
微信支付基于图计算的反欺诈实践

来源:DataFunTalk 本文约5800字,建议阅读10分钟 本文为大家分享一些关于图计算应用的经验。
[ 导读 ]微信支付作为一个国民级工具,用户量级很大,而且用户黏性也很强,这么多用户每天在用,就会产生大量的交易、连接。黑产对技术的嗅觉是非常灵敏的,如果一个产品连黑产都没有关注的话,那这个产品很难称之为好产品。
我们每天也和微信支付大量的黑灰用户对抗,而且是在一个十亿结点,万亿边的网络进行对抗,因此我们需要用到网络化的利器:图算法和图数据库。这次分享,希望把我们之前的图计算应用的一些经验,还有一路走过的坑,跟各位分享。主要内容包括:① 风控新视角;② 图计算平台;③ 支付的实践;④ 科技向善成果。
01 风控新视角
1. 风控的全新视角:各种骗术层出不穷
最近有一位国外的马老师(马斯克)很火,虽然他的产品在国内争议非常大,但是在美国,捧谁谁火,比如狗狗币推成天狗,带货能力非常强,这种一夜暴富的情绪传到国内,会发现如果平时聊天不聊“币”,可能跟朋友就聊不下去了。所以最近发现诈骗份子利用这一点,推出各种比如空气币传销币等,这些都是新型的资金盘,也成了我们最近风控反诈的热点。
2. 特征工程还是网络工程
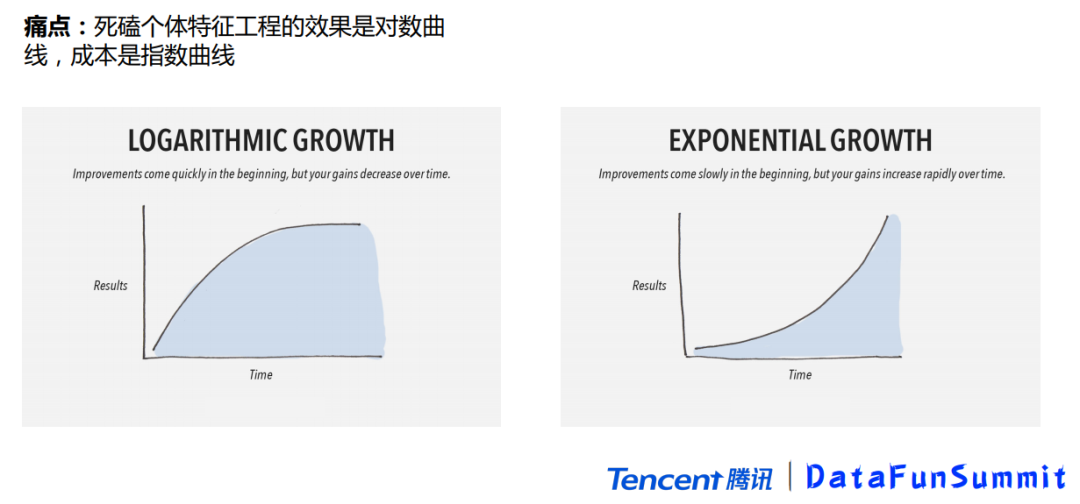
正因为有各类层出不穷的新型诈骗手法,我们马上就会碰到一个痛点:用户画像、特征工程不好使了,以我们微信支付为例,我们这么多年也是在不断的往上堆特征,特征数量已经达到了6位数,这时你会发现特征堆积的越多,效果提升的其实并不明显,这是第一个问题,另一个问题是,特征堆积的越多,成本会越高,如右图的指数曲线一样。
