
Google又一个狠活!首个文本视频生成模型
【导读】刚做完画家,普通人又能当导演了?



A photorealistic teddy bear is swimming in the ocean at San Francisco. 一只逼真的泰迪熊在旧金山的大海里游泳。 The teddy bear goes under water. 泰迪熊进入水中。 The teddy bear keeps swimming under the water with colorful fishes. 泰迪熊在水中不断地游动,旁边有五颜六色的鱼 A panda bear is swimming under water. 一只大熊猫在水底游泳

Side view of an astronaut is walking through a puddle on mars 宇航员在火星上走过水坑的侧影 The astronaut is dancing on mars 宇航员在火星上跳舞 The astronaut walks his dog on mars 宇航员在火星上带着他的狗散步 The astronaut and his dog watch fireworks 宇航员和他的狗观看烟花


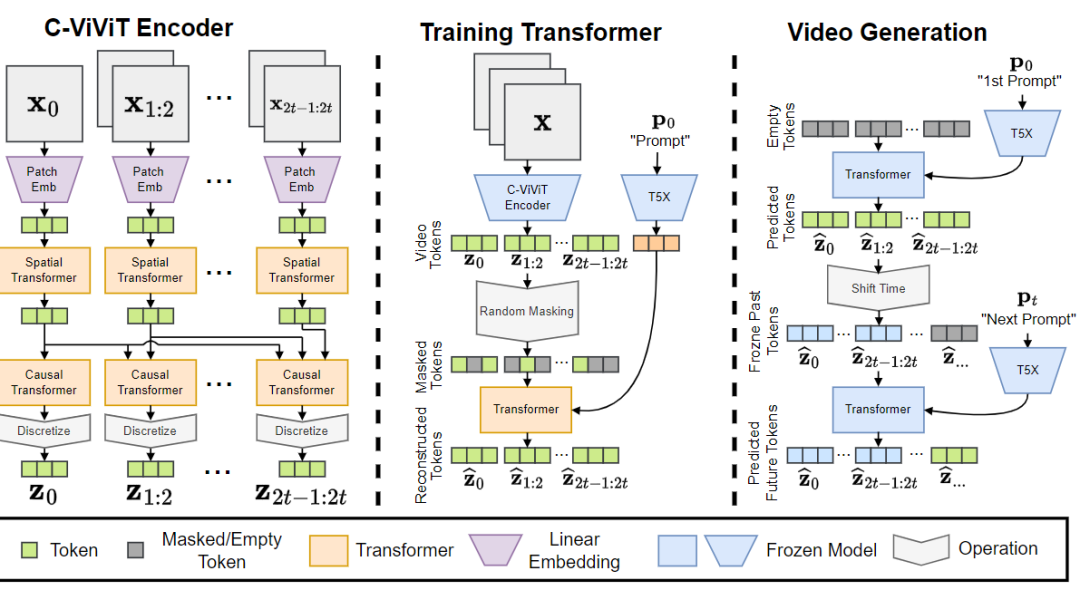
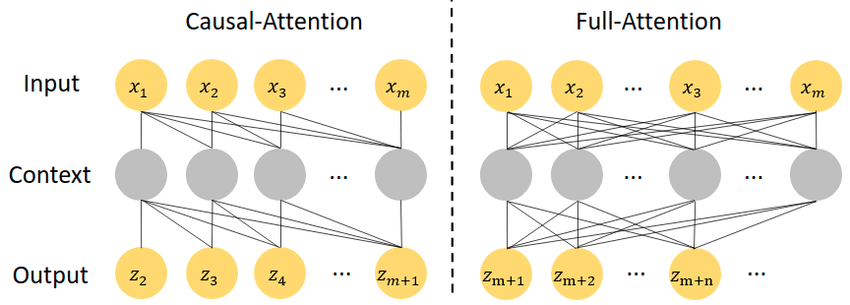
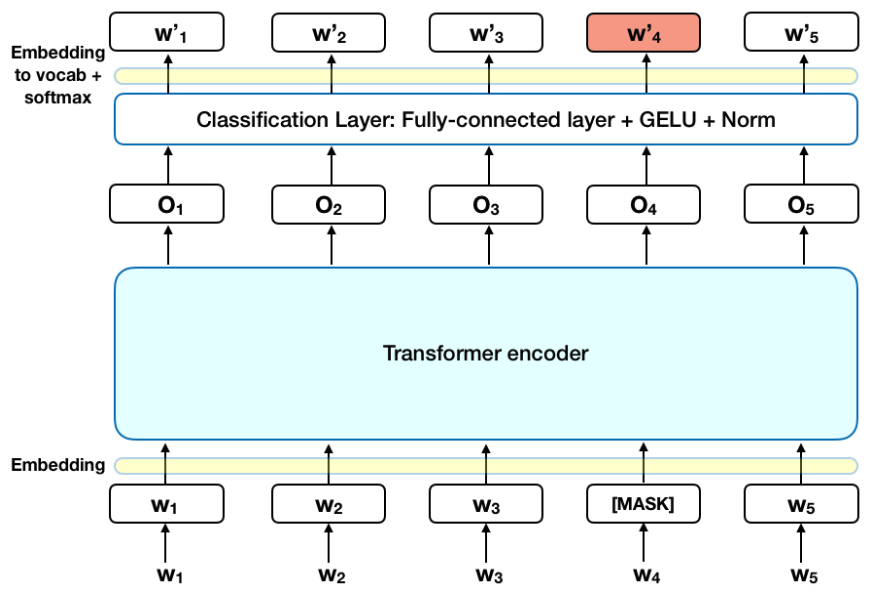
从文本到视频
从文本到视频




评论