
基于同步行为的反欺诈算法SynchroTrap实现细节

上次分享了非常牛逼的不需要介质就能进行团伙挖掘的算法,大家都说是个好算法,但是实现细节还是有些问题。文章传送门:SynchroTrap-基于松散行为相似度的欺诈账户检测算法
一、梳理已有或者想应用的场景
用户A 2021-11-16 21:22:02 商家A 用户B 2021-11-16 21:32:02 商家A ······ 用户A 2021-11-18 11:18:02 商家B 用户B 2021-11-18 11:54:01 商家B
用户A 2021-11-16 21:22:02 活动A
用户B 2021-11-16 21:32:02 活动A
······
用户A 2021-11-18 11:18:02 活动B
用户B 2021-11-18 11:54:01 活动B
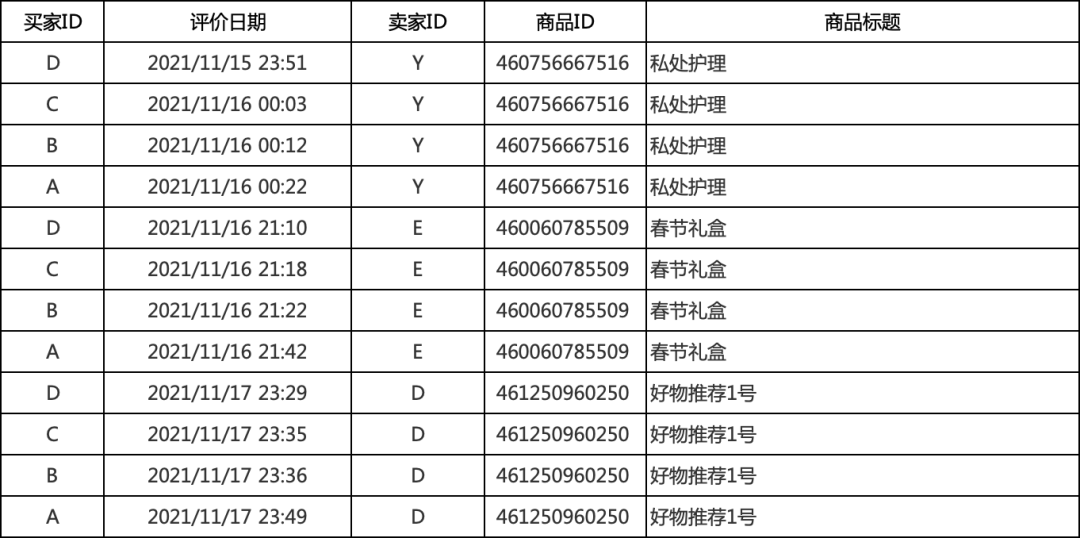
电商的评价环节
拼多多的砍价活动
