为这一期涉及到的几个问题,基本就能问出来候选人有没有实战经验了。
博主把这一期的面试题先贴出来,大家自己感受感受。
- ⭐ 解决问题的能力:生产环境中,如何快速判断哪个算子存在反压呢?
- ⭐ 解决问题的能力:反压有哪些危害?
- ⭐ 解决问题的能力:经常碰到哪些问题会任务反压?
- ⭐ 解决问题的能力:怎么缓解、解决任务反压的情况?
- ⭐ 数据保障的能力:实时数据延迟是怎么监控的?报警策略又是怎么制定的?
- ⭐ 数据保障的能力:通过什么样的监控及保障手段来保障实时指标的质量?
- ⭐ 原理理解:operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
- ⭐ 你认为以后 Flink SQL 的发展趋势是 unbounded 类 SQL 为主还是窗口类 SQL 为主?原因?
下面的答案都是博主收集小伙伴萌的答案 + 博主自己的理解进行的一个总结,博主认为是大家可以拿去细品的。
2.生产环境中,如何快速判断哪个算子存在反压呢?或者说哪个算子出现了性能问题?将这个问题拆解成多步来分析:
- ⭐ 如何知道算子是否有反压?
在 Flink web ui 中,定位到一个具体的算子之后,查看 BackPressure 模块,通过颜色和数值来判断任务的繁忙和反压情况。
若颜色为红色,表示当前算子繁忙,有反压的情况;若颜色为绿色,标识当前算子不繁忙,没有反压。
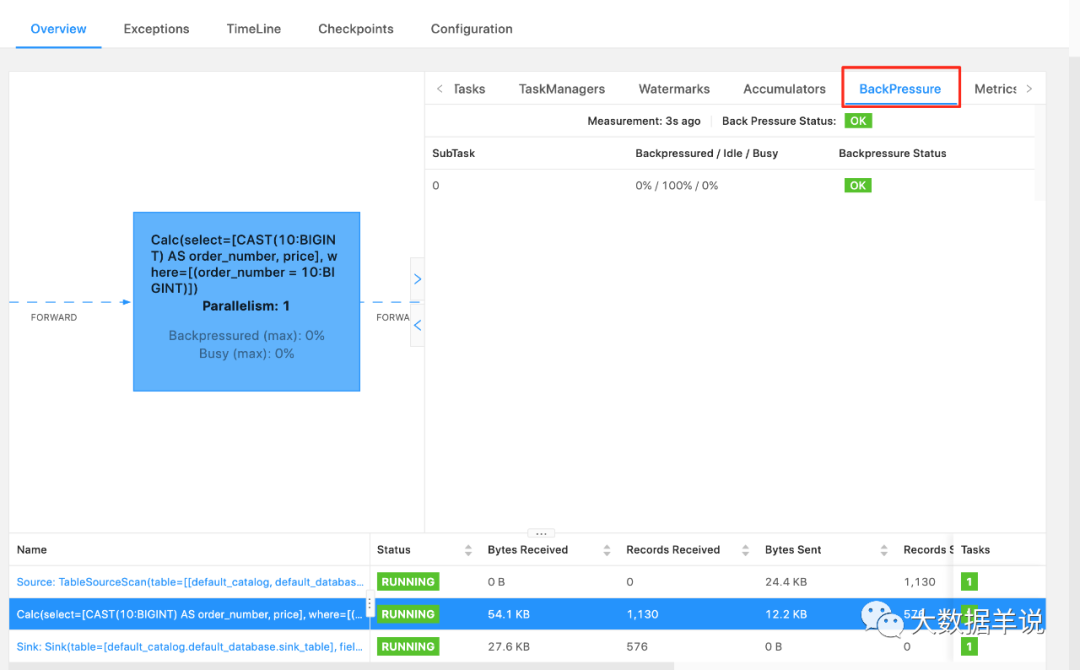
- ⭐ 举个实际 Flink 任务案例,这个 Flink 任务中有 Source、FlatMap、Sink 算子,如果 Source 算子有反压,那到底是哪个算子有性能问题呢?
