
如何实现一个跨库连表SQL生成器?
一 概述
ADC(Alibaba DChain Data Converger)项目的主要目的是做一套工具,用户在前端简单配置下指标后,就能在系统自动生成的大宽表里面查询到他所需要的实时数据,数据源支持跨库并支持多种目标介质。说的更高层次一点, 数据的全局实时可视化这个事情本身就是解决供应链数据“神龙效应”的有效措施(参考施云老师的《供应链架构师》[1]一书)。做ADC也是为了这个目标,整个ADC系统架构如下图所示:
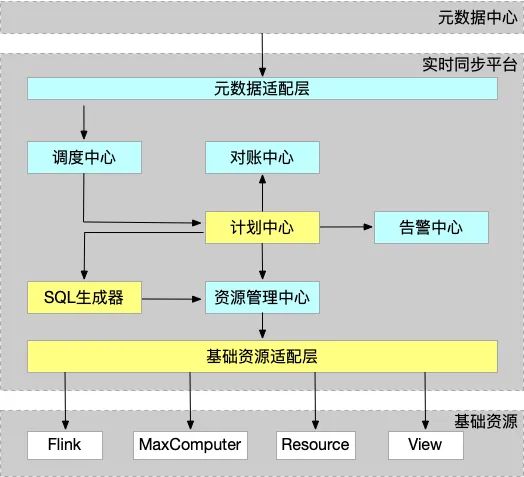
架构解析:
初始数据来自于元数据中心。
经过元数据适配层后转换为内部格式数据。
调度中心把内部格式的数据传到计划中心,计划中心分析数据需求并建模,通过SQL生成器生成资源和SQL,分别通过告警中心、对账中心设定监控标准和对账标准。
对账中心定时对账,查看数据的对齐情况。
告警中心可以针对任务错误、延迟高等情况发送报警。
资源的生命周期管控在资源管理中心下,view删除时资源管理中心负责回收资源。
基础资源适配层主要借助集团基础资源管理能力串联阿里各类数据服务, 比如阿里云MaxComputer、Flink、阿里云AnalyticDB等。
上游计划中心
配置指标:用户在前端配置他想看的数据有哪些。
生产原始数据:根据用户输入得到哪些表作为数据源, 以及它们之间的连接关系。
下游Metric适配器
把SQL发布到Flink, 根据建表数据建物理表。
需要支持多个事实表(流表)、多个维度表连表,其中一个事实表是主表,其他的均为辅助表。
维表变动也应当引起最终数据库更新。
主表对辅助表为1:1或N:1,也就是说主表的粒度是最细的, 辅表通过唯一键来和主表连接。
流表中可能存在唯一键一致的多张流表, 需要通过全连接关联。唯一键不同的表之间通过左连接关联。
只有连表和UDF,没有groupby操作。
要求同步延时较小,支持多种源和目标介质。由于查询压力在目标介质,所以查询qps没有要求。
同步生成SQL和建表数据 异步发布SQL和建表
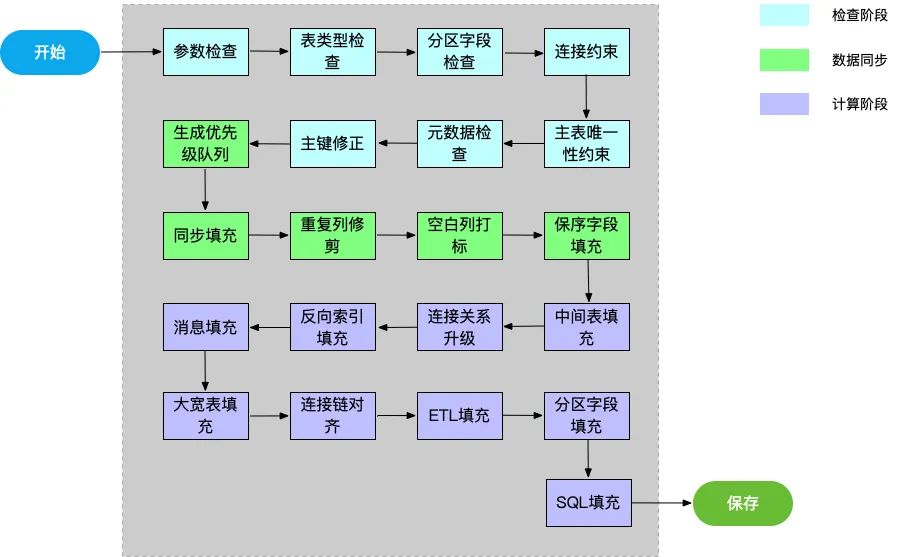
参数检查:检查上游是否提供了基本的参数, 比如事实表信息(可以没有维表, 但是必须有事实表)。
表类型检查:检查数据来源类型是否支持。
分区字段检查:是否提供了大宽表分区字段。
连接约束:检查流表,维表连接信息是否正确。
主表唯一性约束:检查主表是否含连接信息,唯一键是否有ETL信息。
元数据检查:检查是否包含HBase配置信息。
主键修正:修正维表连接键, 必须是维表的唯一键。
生成优先级队列:生成连接和发布等任务的执行优先级。