抖音的点赞/关注
微信的投票
二、数据处理环节
1、首先我们需要做的就是把时间离散化(我按小时计算)
2021-11-16 00:03:32
20211115(23#00) 20211116(00#01)
import datetimedef Time2Str(tsm):t1 = datetime.datetime.fromisoformat(tsm)t0 = t1-datetime.timedelta(days=0, hours=1)t2 = t1+datetime.timedelta(days=0, hours=1)str1 = t0.strftime("%Y%m%d")+'(' +str(t0.hour).rjust(2,'0')+'#'+str(t1.hour).rjust(2,'0')+')'str2 = t1.strftime("%Y%m%d")+'(' +str(t1.hour).rjust(2,'0')+'#'+str(t2.hour).rjust(2,'0')+')'return str1+';'+str2Time2Str('2021-11-16 15:51:39')#测试下'20211116(14#15);20211116(15#16)'

import pandas as pddf = pd.DataFrame({'Buy':['BUY_03','BUY_02','BUY_01','BUY_04','BUY_03','BUY_02','BUY_01','BUY_04'],'Times':['2021-11-16 00:03:32','2021-11-16 00:12:23','2021-11-16 00:22:07','2021-11-16 21:10:24',\'2021-11-16 21:18:05','2021-11-16 21:22:02','2021-11-16 21:42:57','2021-11-16 