上游算子在 web ui 显示有反压时,一般为下游算子存在性能问题。可以继续往下游排查,如果 FlatMap 也显示有反压,大概率是 Sink 算子存在性能问题;如果 FlatMap 没有显示有反压,大概率是 FlatMap 算子存在性能问题。
- ⭐ 大多数时候,Flink 会自动将算子 chain 在一起,那怎么判断具体是哪一个算子有问题?
第一种方式:Flink 提供了断开算子链的能力。
- ⭐ DataStream API 中:可以使用
disableChaining()将 chain 在一起的算子链断开。或者配置pipeline.operator-chaining: false
.process(xxx)
.uid("process")
.disableChaining() // 将算子链进行断开
.addSink(xxx)
.uid("sink");
- ⭐ SQL API 中:配置
pipeline.operator-chaining: false
CREATE TABLE source_table (
order_number BIGINT,
price DECIMAL(32,2)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.order_number.min' = '10',
'fields.order_number.max' = '11'
);
CREATE TABLE sink_table (
order_number BIGINT,
price DECIMAL(32,2)
) WITH (
'connector' = 'print'
);
insert into sink_table
select * from source_table
where order_number = 10;
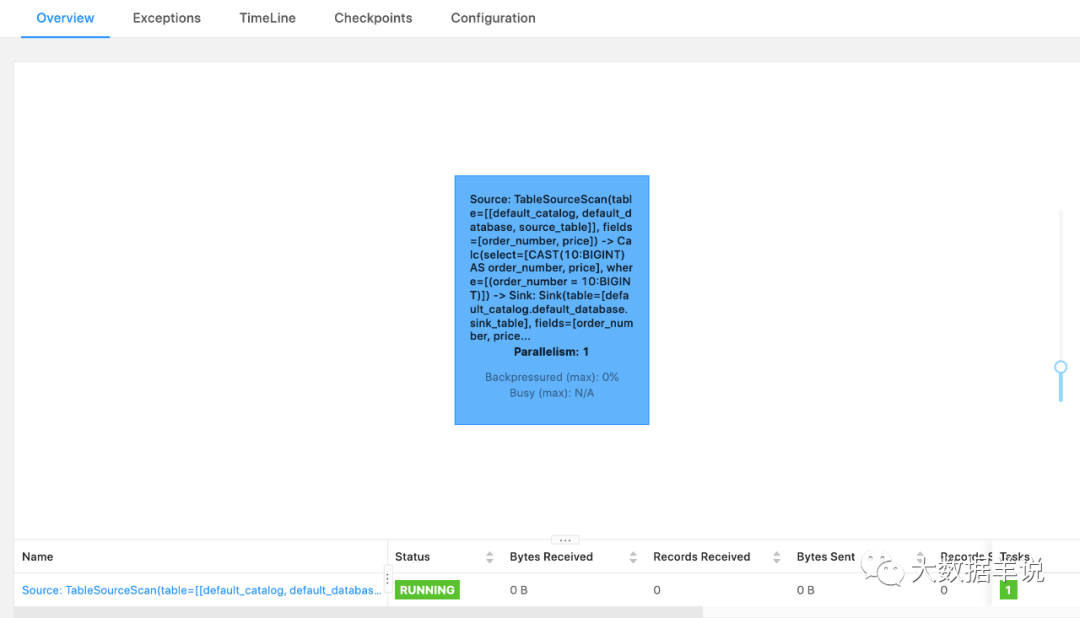
我们来看看一个 SQL 任务在配置 pipeline.operator-chaining: false 前后的差异。
在配置 pipeline.operator-chaining: false 前,可以看到所有算子都 chain 在一起:
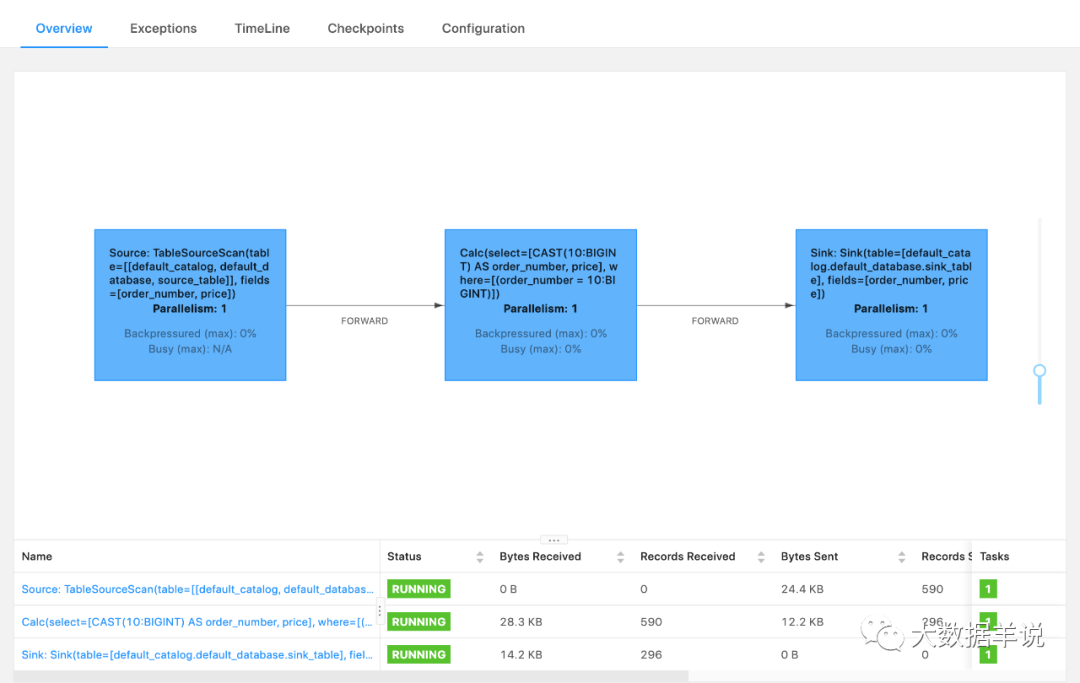
在配置 pipeline.operator-chaining: false 后,可以看到所有算子都没有 chain 在一起:
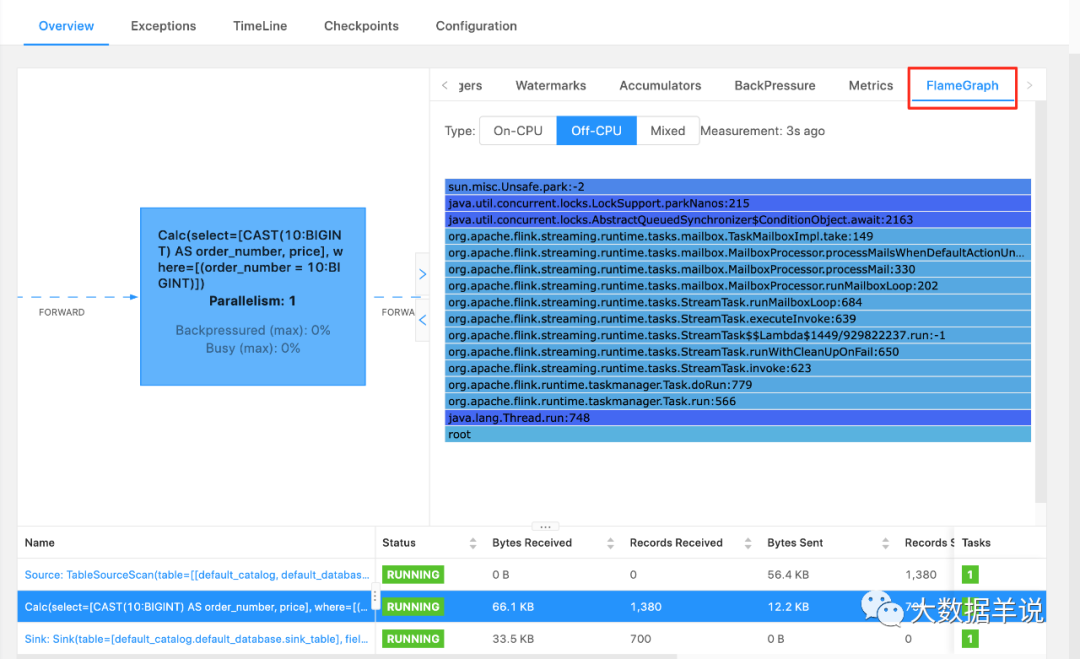
第二种方式:在 Flink 1.13 中,提供了火焰图,可以通过火焰图定位问题。火焰图需要配置 rest.flamegraph.enabled: true 打开
- ⭐ 任务处理性能出现瓶颈:以消费 Kafka 为例,大概率会出现消费 Kafka Lag。
- ⭐ Checkpoint 时间长或者失败:因为某些反压会导致 barrier 需要花很长时间才能对齐,任务稳定性差。
- ⭐ 整个任务完全卡住。比如在 TUMBLE 窗口算子的任务中,反压后可能会导致下游算子的 input pool 和上游算子的 output pool 满了,这时候如果下游窗口的 watermark 一直对不齐,窗口触发不了计算的话,下游算子就永远无法触发窗口计算了。整个任务卡住。
总结就是:算子的 sub-task 需要处理的数据量 > 能够处理的数据量。一般会实际中会有以下两种问题会导致反压。
