
每日优鲜测试环境多泳道的实践
一、背景
优鲜非常重视测试环境治理,提高开发和测试人员的使用效率。从 2018 年就开始了测试环境治理之路,也有幸的见证了其中几个阶段,最早期,2018 年初测试环境当时几台虚机,把需要测试的服务部署上去,经常发生抢占问题,刚部署服务分支又被别人覆盖,测试完流程才发现代码部署不正确,造成效率非常低下;2018 年年中开始对测试环境进行治理,初始化了十几套域名和机器,用域名隔离环境,各业务线通过发布系统抢占环境后使用,这样暂时缓解了代码被覆盖的问题,但是抢占问题依旧十分严重;2020 年开启了第二波整治,借助 Docker 的快速扩展能力开始对测试环境新一轮的治理,通过自研的环境管理系统(以下简称阿拉丁系统)可以拉起一套完全隔离的全链路环境,资源隔离好,但是随着全链路环境的增多,任何一个全链路环境问题可能都需要开发去查看,给开发和测试也增加了维护成本。目前,我们正着手新一轮的测试环境治理工作,致力于提高测试环境使用效率。
二、多泳道介绍
2.1、什么是多泳道
多泳道结构就是借鉴了游泳比赛的概念,所有运动员在一个泳池内,划分了比赛赛道,谁超出赛道就算犯规。那么抽象到设计中就是,一套完整的服务链路就是一个泳道,而请求数据就是运动员,在自己泳道中任意流转,不会干扰其他泳道的数据。再进一步抽象,分离出主泳道和分支泳道概念,目的是把通用的服务集中在主泳道,分支泳道部署变动服务,并且依赖主泳道的通用服务,内部通过物理或者逻辑隔离请求数据。
2.2、多泳道的目标
一方面是保证测试环境稳定,提高测试效率。联想到测试环境,大多数反应是测试环境不稳定,主要由以下原因造成,第一,测试环境部署的是开发中代码,代码的不稳定;第二,测试环境存在脏数据;第三,是对测试环境的不重视,缺少监控等;第四,测试的机器资源没法和线上对齐等因素,导致测试环境必然是不稳定的。因此多泳道方案提出了主泳道和分支泳道概念,主泳道则部署稳定代码和线上代码保持一致,保证了代码的稳定性,然后开发人员只用专心维护一套全链路环境,降低了维护成本,提高了主泳道的稳定性。
另一方面解决抢占问题,提高开发效率。在多业务线多需求同时开发时,都需要各自一套环境隔离,相互不造成影响,但测试环境的机器是有限,就会造成大家相互抢占,或者共用同一环境,造成测试效率降低。因此多泳道方案提出一种规范,收回开发人员部署主泳道权限,由系统定期自动部署最新稳定代码,而开发人员只在分支泳道部署变动服务,其余全部依赖主泳道中服务,减少部署量和资源浪费,由于分支泳道非常轻量,可以非常快捷创建和销毁。
2.3、多泳道的价值收益
经过多业务小组验证,在测试环境创建时间方面至少提升 10 倍,原来创建一套测试环境需要拷贝底层数据库,拉取全链路所有服务等,耗时大概 3 小时,但是泳道方案拉起一个分支泳道只需几分钟。由于分支泳道的快捷性,可以创建更多的分支泳道给不同业务组或者同业务组不同需求。总结一下,就是更快更多更稳定。
三、技术方案
3.1、系统架构
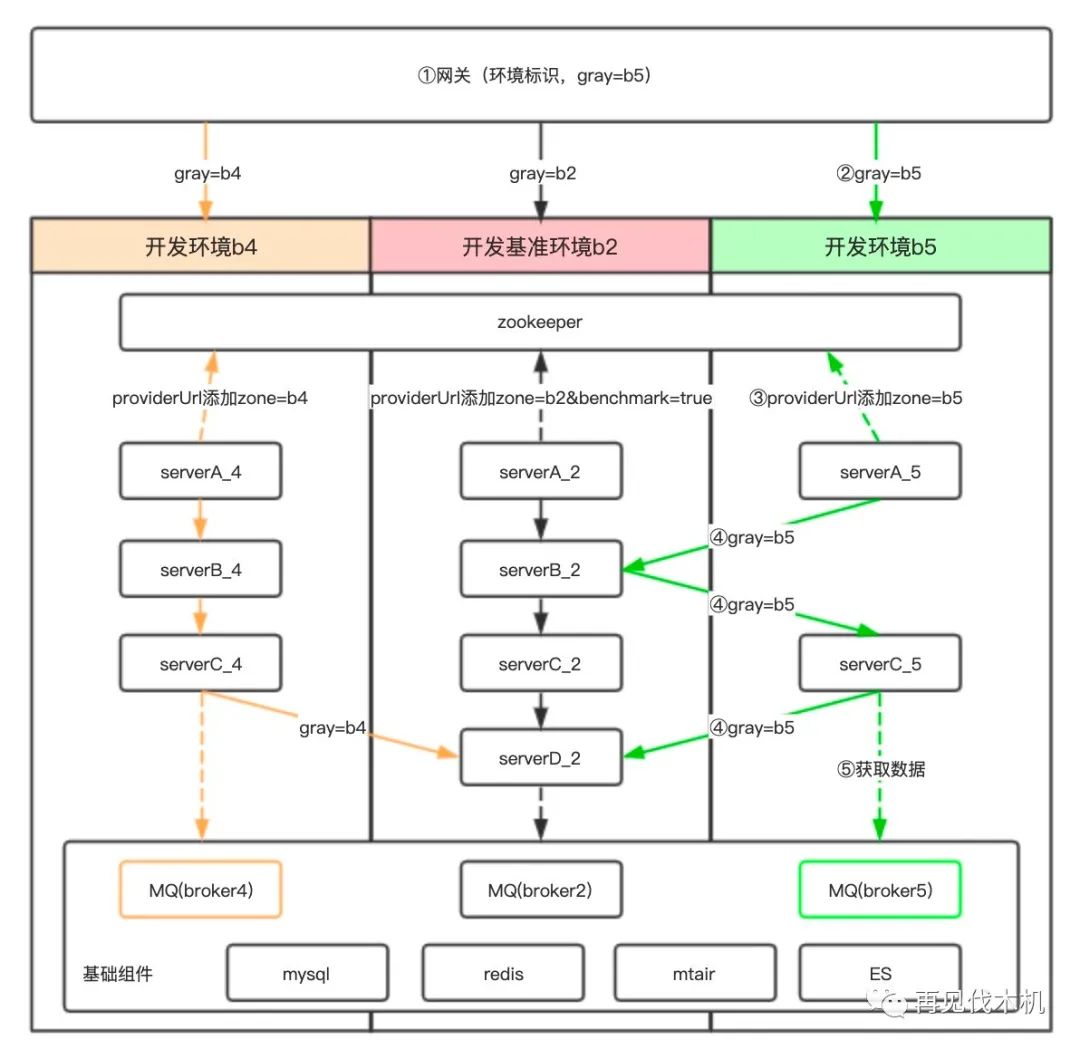
架构主要包括三部分,网关层,RPC 层和数据层。
