
基于LightGBM算法实现数据挖掘!
对于回归问题,Datawhale已经梳理过完整的实践方案(可点击),本文对多分类的数据挖掘问题做了完整的方案总结。
一、赛题数据
赛题背景
本赛题是一个多分类的数据挖掘问题。赛题以医疗数据挖掘为背景,要求选手使用提供的心跳信号传感器数据训练模型并完成不同心跳信号的分类的任务。
实践地址:https://tianchi.aliyun.com/competition/entrance/531883/information
赛题介绍
任务:赛题以预测心电图心跳信号类别为任务 数据集: 10万条作为训练集; 2万条作为测试集A; 2万条作为测试集B; 对心跳信号类别(label)信息进行脱敏。

字段描述
id:为心跳信号分配的唯一标识 heartbeat_signals:心跳信号序列数据,其中每个样本的信号序列采样频次一致,长度相等(每个样本有205条记录)。 label:心跳信号类别(0、1、2、3)
评测标准
选手需提交4种不同心跳信号预测的概率,选手提交结果与实际心跳类型结果进行对比,求预测的概率与真实值差值的绝对值(越小越好)。
总共有n个病例,针对某一个信号,若真实值为[y1,y2,y3,y4],模型预测概率值为[a1,a2,a3,a4],那么该模型的评价指标abs-sum为 :


简单小结
根据赛题数据可以知道,此问题为「分类问题」,且为「多分类问题」,分类算法可以考虑,如「LR」、「贝叶斯分类」、「决策树」等等。 根据评测标准,每一个心跳样本都要输出4个类别下的概率值,所以可以用「逻辑回归LR」or 「贝叶斯分类」实现? 由于心跳信号自带明显的「时序特征」(心跳参数随时间变化),在后续的数据处理过程中要考虑「时序特征」所来来的影响? 根据评测公式,更关注的是「查准率」,即预测准确率越高,值就越小(模型得分目标)
根据初步理解,我会初步使用「逻辑回归LR算法」,给出每个分类下的概率值。
二、数据读取
Baseline文档可以粗略的划分以下几个部分:
工具包准备
import os
import gc
import math
import pandas as pd
import numpy as np
import lightgbm as lgb
# import xgboost as xgb
from catboost import CatBoostRegressor
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from tqdm import tqdm
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings('ignore')
工具包导入:pandas、numpy、sklearn、lightgbm等。
数据读取
path = '/Users/huangyulong/Desktop/心跳信号分类预测'
train_csv = '/train.csv'
testA_csv = '/testA.csv'
train = pd.read_csv(path + train_csv)