- ⭐ 数据倾斜:当前算子的每个 sub-task 只能处理 1w qps 的数据,而由于数据倾斜,这个算子的其中一些 sub-task 平均算下来 1s 需要处理 2w 条数据,但是实际只能处理 1w 条,从而反压。比如有时候 keyby 的 key 设置的不合理。
- ⭐ 算子性能问题:下游整个整个算子 sub-task 的处理性能差,输入是 1w qps,当前算子的 sub-task 算下来平均只能处理 1k qps,因此就有反压的情况。比如算子需要访问外部接口,访问外部接口耗时长。
- ⭐ 事前:解决上述介绍到的
数据倾斜、算子性能问题。 - ⭐ 事中:在出现反压时:
- ⭐ 限制数据源的消费数据速度。比如在事件时间窗口的应用中,可以自己设置在数据源处加一些限流措施,让每个数据源都能够够匀速消费数据,避免出现有的 Source 快,有的 Source 慢,导致窗口 input pool 打满,watermark 对不齐导致任务卡住。
- ⭐ 关闭 Checkpoint。关闭 Checkpoint 可以将 barrier 对齐这一步省略掉,促使任务能够快速回溯数据。我们可以在数据回溯完成之后,再将 Checkpoint 打开。
几乎我问到的所有的小伙伴都能回到到 Flink 消费 Source 的 Lag 监控,我们可以把这个监控项升级一下,即 Kafka 到 Flink 延迟。原因如下:
以 Flink 消费 Kafka 为例,几乎所有的任务性能问题都最终能反映到 Kafka 消费 Flink 延迟,所以几乎 100% 的任务性能问题都能由 Kafka 到 Flink 延迟 这个监控发现。
大家可以没有其他监控手段,但是这一项非常建议搞。
当然也有小伙伴问,具体的实操时,监控项应该怎么设置呢?