网关层主要负责环境识别与环境标识注入,前台通过测试域名隔离环境,例如:b2.missfresh.net/xx,请求到网关后解析出环境标识 b2,然后植入 HTTP Header 中,往下透传。
RPC 层主要负责服务发现与选择,环境标识透传等。通过服务发现找到对应环境下服务,再通过自定义路由策略选择指定服务执行,并把环境标识继续透传给下游。
数据层主要负责测试环境数据隔离与共用。
逻辑结构主要分为主泳道和分支泳道。
主泳道部署全链路稳定代码,作为公共环境,承载其他环境缺省服务,保证请求链路通畅。
分支泳道只需部署改动服务,未改动服务使用主泳道中服务,比如底层的商品,库存等服务,发号器,推送等组件,目的是减少公共服务的维护成本,提高使用效率等。
根据以上流程,需要对组件做一些改动:
网关新增环境标识注入。测试环境使用开源的流量网关(Kong),然后额外定制一个插件,解析域名并把环境标识注入到 HTTP Header 中,往下透传。
链路标识的透传。使用开源的链路追踪系统(Pinpoint),新增或者增强链路透传插件,把链路标识透传下去。选择 Pinpoint 是因为它以 JavaAgent 方式嵌入到服务中,对服务是无感知的,可以结合部署系统做到无感知升级,比使用 SDK 方式更友好。
服务的感知。共用一套 Zookeeper,保证各泳道服务被及时发现,各泳道服务注册时带上环境标识。
服务的选择。使用 Dubbom 新增的路由策略,根据服务自身环境标识和链路中的环境标识做匹配选择。
数据存储。不同的需求需要隔离级别不同,如果多环境共用底层数据,则代码中使用域名配置数据库,由 DNS 服务指向同一套数据库,例如:配置 b2.mysql.missfresh.net 与 b15.mysql.missfresh.net 域名指向同一实例 IP;如果多套环境隔离底层数据,则 MySQL,Redis 需要封装一套 SDK,通过环境标识把数据写到不同的库或者实例,RocketMQ 则需要封装一套 SDK,通过环境标识把消息发往不同的队列,ElasticSearch 则可以在上一层封装一套网关,通过网关的路由功能转发到不同索引或者实例。
下面给大家分解下各个模块的隔离方案。
3.2、服务隔离
进行服务隔离有两个方向,物理隔离与逻辑隔离。
方案1、物理隔离可以通过部署多套 Zookeeper 隔离,让 Consumer 只在当前 Zookeeper 中获取 Provider 列表,然后调用,达到环境隔离效果。

方案2、逻辑隔离可以通过标识 Provider 与 Consumer,再通过自定义负载均衡算法,让 Consumer 调用指定的 Provider 服务,达到环境隔离的效果。
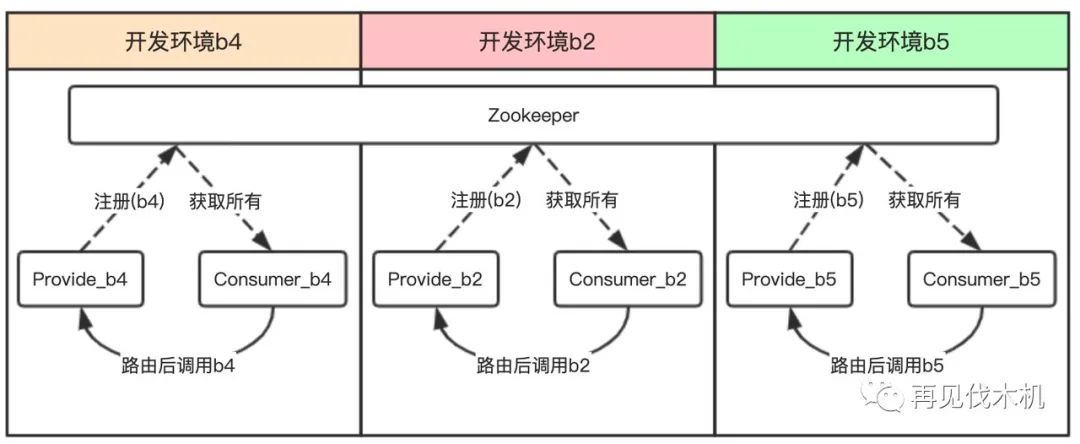
物理隔离的优势是隔离性好,弊端是每套环境都需要一套 Zookeeper,这样在快速创建环境时会影响效率,还有个弊端是为了达到 3.1 架构图中绿线的流程,需要让主泳道的请求再扭转回分支泳道,主泳道的服务就必须监听所有分支泳道的 Zookeeper,这样才能监听分支环境服务的存活情况,但这样会造成主泳道非常臃肿,代码实现也非常复杂。