23:51:39'],'Seller':['Y','Y','Y','E','E','E','E','Y']})# 时间离散化df['tsm'] = df['Times'].apply(Time2Str)
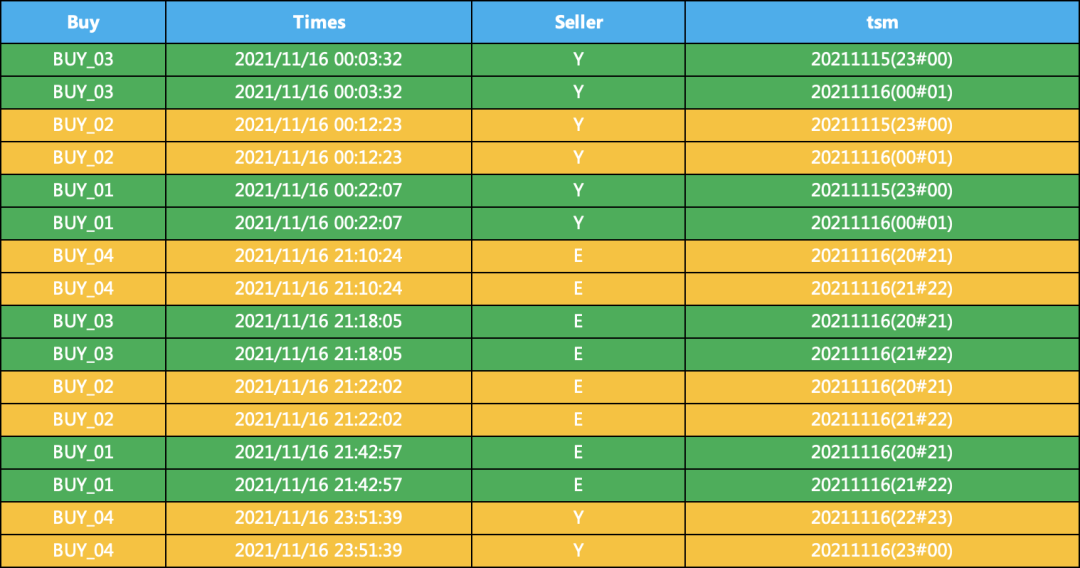
2、对数据进行裂变,一行变两行,这一步是关键,需要重点理解
df = df.set_index(["Buy", "Times",'Seller'])["tsm"].str.split(";", expand=True)\.stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "tsm"})print(df)
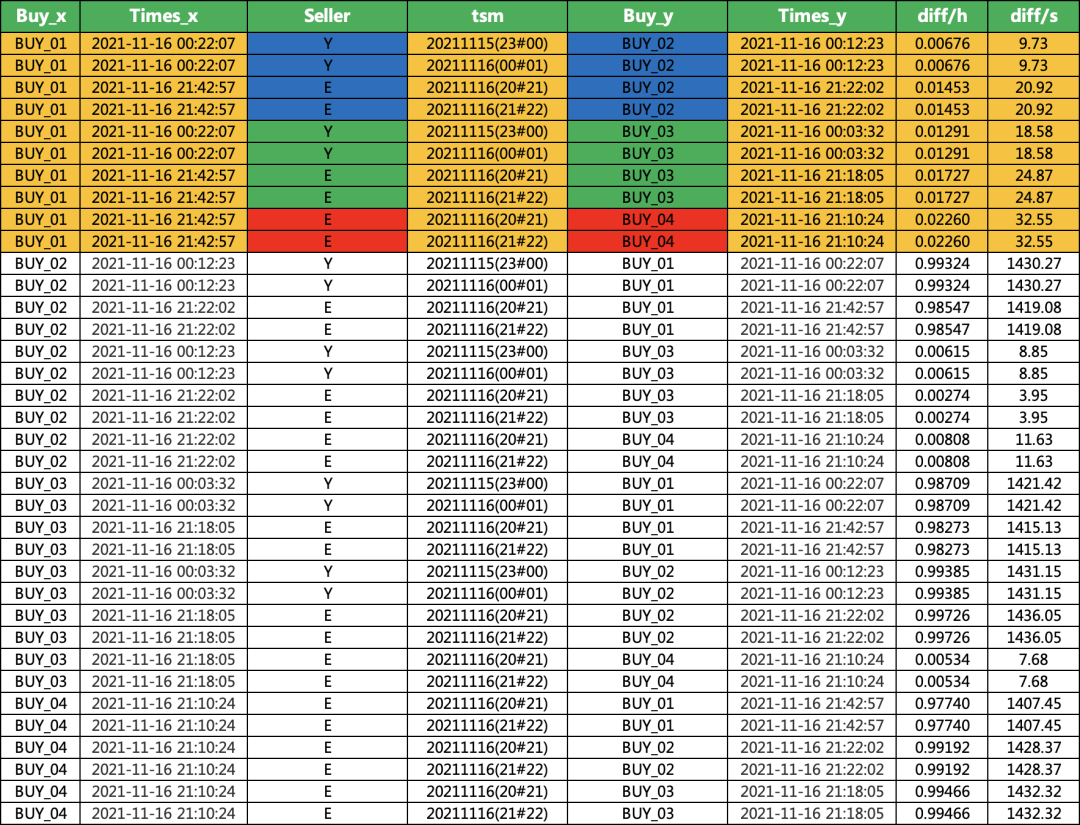
3、数据表进行自我匹配,并还需要作差,时间限定小于自己的阈值