很多小伙伴也回答到:Flink 本地时间戳 - Kafka 中自带的时间戳。
这时候有小伙伴提到,这个只能反映出 Flink 消费 Kafka 的延迟,那具体数据上的延迟怎么反映出来呢。
群里有小伙伴也回达到:Flink 本地时间戳 - 数据事件时间戳。
不说了,小伙伴萌都是 YYDS。
7.通过什么样的监控及保障手段来保障实时指标的质量?当我提出这个问题的时候。群里的小伙伴给出了建设性意见:
那就是:等着用户工单投诉。

但是在博主的正确引导之下,小伙伴萌走上了正轨。
这里总结群里小伙伴的一些意见,得出了一个大多数企业都可以 快速构建 实时数据质量保障体系,从 事前、事中、事后 x 任务层面、指标层面 进行监控、保障:
- ⭐ 事前:
- ⭐ 任务层面:根据峰值流量进行压力测试,并且留一定 buffer,用于事前保障任务在资源层面没有瓶颈
- ⭐ 指标层面:根据业务要求,上线实时指标前进行相同口径的实时、离线指标的验数,在实时指标的误差不超过业务阈值时,才达到上线要求
- ⭐ 事中:
- ⭐ 任务层面:贴源层监控 Kafka 堆积延迟等报警检测手段,用于事中及时发现问题。比如的普罗米修斯监控 Lag 时长
- ⭐ 指标层面:根据指标特点实时离线指标结果对比监控。检测到波动过大就报警。比如最简单的方式是可以通过将实时结果导入到离线,然后定时和离线指标对比
- ⭐ 事后:
- ⭐ 任务层面:对于可能发生的故障类型,构建用于故障修复、数据回溯的实时任务备用链路
- ⭐ 指标层面:构建指标修复预案,根据不同的故障类型,判断是否可以使用实时任务进行修复。如果实时无法修复,构建离线恢复链路,以便使用离线数据进行覆写修复
详细描述一下上面的问题:
operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
- ⭐ 总结如下:
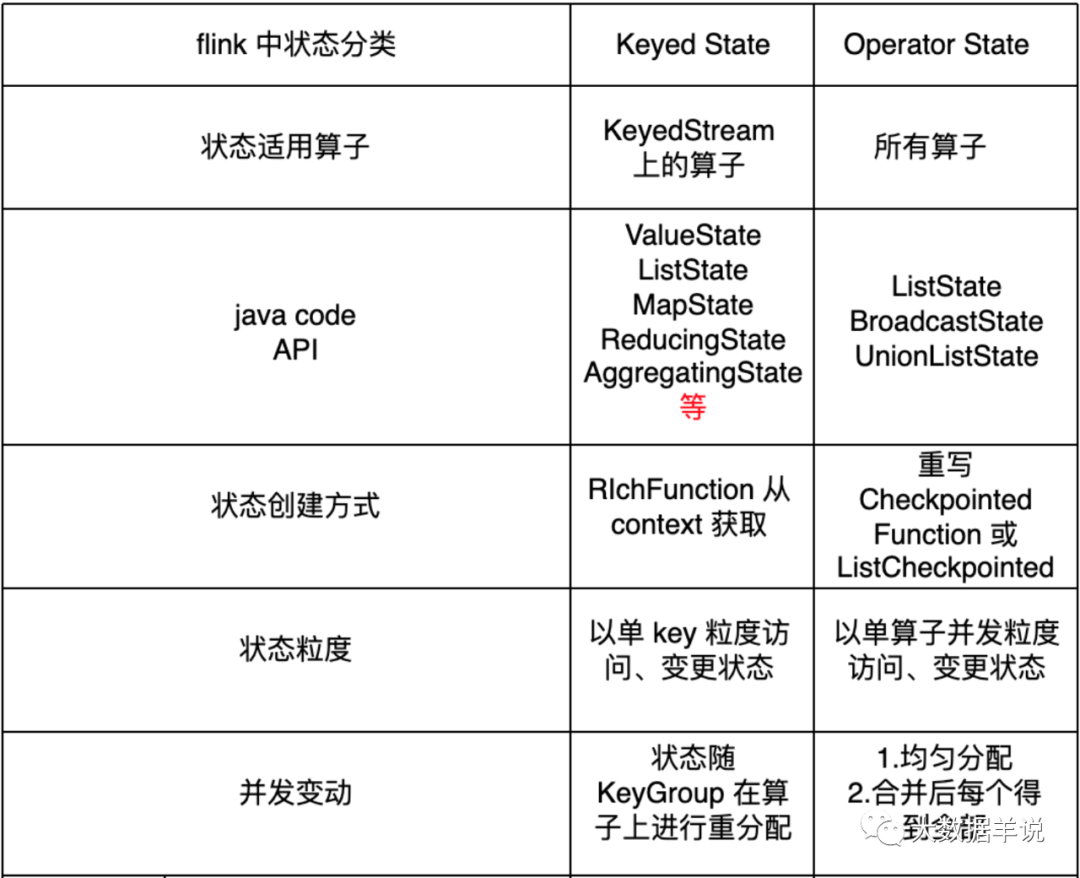
