
数据合并之concat、append、merge和join
Pandas 是一套用于 Python 的快速、高效的数据分析工具。它可以用于数据挖掘和数据分析,同时也提供数据清洗功能。本文将详细讲解数据合并与连接,目录如下:
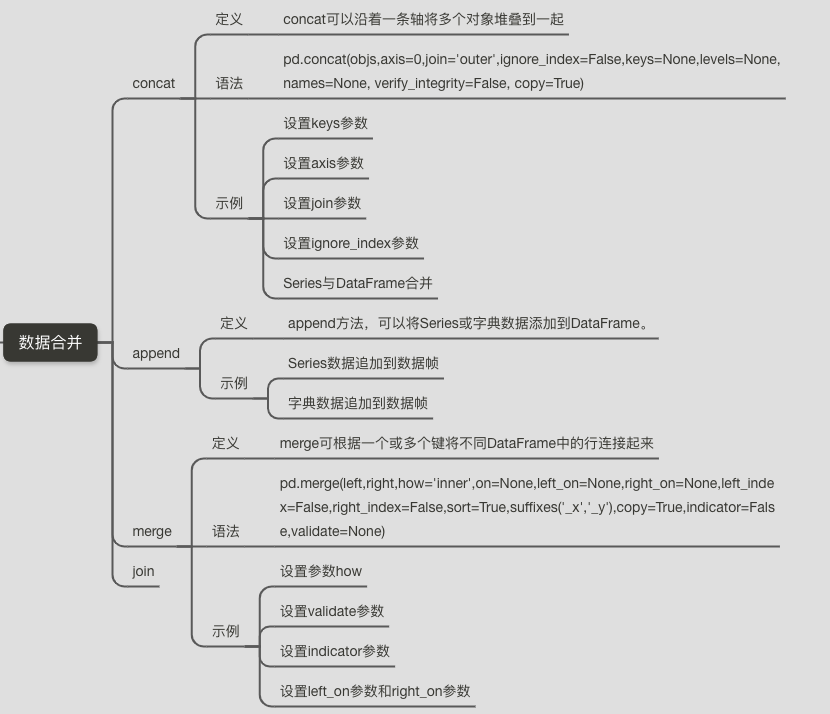
一.定义
concat函数可以在两个维度上对数据进行拼接,默认纵向拼接(axis=0),即按行拼接。拼接方式默认为外连接(outer),即取所有的表头字段或索引字段。
二.语法
参数释义:
objs:需要用于连接合并的对象列表
axis:连接的方向,默认为0(按行),按列为1
join:连接的方式,默认为outer,可选inner只取交集
ignore_index:合并后的数据索引重置,默认为False,可选True
keys:列表或数组,也可以是元组的数组,用来构造层次结构索引
levels:指定用于层次化索引各级别上的索引,在有keys值时
names:用于创建分层级别名称,在有keys和levels时
verify_integrity:检查连接对象中新轴是否重复,若是则异常,默认为False允许重复
copy:默认为True,如果是False,则不会复制不必要的可以提高效率
三.代码示例
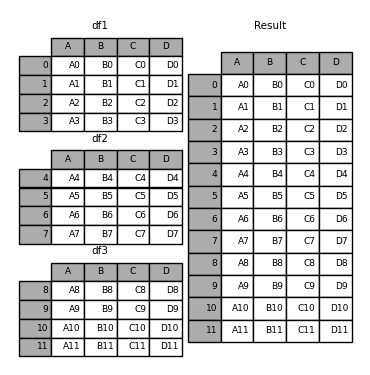
首先,我们看一个简单的例子:

以上代码构建了3个字典并转为DataFrame,然后通过concat实现默认方式合并。合并演示如下:
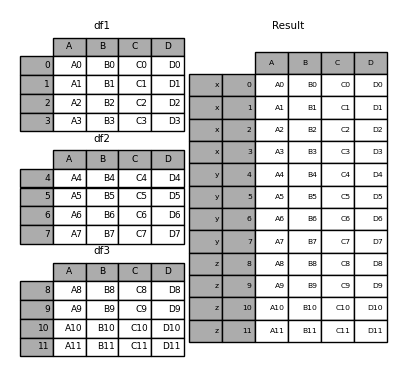
1.设置参数keys


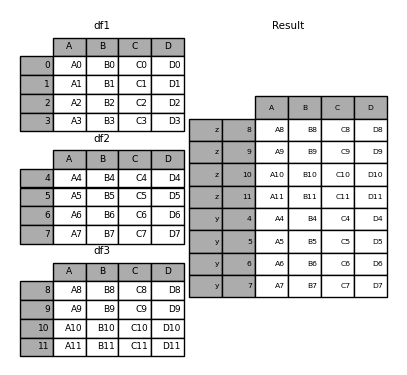

2.设置axis参数
axis=1按列合并,默认情况下,join='outer',合并时索引全部保留,对于不存在值的部分会默认赋NaN。

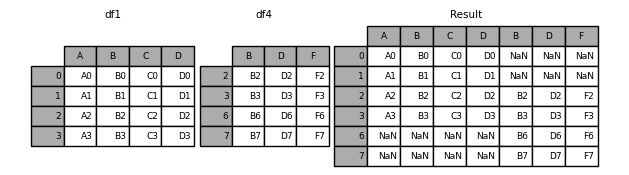
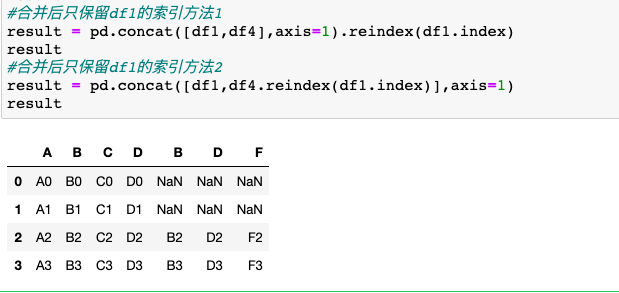
3.设置join参数