举个用户画像的例子,比如研究一个人的消费习惯,之前按照天分析,后来会按小时去分析,或者说发现两个画像特征特别有用,会考虑把两者结合起来,做一个交叉特征,这样特征数量也会涨的特别快,特征数量增长会带来很多问题,首先是存储的问题,还有特征管理的问题,包括配置特征告警、特征稳定性、生命周期等等,这一系列的配套工程会让我们的成本越来越高,所以从个体的特征工程到全局的网络工程的转变,会给我们带来新的视角,新的知识。
3. 网络视角:个人 vs 团伙

另外一个视角是我们看待黑产是个体还是团伙,以前我们印象中黑产可能是一个非常聪明、技术非常好的独来独往的黑客,深谙SQL注入、DDOS攻击等技术,通过各种手段敲诈勒索很多钱。实际上从警情案例来看,黑产大多是右图的这种情况:团队有很多顶尖的技术人才、甚至还有北大毕业的、不少黑产躲在山沟里办公,反侦意识很强,黑产头目很会打鸡血,内部分工明确,还有大量的手机卡、猫池,身份证和银行卡等作案工具。互联网崇尚合作,所以现在黑产更多的是团伙作案,所以我们就需要从个体视角转换到团伙视角,而且要相信团体能量远比个体大得多。
拿我们自己举个例子,如果我们只关注个人的技术成长,我们对行业,对社会的影响力就比较小,但如果我们有勇气走出去,和外界建立更多的连接,我们对社会的影响力就大,这里也感谢DataFun提供这么好的平台,让我们能跟更多的同行建立起连接。
4. 网络建设:点线面怎么铺开
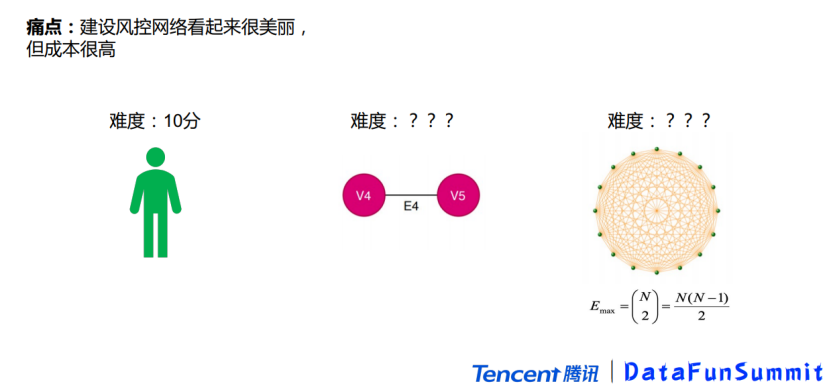
既然对抗新形势下的风控需要用网络去做,问大家一个问题,大家觉得理解网络难不难?如果研究一个个体难度为10分,大家觉得研究一个关系对难度是多少分?答案是100分,因为是两两之间产生互动,特征产生交叉,所以是10*10=100分。如果是一个100人的团伙,研究网络难度最大是多少?答案大概是100分乘以10000倍,因为是100个结点的全连通图最多会形成9900条边。即便对于这种节点数不多的图,研究网络的难度可以是研究个体的难度的10万倍,所以我们研究网络时,既要认识到它对风控有巨大的收益,也要理解研究网络难度是非常大的。