df_0 = pd.merge(df,df,on =['Seller','tsm'],how='inner')df_1 = df_0[df_0['Buy_x']!=df_0['Buy_y']]df_1['diff'] = (pd.to_datetime(df_0['Times_x'])-\pd.to_datetime(df_0['Times_y'])).dt.seconds/3600/24
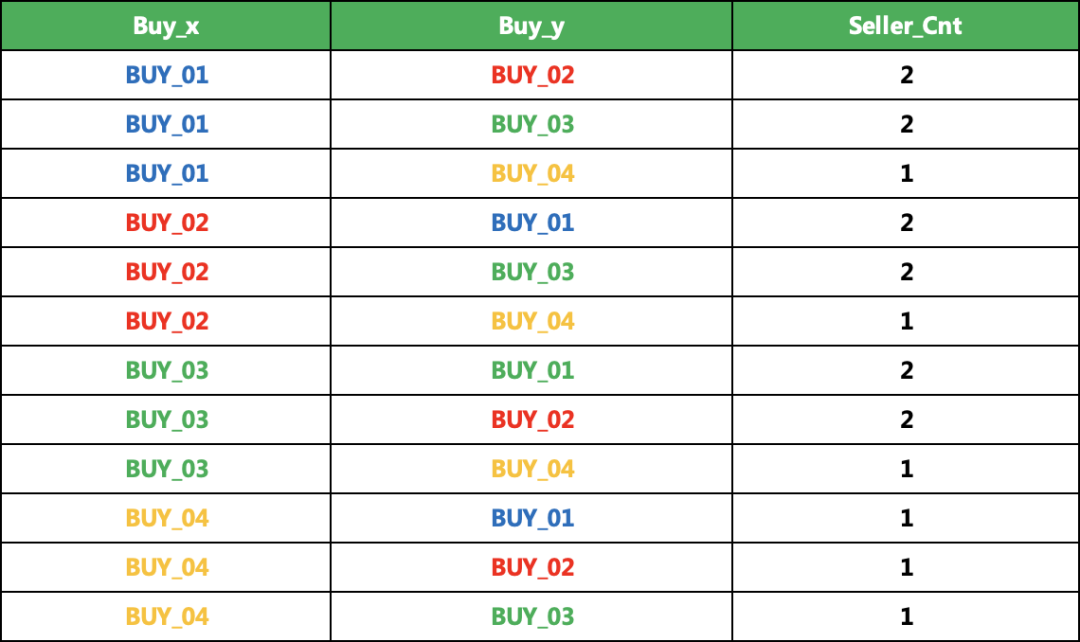
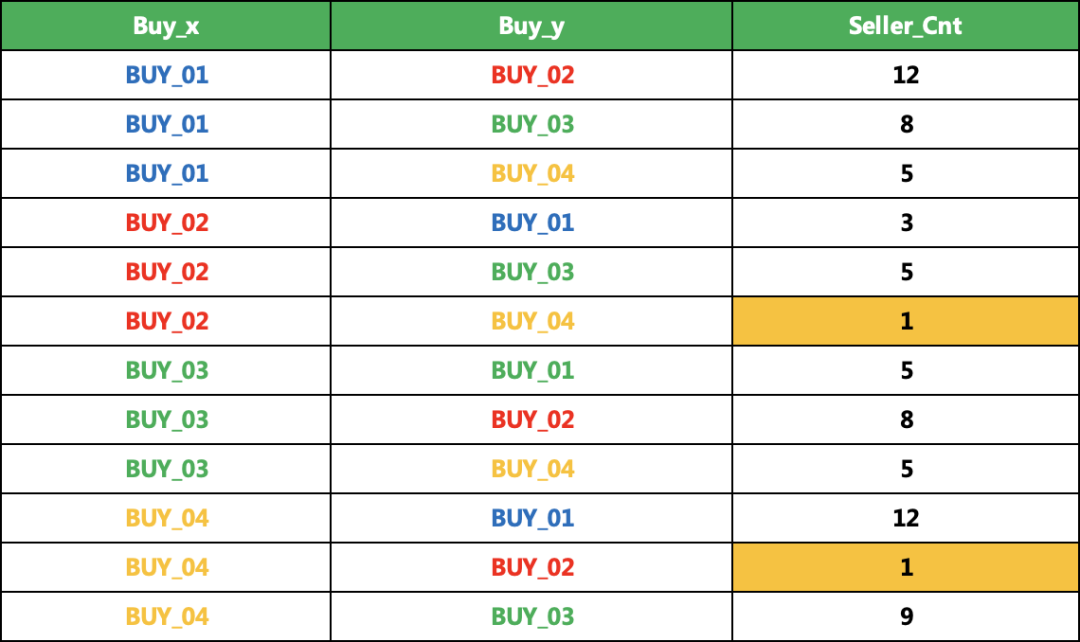
4、一天的数据聚合就得到下面的结果了
# 数据聚合df_1.groupby(['Buy_x','Buy_y']).agg({'Seller': pd.Series.nunique}).reset_index()
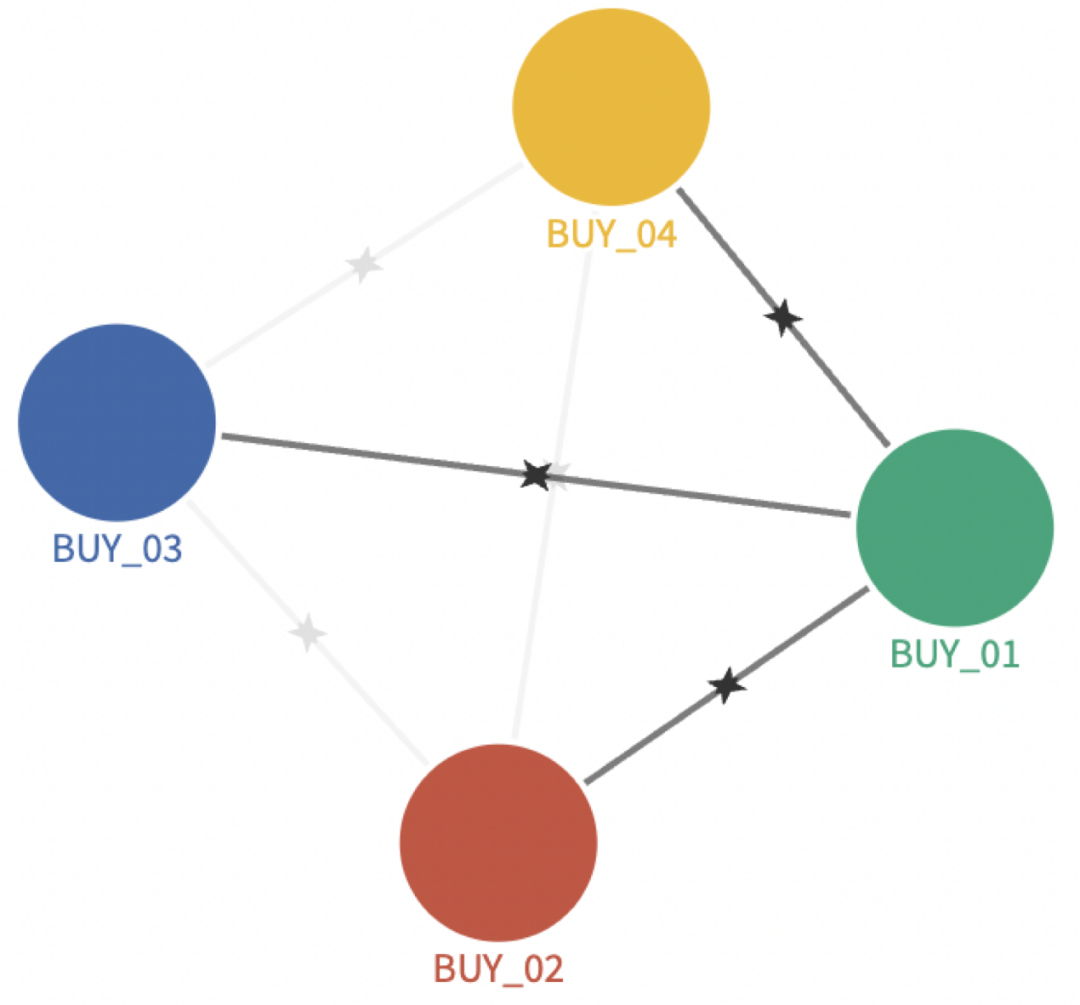
5、多天的数据聚合
6、总体相似度计算
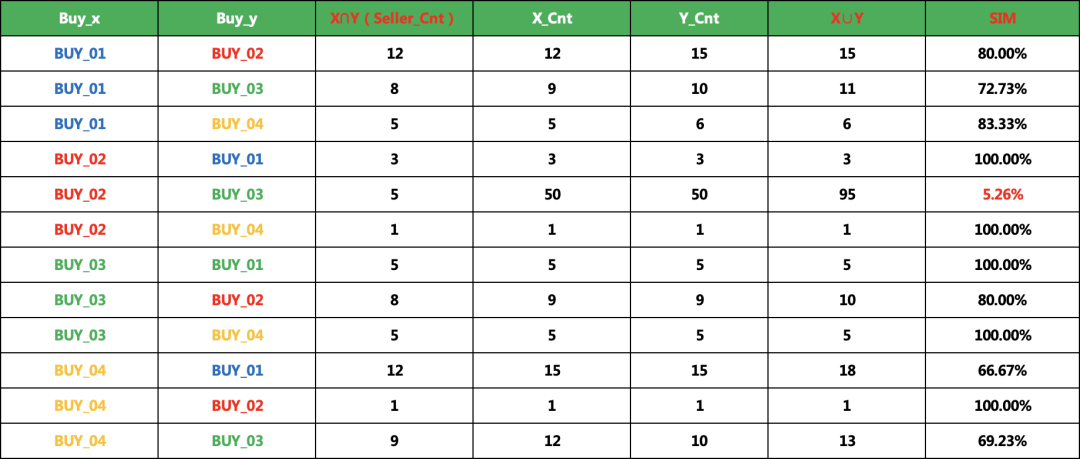
评论