
从一个实战问题再谈 Elasticsearch 数据建模
1、上问题
请问在一张订单表里,用户购买的产品是一条数据,我现在想查既购买了 A 又买了 B 的用户,这种需求能做吗?
在表里存在一个用户购买了多种产品和一个产品被多个人购买的情况,每个用户购买的产品是一条单独的数据。
假如现在的表已经是我上边说的那种情况了,能写出符合我查询要求的DSL吗?
球友提问
2、问题细化
注意,类似的问题是业务问题,如果要实际落地分析,需要进一步核实确认当前的数据建模。
本质一句话:数据的建模决定了数据的存储,数据的存储决定了数据的检索实现。
经反复讨论,敲定了当前的简化的数据建模如下:
PUT products
{
"mappings": {
"properties": {
"uid":{
"type":"keyword"
},
"tag_name":{
"type":"keyword"
}
}
}
}
POST products/_bulk
{"index":{"_id":1}}
{"tag_name":["阳光保险-2016"], "uid":"1111_2222"}
{"index":{"_id":2}}
{"tag_name":"太平洋保险-2020", "uid":"1111_2222"}
{"index":{"_id":3}}
{"tag_name":"平安保险-2019", "uid":"333333"}
两个字段给大家简单解读一下:
uid,用户id "tag_name,用户购买的产品
如上的建模就和问题描述建立起一一对应的关系了。
用户id为:1111_2222 的用户,购买了 2 个产品:阳光保险-2016 和 太平洋保险-2020。
现在问题转嫁为:查找购买了“阳光保险-2016” 和 “太平洋保险-2020” 的用户?
到了这里,问题基本上无二义,双方理解基本一致。
ps:这也是咱们公司内部沟通拆解问题的思路,由于问题比较简单,不再啰嗦。
3、问题剖析
怎么做?
看到这里,大家可以想一下?暂停几秒,再往后看... ...
这时候,脑海里想一下,检索或者聚合能否实现类似需求?
注意:购买了 “阳光保险-2016” 和 “太平洋保险-2020” ,是与的关系。首先想到的是:bool 和 must 结合。
很快啊,答案写在了下面
POST products/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"tag_name": "阳光保险-2016"
}
},
{
"term": {
"tag_name": "太平洋保险-2020"
}
}
]
}
}
}
但,放到 Kibana里面执行一下,发现怎么返回结果为空?
大意了吗?!再仔细审题.....
恍然大悟,本质错误原因在于:一对一的字段映射关系,怎么能得到两个或者多个都匹配的结果呢?
这才意识到哪里出了问题?!——不是数据检索,而是数据建模!
4、问题解答
问题的本质再细化抽象:
这已经不是简单的 Mysql 中的一对一的数据关系,所谓一对一代表 —— 一个用户 id 对应一个产品名。
如下图所示:多个 1 对 1 表示不同的doc。
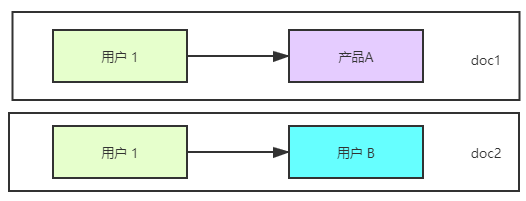
而是:一对多的数据关系。
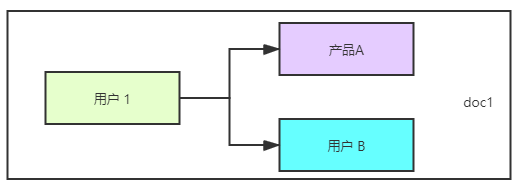
为什么?多个一对一是不能解决:查找购买了“阳光保险-2016” 和 “太平洋保险-2020” 的用户的需求的?
那怎么实现呢?几乎没有更好的方法,除了:数据重新建模。
再建模的时候,要以上面的一对多的图示作为依据。
这时候,脑海里要浮现出 ES 支持哪些所谓“多表关联”操作?
至少应该想到:
Array 数组类型 Object 对象类型 Nested 嵌套对象类型 Join 父子关联类型
我们先拿 Array 数组类型试验,提到数组类型,里面要进一步映射出 Elasticsearch 关于数组的定义:
在Elasticsearch中,没有专用的数组数据类型。
默认情况下,任何字段都可以包含零个或多个值。
数组中的所有值必须具有相同的数据类型。
强调一下:根据数组的定义,之前定义的 Mapping 是不需要修改的。
实践一把:
POST products/_bulk
{"index":{"_id":1}}
{"tag_name":["阳光保险-2016", "太平洋保险-2020"], "uid":"1111_2222"}
{"index":{"_id":2}}
{"tag_name":"太平洋保险-2020", "uid":"1111_2222"}
{"index":{"_id":3}}
{"tag_name":"平安保险-2019", "uid":"333333"}
如此,一对一的数据建模变成了一对多的数据建模。
验证一把结果是否达到预期呢?
POST products/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"tag_name": "阳光保险-2016"
}
},
{
"term": {
"tag_name": "太平洋保险-2020"
}
}
]
}
}
}
返回结果(仅贴出了 hits 部分):
"hits" : [
{
"_index" : "products",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.6161176,
"_source" : {
"tag_name" : [
"阳光保险-2016",
"太平洋保险-2020"
],
"uid" : "1111_2222"
}
}
]
很简单的就实现了需求。
注意:Object,nested 等也可以实现,要根据具体业务所需,不再展开讲。
5、再谈数据建模
为什么是再谈,是因为我们强调过:干货 | 论Elasticsearch数据建模的重要性。
尤其基础数据源来自关系型数据库(Mysql、Oracle 等)的业务数据,切记不要将数据同步到ES就完事大吉。
同步之前需要讨论:
数据在 Elasticsearch 怎么建模? Mapping 如何设置? 哪些字段需要全文检索?需要分词?哪些不需要? 哪些字段需要建索引? 哪些字段不需要存储? 类型选择:integer 还是 keyword? 哪些需要做多表关联?使用:宽表冗余存储?还是 Array,Object,Nested,Join ?都需要深入考虑。 哪些字段需要预处理? 预处理是通过logstash filter 环节实现?还是 Mysql 视图实现?还是 ingest 管道实现?还是其他? ...... 类似延伸出几十个问题都不在话下。
这里想的越充分,后面越省事!
关于多表关联问题,推荐阅读:Elasticsearch多表关联设计指南
6、小结
数据建模的培养没有太好的速成方法,需要结合项目实践、反馈、再实践、再反馈总结。形成知识积累。