02 图计算平台
主要介绍微信支付图数据平台的建设和经验。
1. 微信支付图数据计算平台:三驾马车
图数据计算平台有三驾马车,第一驾马车是图计算引擎,第二驾马车是存储引擎,也就是图数据库,第三驾马车是算法设计,也就是是针对业务去设计算法。
2. 微信支付合作共建的图计算平台
安利两个好用的图计算平台,都是腾讯开源且在GitHub高星的项目,一个是Angel,一个是Plato(柏拉图),我们都有参与共建。
Angel是一个通用的、完整的大数据平台,不仅有图算法,还有传统的机器学习算法,是一个非常通用的计算平台,也是Apache的一个顶级项目。
Plato是微信部门自己研发的专注图计算的平台,底层借鉴了Gemini等优秀的图计算系统设计。
这两个平台都有相应的开源项目,大家可以下载使用。对于大多数公司来说,开箱即用就会有一个比较好的效果,而且他们技术咨询服务也做的不错。
3. 图计算平台:为什么速度是第一考虑

这里分享一个经验:我们在选用图计算平台时,首先考虑的是速度,其次是不折腾。举一个我自己日常跑算法的例子:在某个风控场景针对某一批数据样本训练某一个图算法,就需要做大量实验(用不同的参数组合,如图所示),还不包括前面的预演和后面的上线。第一个实验的第一轮花费3000多秒,也就是大概一个小时,到最后第七组的实验参数,50轮花了大概8到10个小时,所以可以看到在做算法实验的时候,如果没有好的计算平台保证运行速度,就很难得到一个较优的结果。
比如图中的上半部分,训练的轮次越多,效果反而越差;而我们期望是得到下半部分的结果:随着训练迭代次数增加、效果越来越好,但这种参数组合可能要实验非常多次才能得到。这也告诉我们图算法上限是非常高的,需要反复不断去尝试才能把它用好,因此计算速度是摆在第一位的。