所以,我们选择了逻辑隔离的方案,在 Provider 注册时添加一个标识,在 Consumer 获取 Provider 列表后,通过自定义负载均衡算法,找出指定环境 Provider 并调用。
方案确定后,我们需要做的就是对 Dubbom(rpc组件) 进行一些改造。
第一步,在容器中注入环境标识,可以通过环境变量,也可以通过本地配置文件,目的是让服务启动后能感知到当前容器属于哪个泳道。
第二步,在 Provider 注册时获取当前环境标识,然后在 ServiceConfig.doExportUrls() 生成注册链接时添加一个参数(zone)用来标识当前环境。
生成的注册链接如下:
dubbo://127.0.0.1:10080/com.missfresh.xxxxService?anyhost=true&application=mryx&bean.name=ServiceBean:com.missfresh.xxxxService:1.0&default.dispatcher=message&default.service.filter=notice&default.threadpool=fixed&default.threads=300&default.timeout=1000&dubbo=2.0.2&interface=com.missfresh.mpush.xxxxService&logger=slf4j&methods=xxxx&pid=1®istry=127.0.0.1:2181&revision=1.0.0&side=provider×tamp=1622925206798&version=1.0&zone=b2
第三步,再实现路由算法,算法逻辑不难,Consumer 通过当前环境标识找到对应的 Provider 即可。需要注意的是,Dubbom 既可以通过 Router 方式也可以通过 LoadBalance 方式实现路由策略,区别在于 Route 在 LoadBalance 更上一层,控制力度更大,比如在多注册中心的场景下,Route 方式可以路由到不同注册中心,而 LoadBalance 方式只能选择经过 Router 筛选过后的 Provider 列表,并不能动态选择多注册中心,这种区别也会用于后续的同城双活方案,所以选择了 Router 去实现。

3.3、消息隔离
先介绍下 RocketMQ 的结构,物理结构包括 NameServer 与 Broker,而逻辑结构包括 Topic 与 Queue,Topic 包含多个 Queue,Queue 又分布在不同 Broker 上保证高可用。针对物理与逻辑结构可以设计出不同隔离方案,下面有三种隔离方案供参考。
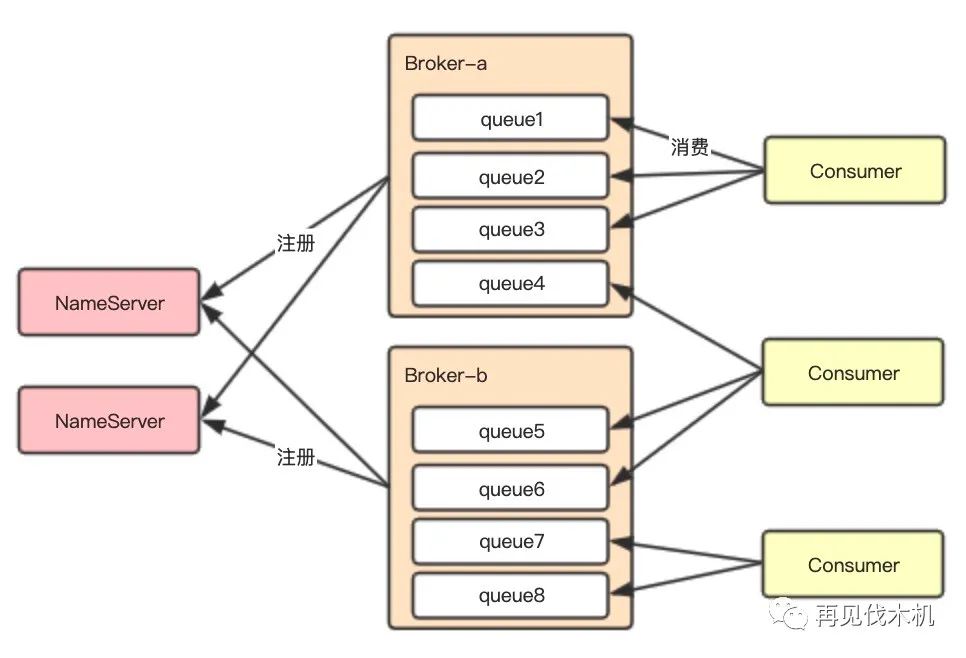
3.3.1、Queue 隔离