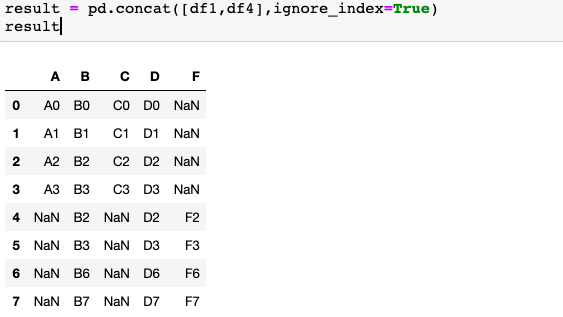
4.设置ignore_index参数
5.Series与DataFrame合并

一.定义
运用append方法,可以将Series或字典数据添加到DataFrame。
二.代码示例
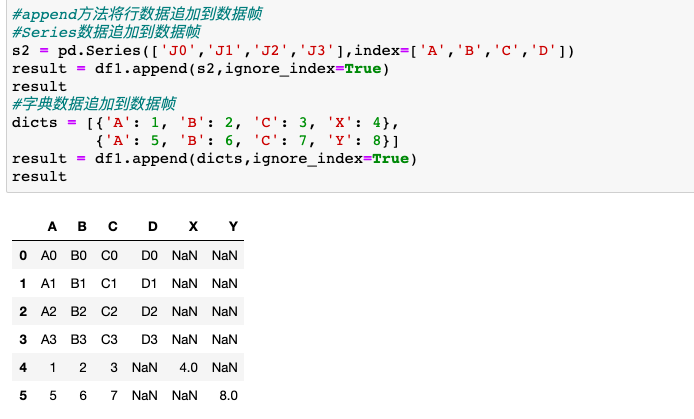
一.定义
merge函数可根据一个或多个键(列)相同进行DataFrame拼接。类似于关系型数据库的join操作。
二.语法
参数释义:
left:参与合并的左侧数据
right:参与合并的右侧数据
how:合并类型:inner(默认内连接)、outer(外连接)、left(左连接)、right(右连接)
on:用于连接的列名,默认为左右侧数据共有的列名,指定时需要为左右侧数据都存在的列名
left_on:左侧数据用于连接的列
right_on:右侧数据用于连接的列
left_index:将左侧索引作为连接的列
right_index:将右侧索引作为连接的列
sort:排序,默认为True,设置为False可提高性能
suffixes:默认为('_x', '_y'),可以自定义如('date_x','date_y')
copy:默认为True,如果是False,则不会复制不必要的可以提高效率
indicator:指示器,默认False,设置为True时会新增一列标识
validate:字符串,如果指定则会检测合并的数据是否满足指定类型(1对1,1对多,多对1,多对多)
三.示例
首先,我们看一个简单的例子:

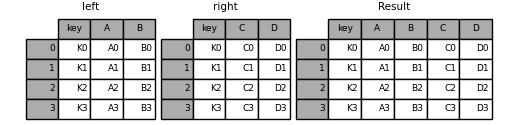
1.设置参数how

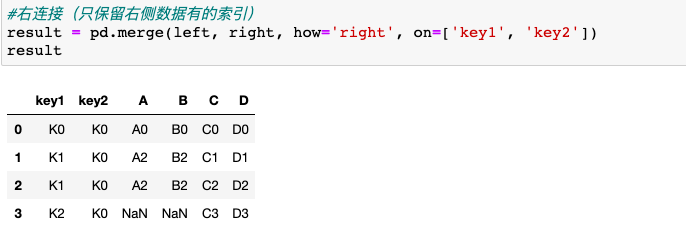
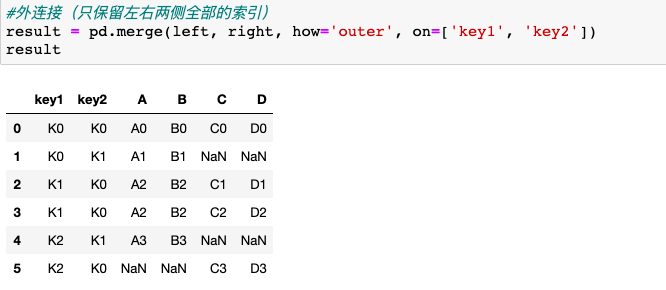

2.设置validate参数

3.设置indicator参数

4.设置left_on参数和right_on参数

一.定义
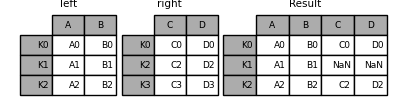
join可以将两个没用共同列名的数据进行快速合并,默认是保留被合并的数据索引。join接受的参数有how、on和suffix等。
二.示例


E N D

各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读
推荐阅读