- ⭐ operator-state:
⭐ 状态适用算子:所有算子都可以使用 operator-state,没有限制。
⭐ 状态的创建方式:如果需要使用 operator-state,需要实现 CheckpointedFunction(建议) 或 ListCheckpointed 接口
⭐ DataStream API 中,operator-state 提供了 ListState、BroadcastState、UnionListState 3 种用户接口
⭐ 状态的存储粒度:以单算子单并行度粒度访问、更新状态
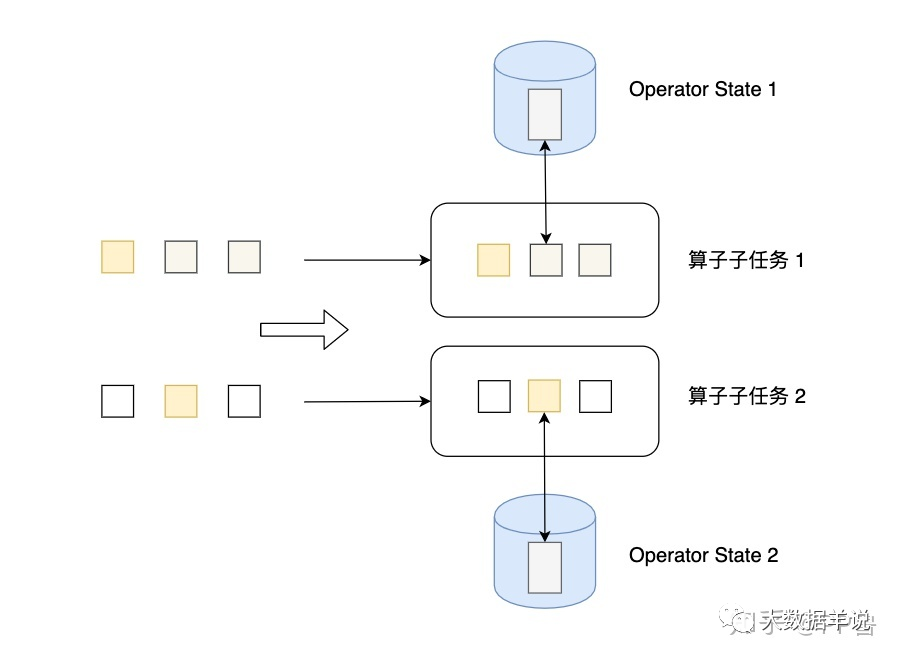
⭐ 并行度变化时:
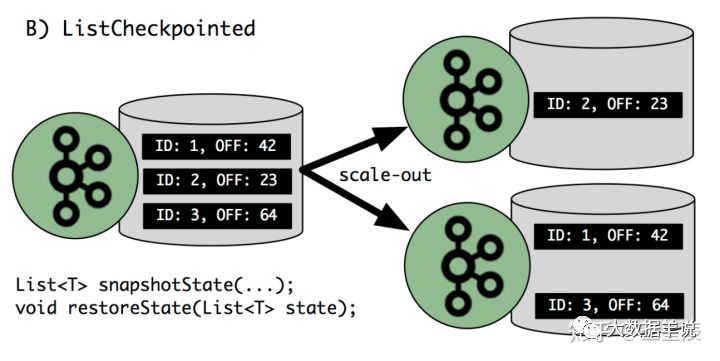
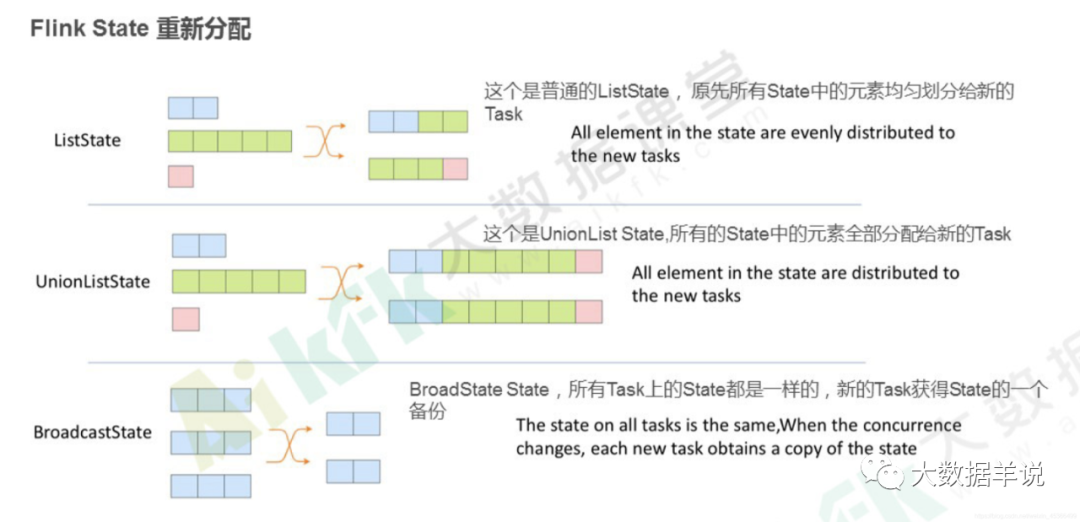
a. ListState:均匀划分到算子的每个 sub-task 上,比如 Flink Kafka Source 中就使用了 ListState 存储消费 Kafka 的 offset,其 rescale 如下图
 10
10b. BroadcastState:每个 sub-task 的广播状态都一样
c. UnionListState:将原来所有元素合并,合并后的数据每个算子都有一份全量状态数据
- ⭐ keyed-state:
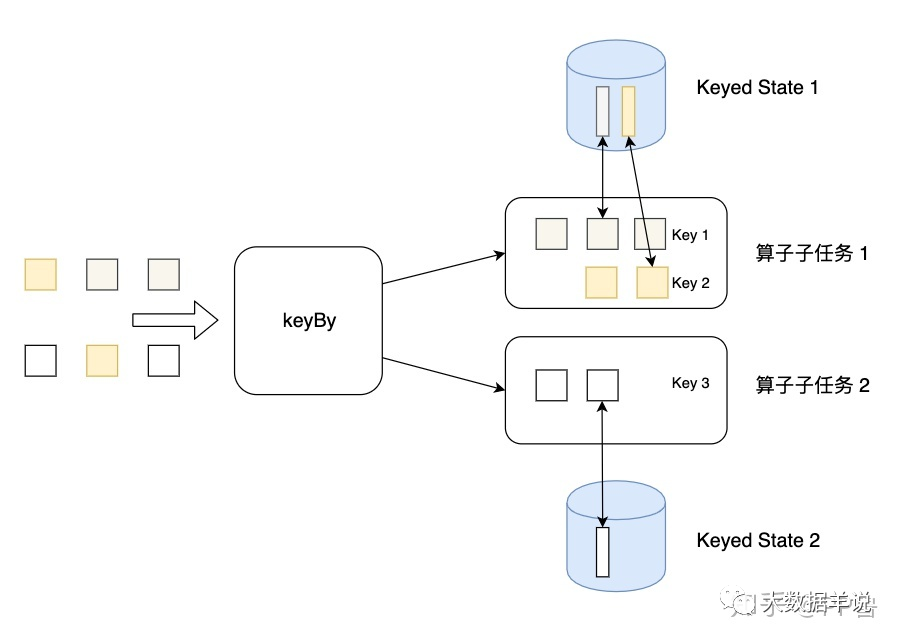
- ⭐ 状态适用算子:keyed-stream 后的算子使用。注意这里很多同学会犯一个错误,就是大家会认为 keyby 后面跟的所有算子都使用的是 keyed-state,但这是错误的 ❌,比如有 keyby.process.flatmap,其中 flatmap 中使用状态的话是 operator-state