Queue 的隔离思想是让每个泳道使用指定的 Queue,例如泳道 b1 只在 queue1 和 queue2 上收发消息,泳道 b2 只在 queue3 和 queue4 上收发消息。实现这种效果,需要重写 Producer 与 Consumer 的负载均衡算法,分配指定的 Queue 进行收发消息。弊端就是每个泳道环境需要扩容 Queue,提高消费能力就比较棘手,而且随着泳道增多,Queue 数量也需要动态增加。

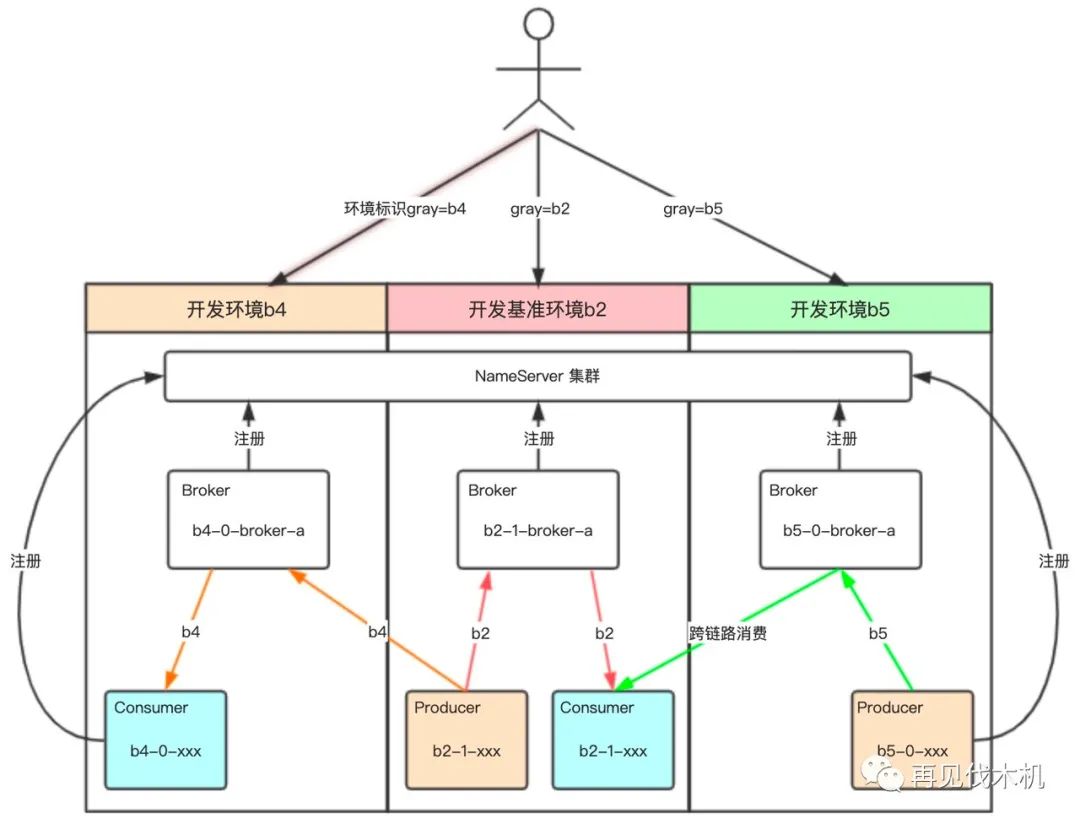
3.3.2、Broker 隔离
Broker 隔离的思想与 Queue 隔离思想类似,也是让每个泳道使用指定的 Broker,通过 Broker 物理级别隔离消息,然后各泳道的收发消息都在指定泳道。实现这种效果需要标记 Broker 与 Producer 和 Consumer 属于哪个环境,可以通过命名规则实现,再重写 Producer 与 Consumer 的负载均衡算法,把 Broker 与 Producer 和 Consumer 做亲和处理即可。弊端是每个环境需要部署 Broker。
3.3.3、消息网关隔离
消息网关方案的思想是通过加一层代理去屏蔽 Queue 的选择等,客户端只需带上环境标识收发消息即可,由网关决定消息去向与消费逻辑。弊端在于需要为测试环境开发一套网关系统,周期比较长。

综上,最终选择了 Broker 隔离方案。
一方面是 Queue 扩展性的考虑,另一方面是为测试环境构建一个消息网关周期较长,开发成本高,最后也可以提前验证同城双活的方案,因为同城双活方案的部署结构与 Broker 隔离结构一致,用 Broker 隔离两地机房中的消息,并且两机房间也需要相互兜底消费。
方案确定后,剩下就是对 MQ-SDK 进行一些改造。
第一步,规范 Broker 名称与 Producer,Consumer 的实例名称,让名称中带上环境标识,规则代码如下:
/**
* 根据当前环境生成唯一标识
* @return {当前环境}-{是否基准环境}-{PID}-{自增保证唯一}
*/
public static String genInstanceName() {
String instanceName = String.valueOf(UtilAll.getPid()) + SPLIT + COUNT.incrementAndGet();
instanceName = (Boolean.TRUE.toString().equalsIgnoreCase(benchmark) ? "1" : "0") + SPLIT + instanceName;
instanceName = (StringUtils.isNotEmpty(zone) ? zone : DEFAULT_ZONE) + SPLIT + instanceName;
return instanceName;
}
最后生成每个实例的 ClientId 效果:

第二步,重写 Producer 负载均衡算法。实现 MessageQueueSelector 接口 select 方法,从所有的队列中选出指定的队列,然后在发送的时候指定负载策略即可。例如当前环境是 b2,则把所有 Broker 名称是 b2 前缀的队列全返回。主要代码如下:
protected List<MessageQueue> groupByZone(List<MessageQueue> mqs) {
// 优先从链路中获取环境标识
String zone = Extractor.getGray();
List<MessageQueue> localQueueList = new ArrayList<>(mqs.size());
List<MessageQueue> benchmarkQueueList = new ArrayList<>(mqs.size());
for (MessageQueue messageQueue : mqs) {
String[] brokerNameArray = messageQueue.getBrokerName().split(MryxConfig.SPLIT);
String queuePrefix = brokerNameArray[0];
if (zone.equalsIgnoreCase(queuePrefix)) {
// 当前环境队列
localQueueList.add(messageQueue);
} else if (brokerNameArray.length > 2 && RocketMQConfig.IS_BENCHMARK.equals(brokerNameArray[1])) {
// 基准环境队列
benchmarkQueueList.add(messageQueue);
}
}
if (!localQueueList.isEmpty()) {
return localQueueList;
}
if (!benchmarkQueueList.isEmpty()) {
return benchmarkQueueList;
}
return mqs;
}
第三步,重写 Consumer 负载均衡算法。实现 AllocateMessageQueueStrategy 接口的 allocate 方法,从所有的队列中选择指定的队列消费。例如当前环境是 b2,则只消费所有 Broker 名称是 b2 前缀的队列,达到消费隔离目的。主要代码如下:
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll, List<String> cidAll) {
// 根据messageQuery中brokerName的环境标识分组
Map<String/*machine zone */, List<MessageQueue>> mr2Mq = new TreeMap<>();
for (MessageQueue mq : mqAll) {
String brokerMachineZone = machineRoomResolver.brokerDeployIn(mq);
mr2Mq.putIfAbsent(brokerMachineZone, new ArrayList<>());
mr2Mq.get(brokerMachineZone).add(mq);