4. 图数据库:高效分析案例的利器
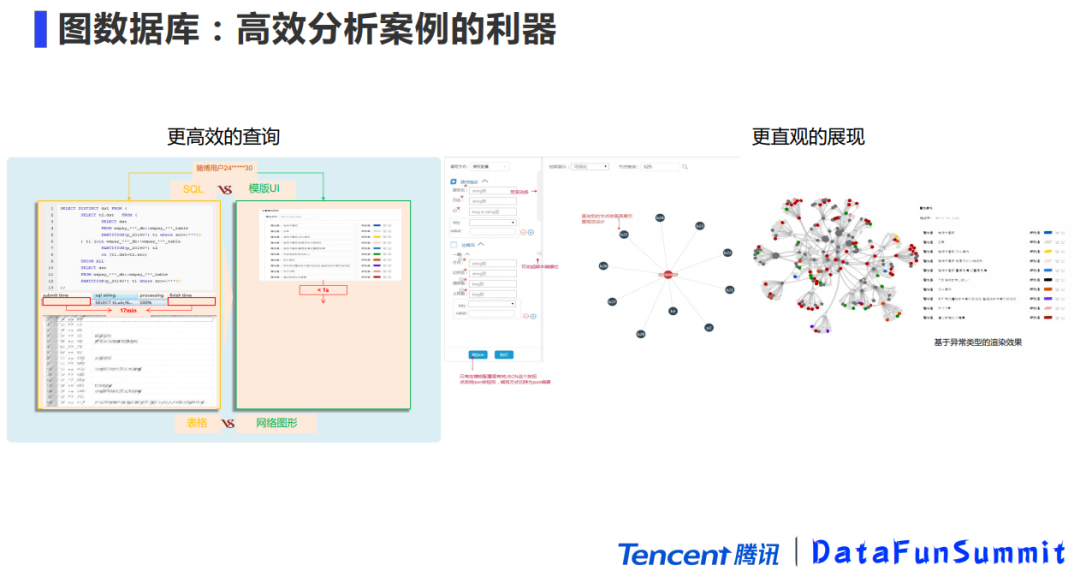
我们之前跟公司的Angel团队合作共建了腾讯的图数据库EasyGraph,它可以做到更好的查询和更直观的展现,这样我们分析案例,特别是挖掘团伙就非常方便了。
举个例子:左边是我们日常写SQL去跑,花了17分钟,右边使用图数据库查询,只花了1秒钟,而且把关系网络做了非常直观的展现,EasyGraph底层是借鉴S2Graph图数据库进行开发的,这是我们内部使用的其中一个图数据库;外部的图数据库个人推荐的是TigerGraph,我们通过支付的数据去对比市面上的几款图数据库,TigerGraph无论是单机还是分布式模式,性能都是很优秀的。
5. 图算法设计:基于业务去思考和创新
图算法设计方面,我们主要做了以下探索:包括团伙识别、图神经网络、传播染色、异常检测,这几类算法都是针对我们自己的业务去思考和创新的。
03 图计算的实践
1. 样本增强
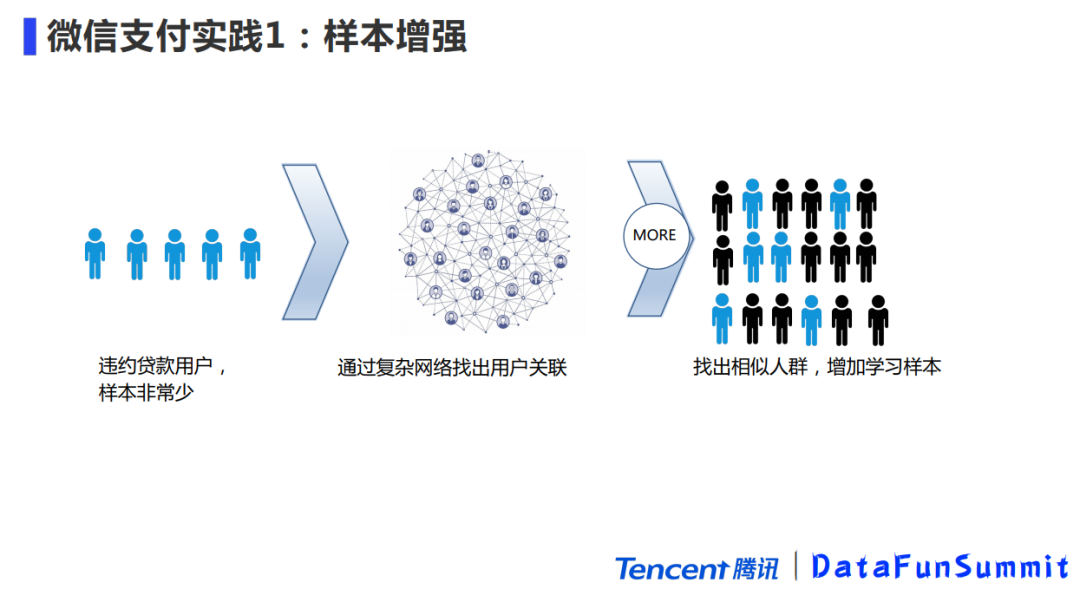
我们平时参加Kaggle算法竞赛,比较头疼的是样本通常很少;对于风控场景的建模,这个问题可能更加严重:样本少,或者很难收集到高质量的样本,就算在外面购买,质量也不一能保证或者适用我们的场景,但是风控场景的复杂性本身又需要大量的数据才能学习到好的模型,一个数据增强的好办法就是通过网络关系去实现。吴军曾经提到Google挖了一位做NLP的教授,任务是提高中日英翻译的准确率,他的做法跟以前优化模型的思路不一样,不断搜集数据,拿到比以往建模多一万倍的数据,这让他一下领先了第二名5个点,而此前每年的进步大概是0.5个点,换言之他已经领先第二名十年,这就是样本增强的一个价值。