test = pd.read_csv(path + testA_csv)
查看数据集与测试集
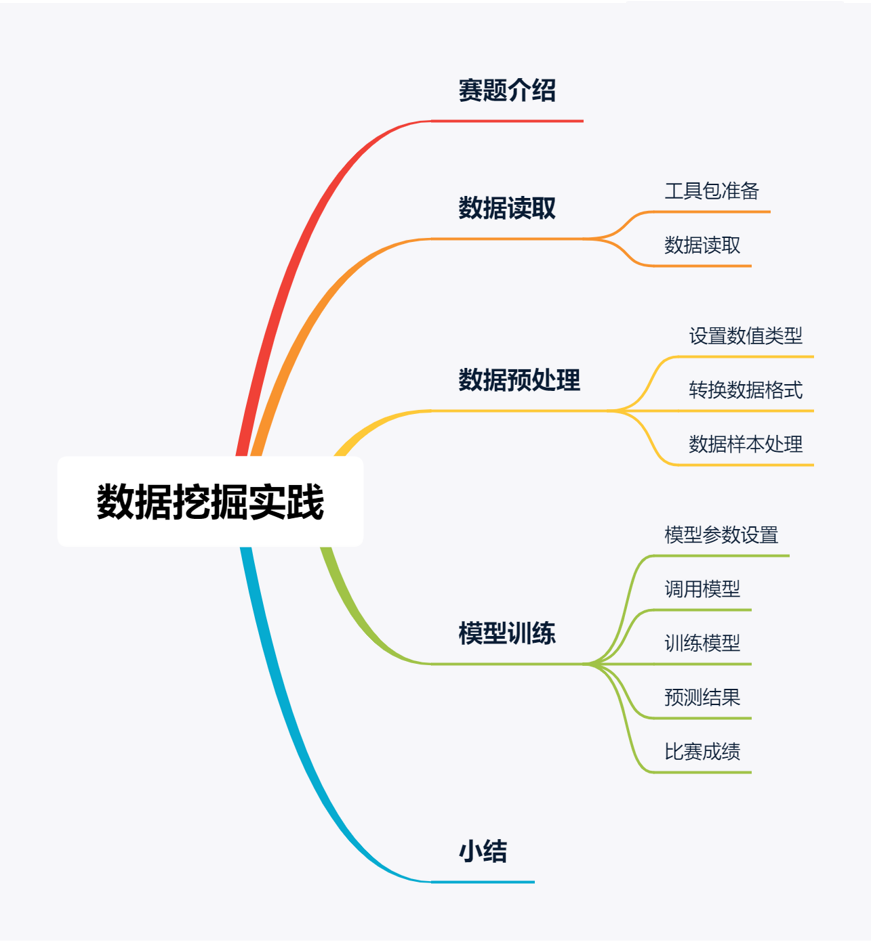
train.head()

test.head()
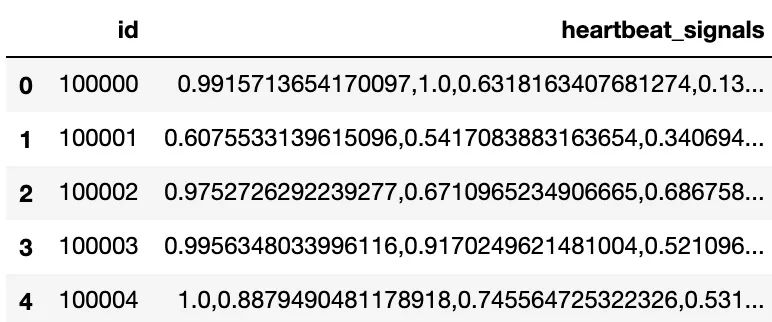
4种心跳信号特征:
signal_values = []
for i in range(4):
temp = train[train['label']==i].iloc[0, 1].split(',')
temp = list(map(float, temp))
signal_values.append(temp)
signal_values = np.array(signal_values)
color = ['red', 'green', 'yellow', 'blue']
label = ['label_0', 'label_1' ,'label_2' ,'label_3']
plt.figure(figsize=(8, 4))
for i in range(4):
plt.plot(signal_values[i], color=color[i], label=label[i])
plt.legend()
plt.show()
数据整体信息:数据类型、是否有缺失值等
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100000 entries, 0 to 99999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 100000 non-null int64
1 heartbeat_signals 100000 non-null object
2 label 100000 non-null float64
dtypes: float64(1), int64(1), object(1)
memory usage: 2.3+ MB
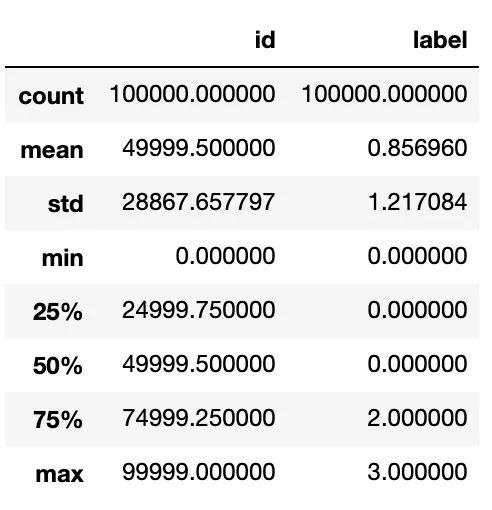
数据统计信息:均值、标准差、中位数等等。
注:这里面只能统计ID、label列;因为heartbeat_signals数据不符合格式。
train.describe()
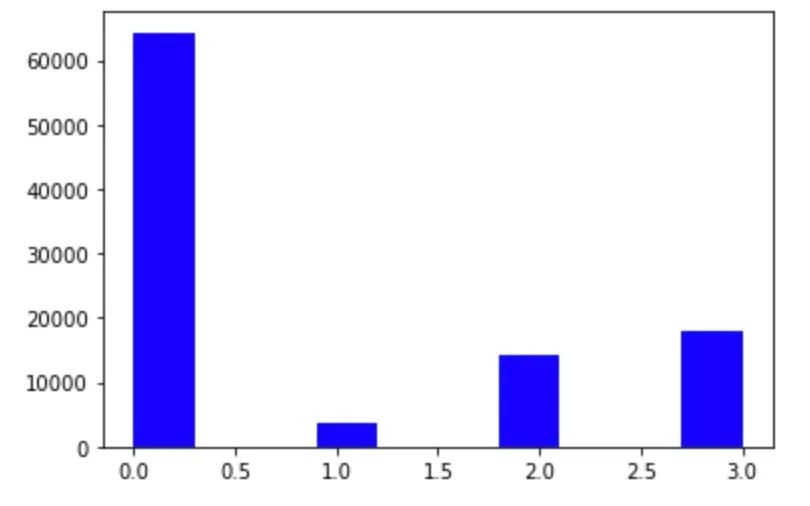
4种心跳信号类别在数据集中占比情况:
train['label'].value_counts()
0.0 64327
3.0 17912
2.0 14199
1.0 3562
Name: label, dtype: int64
三、数据预处理
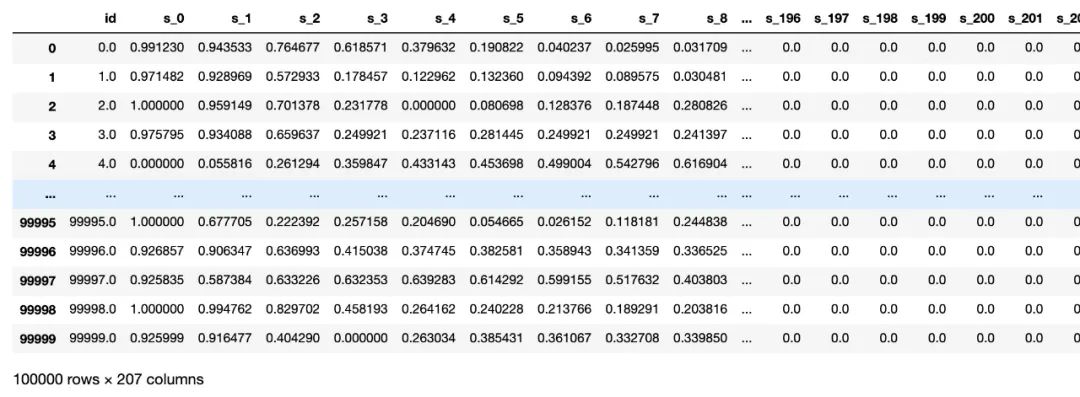
由于原始数据中,heartbeat_signals 列存储了205条信息,所以要把这一列数据转化成方便读取、易于使用的格式:比如构建205列。
train_list = []
for items in train.values:
train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])
train1 = pd.DataFrame(np.array(train_list))
train1.columns = ['id'] + ['s_'+str(i) for i in range(len(train_list[0])-2)] + ['label']
train1
设置数值类型
设置每列数值的「数值类型」:由每列的最大值和最小值来确定。
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
转换数据格式
将「字符串」转为「浮点数」
train_list = []
for items in train.values:
train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])
train2 = pd.DataFrame(np.array(train_list))
train2.columns = ['id'] + ['s_'+str(i) for i in range(len(train_list[0])-2)] + ['label']
train2 = reduce_mem_usage(train2)
test_list=[]
for items in test.values:
test_list.append([items[0]] + [float(i) for i in items[1].split(',')])
test2 = pd.DataFrame(np.array(test_list))
test2.columns = ['id'] + ['s_'+str(i) for i in range(len(test_list[0])-1)]
test2 = reduce_mem_usage(test2)
数据样本处理
训练数据样本与测试数据样本
#训练样本
x_train = train2.drop(['id','label'], axis=1)
y_train = train2['label']
#测试样本
x_test = test2.drop(['id'], axis=1)四、模型训练
1、评估函数
评测公式(损失函数):
def abs_sum(y_pre,y_tru):
y_pre=np.array(y_pre)
y_tru=np.array(y_tru)
loss=sum(sum(abs(y_pre-y_tru)))
return loss
2、模型参数设置
n_splits : int, default=3 shuffle : Whether to shuffle the data before splitting into batches. random_state : When shuffle=True, pseudo-random number generator state used for shuffling. If None, use default numpy RNG for shuffling.