}
// 根据clientId的环境标识分组
Map<String/*machine zone */, List<String/*clientId*/>> mr2c = new TreeMap<>();
// 基准环境的clientId
List<String> benchmarkClientIds = new ArrayList<>();
for (String cid : cidAll) {
String consumerMachineZone = machineRoomResolver.consumerDeployIn(cid);
mr2c.putIfAbsent(consumerMachineZone, new ArrayList<>());
mr2c.get(consumerMachineZone).add(cid);
if (machineRoomResolver.consumerIsBenchmark(cid)) {
benchmarkClientIds.add(cid);
}
}
List<MessageQueue> allocateResults = new ArrayList<>();
// 1、匹配同机房的队列
String currentMachineZone = machineRoomResolver.consumerDeployIn(currentCID);
List<MessageQueue> mqInThisMachineZone = mr2Mq.remove(currentMachineZone);
List<String> consumerInThisMachineZone = mr2c.get(currentMachineZone);
if (mqInThisMachineZone != null && !mqInThisMachineZone.isEmpty()) {
allocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, mqInThisMachineZone, consumerInThisMachineZone));
}
// 寻找没有匹配上zone的MessageQueueList
for (String machineZone : mr2Mq.keySet()) {
if (mr2c.containsKey(machineZone)) {
continue;
}
// 2、如果存在基准环境consumer,则把没有消费者的messageQueue分配给基准环境
if (!benchmarkClientIds.isEmpty()) {
if (machineRoomResolver.consumerIsBenchmark(currentCID)) {
allocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, mr2Mq.get(machineZone), benchmarkClientIds));
}
} else {