同步填充:填充源表对应的同步阶段HBase表数据,和对应的配置项, 类型转换(比如源表是MySQL表,字段类型要转换为HBase的类型), ETL填充, 添加消息队列(通过发送消息的方式通知下游节点运行)。
重复列修剪:删除重复的列。
空白列打标:对于满足一定条件(比如不需要在大宽表展示, 不是唯一键列, 连接键列, 保序列)的列打上空白列标识。
保序字段填充:如果上游提供了表示数据创建时间的字段, 则用该字段作为数据保序字段, 没有则填充系统接收到数据的时间作为保序字段。
中间表填充:填充全连接产生的中间表。
连接关系升级:会在本文后面说明。
反向索引填充:填充“反向索引”信息。
消息填充:中间表添加消息队列(中间表更新可以触发下游节点)。
大宽表填充:填充大宽表数据。
连接链对齐:中间表和大宽表连接键对齐。
ETL填充:填充大宽表列的ETL信息。
分区字段填充:填充大宽表分区字段。
SQL填充:填充Flink同步表映射SQL语句, Flink计算SQL语句, Flink结果表映射SQL语句。
保存:把SQL和建表数据存入数据库, 之后的请求可以复用已有的数据, 避免重复建表。
B表数据先于A表数据多天产生 B表数据后于A表数据多天产生 B表数据和A表数据同时产生
拆解后小功能多 小功能存在复用情况 小功能执行有严格的先后顺序 需要记录小功能运行状态, 流程执行可回滚或者中断可恢复执行
参考 PipeLine(流水线)设计模式[2],综合考虑后我们系统的整体设计如下图所示:
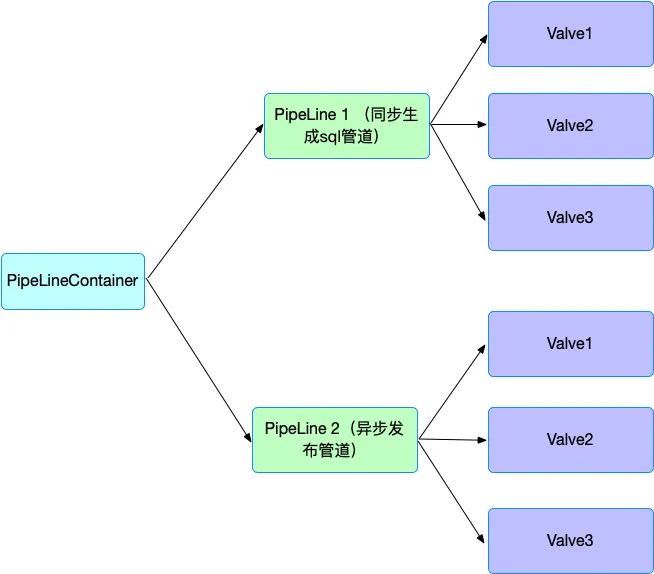
每个同步进来的数据源对应一个叶子节点 节点之间有关联关系,关联关系有多类并有执行优先级 所有节点和关联关系组成一棵树 最终得到一个根节点(大宽表)并发布
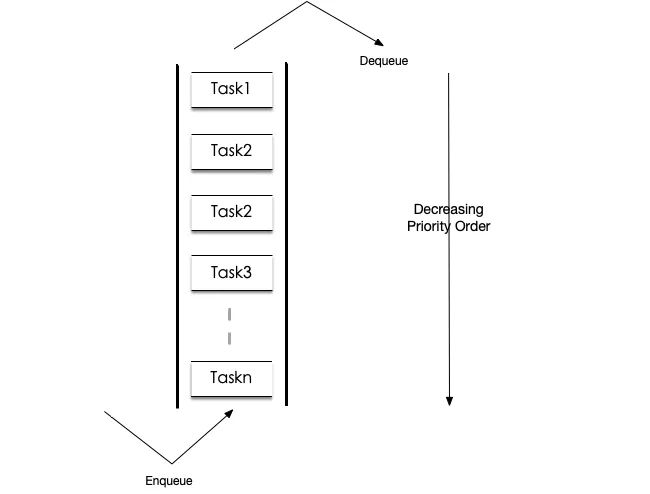
首先得到四种优先级的任务, 优先级从高到低分别为: 优先级1, 六个节点的同步任务 优先级2,节点1、2、3和节点4、5的Full Join任务 优先级3,节点1、4和节点6的Left Join任务 优先级4, 发布任务 取优先级1的任务执行,同步进来六个数据源对应六个叶子。 取优先级2的任务并执行得到中间表1,2。 取优先级3的任务并执行,发现节点1、4有父节点, 则执行中间节点1、2分别和节点6 Left Join得到根节点。 取优先级4的任务并执行,发布根节点。
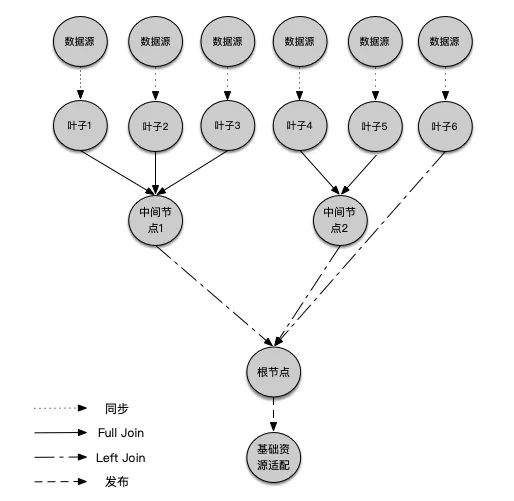
问题的解决由一系列不同优先级的任务组成, 任务需要复用。
通过从队列取优先级高的任务的方式构建任务关系树。
最后遍历树完成各个节点任务。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论