3、one-hot编码
而我们的分类结果是为了得到隶属于某个类别的概率,所以这里采用「one-hot编码」。
sparse : Will return sparse matrix if set True else will return an array.(为True时返回稀疏矩阵)
模型参数设置
def cv_model(clf, train_x, train_y, test_x, clf_name):
folds = 100
seed = 2021
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
#设置测试集,输出矩阵。每一组数据输出:[0,0,0,0]以概率值填入
test = np.zeros((test_x.shape[0],4))
#交叉验证分数
cv_scores = []
onehot_encoder = OneHotEncoder(sparse=False)
#将训练集「K折」操作,i值代表第(i+1)折。每一个K折都进行「数据混乱:随机」操作
#train_index:用于训练的(K-1)的样本索引值
#valid_index:剩下1折样本索引值,用于给出「训练误差」
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
if i < 7:
#打印第(i+1)个模型结果
print('************************************ {} ************************************'.format(str(i+1)))
#将训练集分为:真正训练的数据(K-1折),和 训练集中的测试数据(1折)
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
#LGB模型
if clf_name == "lgb":
#训练样本
train_matrix = clf.Dataset(trn_x, label=trn_y)
#训练集中测试样本
valid_matrix = clf.Dataset(val_x, label=val_y)
#参数设置
params = {
'boosting_type': 'gbdt', #boosting方式
'objective': 'multiclass', #任务类型为「多分类」
'num_class': 4, #类别个数
'num_leaves': 2 ** 5, #最大的叶子数
'feature_fraction': 0.9, #原来是0.8
'bagging_fraction': 0.9, #原来是0.8
'bagging_freq': 5, #每5次迭代,进行一次bagging
'learning_rate': 0.05, #学习效率:原来是0.1
'seed': seed, #seed值,保证模型复现
'nthread': 28, #
'n_jobs':24, #多线程
'verbose': 1,
'lambda_l1': 0.4, #新添加 L1
'lambda_l2': 0.5, #新添加 L2
'min_data_in_leaf':100, #叶子可能具有的最小记录数
}
#模型
model = clf.train(params,
train_set=train_matrix, #训练样本
valid_sets=valid_matrix, #测试样本
num_boost_round=10000, #迭代次数,原来为2000
verbose_eval=100, #
early_stopping_rounds=500) #如果数据在500次内没有提高,停止计算,原来为200
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
val_y = np.array(val_y).reshape(-1, 1)
val_y = onehot_encoder.fit_transform(val_y)
print('预测的概率矩阵为:')
print(test_pred)
#将预测结果填入到test里面,这是一个「i个模型结果累加过程」
test += test_pred
#评测公式
score = abs_sum(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
#下面公式是什么含义呢?为啥要除以「K折数」?:i个模型输出结果的平均值。
test = test / 7
return test
调用模型
def lgb_model(x_train, y_train, x_test):
lgb_test = cv_model(lgb, x_train, y_train, x_test, "lgb")
return lgb_test
训练模型
lgb_test = lgb_model(x_train, y_train, x_test)
预测结果
temp = pd.DataFrame(lgb_test)
result=pd.read_csv('sample_submit.csv')
result['label_0']=temp[0]
result['label_1']=temp[1]
result['label_2']=temp[2]
result['label_3']=temp[3]
result.to_csv('submit1.csv',index=False)
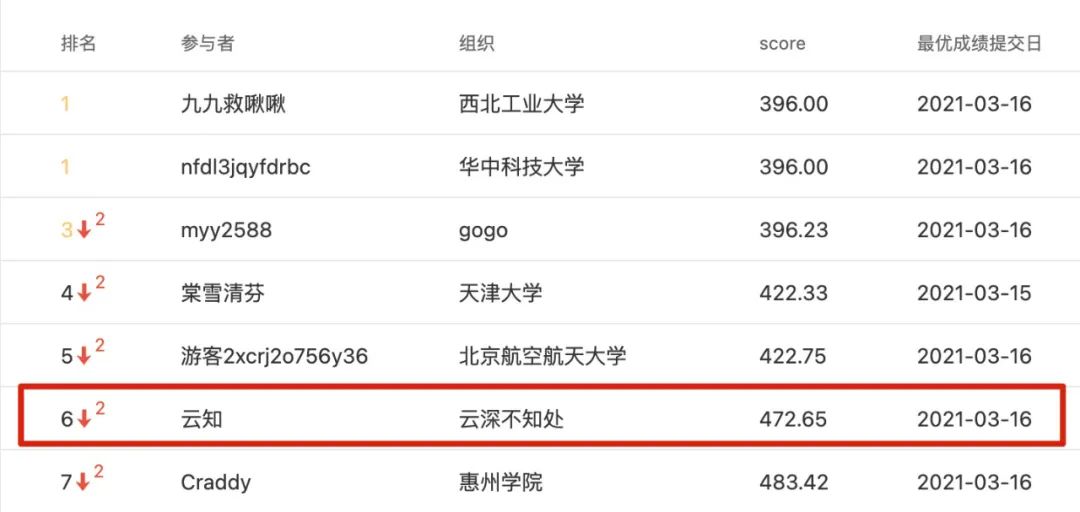
第一次天池学习赛分数
将最终的预测结果上传到学习赛,给出结果值!
五、思考
评论