// 3、如果没有基准环境,则没有消费者的messageQueue再次分配给consumer
allocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, mr2Mq.get(machineZone), cidAll));
}
}
return allocateResults;
}
第四步,主流程通畅后,还需要考虑一下特殊情况,由于分支泳道非全链路,所以分支泳道可能上游的 Producer 未部署,或者下游的 Consumer 未部署,为了保证链路通畅,就需要一套主泳道兜底逻辑,如果分支泳道 Producer 未部署,则由主泳道根据链路标识发送到对应 Broker 中,图 3.3.2 中橙色的线;如果分支泳道 Consumer 未部署,则由主泳道消费,保证链路通畅,图 3.3.2 中绿色的线。以上,就是消息隔离的方案。
3.4、存储隔离
存储隔离主要使用物理隔离方案,实现比较简单,例如代码中用域名指向数据库地址,容器创建时候可以在配置 host 指定真是数据库地址;还有一种方案是代码中配置的一个变量,由容器配置环境变量,最后在代码中读取变量时替换成真实地址。逻辑隔离方案可能会涉及到修改业务代码,工作繁琐,业务稳定性也存在问题,所以很少使用这种方案
由于不同业务对测试环境数据隔离性需求不同,一些团队只想维护一份底层数据,有些团队则需要数据隔离跑自动化测试等。目前,泳道还是采用的底层共用数据存储,好处是每次新创建分支用不到不用再创建数据库和同步数据,大大提高了环境申请和销毁效率。对于自动化测试等需要数据隔离的,我们则另外部署一套全链路环境。
四、挑战
泳道方案依赖 Pinpoint 链路跟踪系统的透传功能,在线程池场景会丢失链路信息,经过多方调研,组内同学通过字节码加强的方式得以解决。
组件升级,由于改造了 Dubbom,MQ-client 等组件,需要统一组件,其中涉及到组件迁移,兼容性等问题,我们深度参与业务方改造,借助自动化测试,验证升级组件后的稳定性。
五、未来展望
测试环境的自动化。目前申请或者销毁新泳道还不够自动化,需要一个环境管理面板,罗列出已存在哪些泳道正在被谁使用,各泳道需要部署了哪些服务,服务的健康状态等;通过工单系统自动申请或者销毁泳道环境。这样对环境管理就非常清晰,提高大家使用效率。
目前泳道环境底层存储未隔离,只对开发人员开放,因为测试人员对数据隔离比较敏感,所以,我们也正在对 MySQL,Redis 等组件进一步改造,通过环境标识路由到不同的库或者实例,到达数据隔离的效果。
六、总结
多泳道方案已在测试环境运行一段时间,也遇到一些问题,经过探索形成了自有的一套解决方案。该解决方案结合了我们自有的组件,并在同城双活的方案基础实现,所以某些隔离方案并非针对测试环境最优的,但是比较适合我们的。希望对大家有一些启发,同时也欢迎大家一起探讨。
作者简介
钟凯,2018年加入每日优鲜,目前主要从事每日优鲜的基础组件(MQ、RPC组件、泳道、故障演练平台等等)的开发 邮箱 : zhongkai@missfresh.cn
感谢苏磊(公众号:再见伐木机)对本文的指正