- ⭐ 状态的创建方式:从 context 接口获取具体的 keyed-state
- ⭐ DataStream API 中,keyed-state 提供了 ValueState、MapState、ListState 等用户接口,其中最常用 ValueState、MapState
- ⭐ 状态的存储粒度:以单 key 粒度访问、更新状态。举例,当我们使用 keyby.process,在 process 中处理逻辑时,其实每一次 process 的处理 context 都会对应到一个 key,所以在 process 中的处理都是以 key 为粒度的。这里很多同学会犯一个错 ❌,比如想在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的。
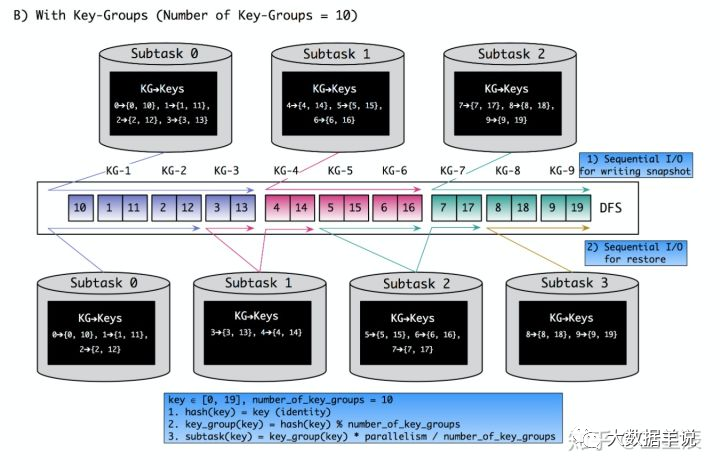
- ⭐ 并行度变化时:keyed-state 的重新划分是随着 key-group 进行的。其中 key-group 的个数就是最大并发度的个数。其中一个 key-group 处理一段区间 key 的数据,不同 key-group 处理的 key 是完全不同的。当任务并行度变化时,会将 key-group 重新划分到算子不同的 sub-task 上,任务启动后,任务数据在做 keyby 进行数据 shuffle 时,依然能够按照当前数据的 key 发到下游能够处理这个 key 的 key-group 中进行处理,如下图所示。注意:最大并行度和 key-group 的个数绑定,所以如果想恢复任务 state,最大并行度是不能修改的。大家需要提前预估最大并行度个数。
博主认为是 unbounded 类 SQL。博主的观点如下:
- ⭐ 先来看看为什么最开始发明了窗口类的算子:窗口(可以叫做 bounded)和 unbounded 的差异就在于,unbounded 类产出的结果不是一个固定结果,因为有 retract 机制(即 retract 流);窗口类的算子出现的最原始的目的就是解决 unbounded 类产出不固定结果的问题,是想要创造一个可以产出固定结果的算子(即 append 流,不考虑 allow_lateness),所以窗口算子类算子可以说是解决 unbounded 的存在的一个问题而诞生的,个人理解是流式任务在 SQL 上能力拓展。
- ⭐ 计算引擎(Flink)的流批一体:目前批中是没有时间窗口之类的概念的,所以如果想做到流批一体在计算引擎用户接口层的统一的话,unbounded SQL 可以做到这一点
- ⭐ 流式 SQL 的普及度,用户上手难易程度:目前大多数数据开发都还是离线数据开发,离线数据开发切换到实时数据开发使用 unbounded 类 SQL 的切换难度是会小,不用去学习窗口类的接口
但是在目前全链路 changelog 计算不是非常成熟的场景下,是没法完全摒弃窗口类应用的。目前业界做的好的就是阿里,阿里目前几乎不用窗口类应用,他们有一套成熟的 changelog 链路。
为什么阿里不用窗口类应用,因为窗口类应用天生有一个缺点就是会 丢数。
往期推荐
爆肝 1 年,18w 字 Flink SQL 手册,横空出世 !!!(建议收藏)
晋升季,如何减少 50%+ 的答辩材料准备时间、调整心态(个人经验总结)
flink sql 知其所以然(十三):流 join 很难嘛???(下)
flink sql 知其所以然(十二):流 join 很难嘛???(上)
flink sql 知其所以然(十一):去重不仅仅有 count distinct 还有强大的 deduplication
flink sql 知其所以然(十):大家都用 cumulate window 计算累计指标啦
--END--

非常欢迎大家加我个人微信,有关大数据的问题我们一起讨论
长按上方扫码二维码,加我微信

动动小手,让更多需要的人看到~