所以遇到样本少的情况,可以通过复杂网络做一个”lookalike”,找出跟样本相似的用户,这往往对训练模型有很大的帮助。
2. 传播染色
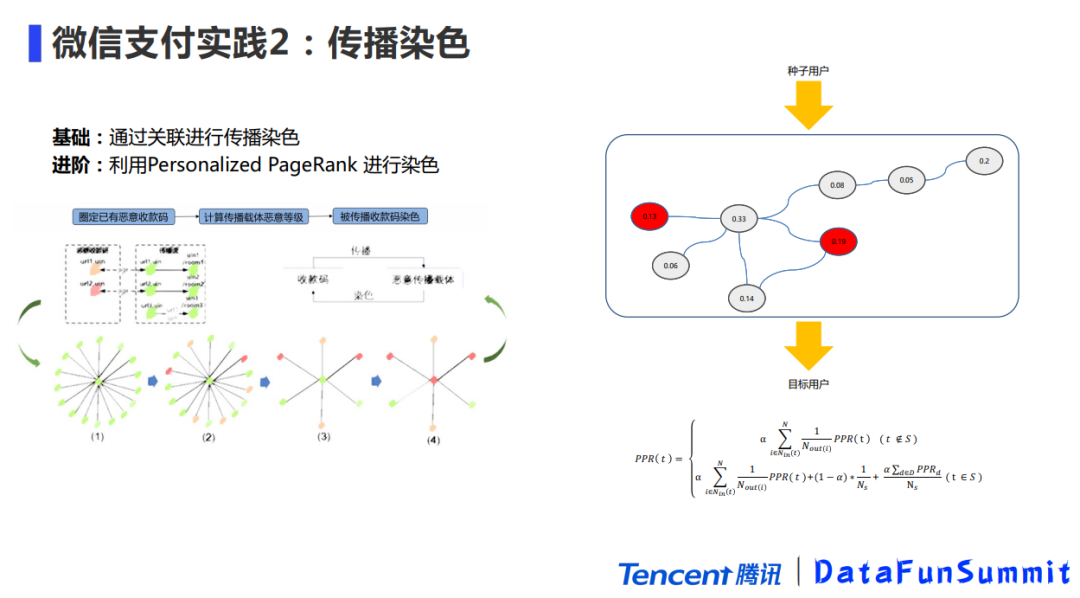
跟传播有关的算法,最著名的应该是PageRank了,一个算法让Google从一个很小的公司变成了互联网巨头。举个身边传播染色的例子,有位同事发现最近门禁扫脸的时候经常扫不出来,因为比入职的时候长胖了一圈,互联网员工长胖的原因通常都是因为加班多,人一到晚上自控力就会降低,很难拒绝高卡路里的食物,一开始我们招呼他去吃炸鸡他也是拒绝的,但最后变成是他最积极了。所以说坏习惯传播的是非常快的,如果你在一个群体里,有很多习性不好的人,你可能很容易被影响。我们在风控场景做传播,染色扩散的时候会用到这样的思想。以前反赌的同事会去赌博平台收集一些恶意的二维码,然后通过这些二维码去做传播、染色扩散,然后挖掘到更多的人和二维码,后来我们自研了一套Personalized PageRank算法,对黑灰种子用户进行扩散,效果也非常好,大家可以在网上搜一搜这个算法。
3. 基于时序的异常挖掘
基础版:
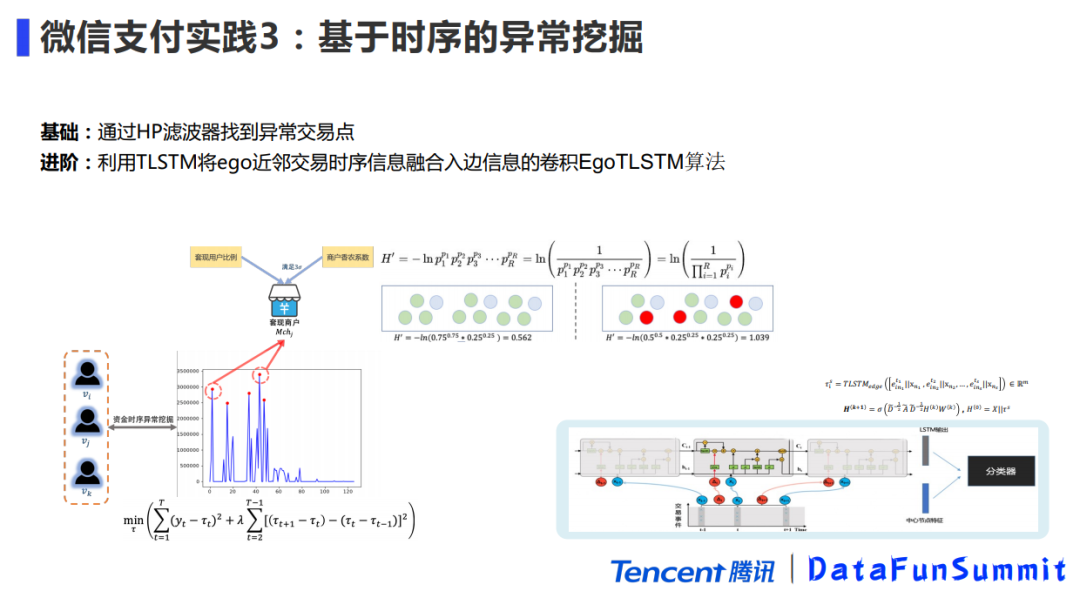
举一个挖掘套现商户/用户的例子,套现商户有一个明显的特征:对于一个线下面对面商户,交易对象的地域应该是比较固定的(比如卖煎饼果子的小商家,付款方都是附近的居民和上班族),但如果一个线下面对面商家是涉及套现的,他的交易对象就有比较明显的地域多样性,这个多样性可以用香农系数来定义,一般套现商户的香农系数比正常的商户大很多(一般是3个标准差)。找到高置信的套现商户后,我们再分析跟这些商户交易过的用户过去120天的消费支出,通过HP滤波器发现交易异常点,如果这些交易异常点恰好是在异常商户消费,通过一定的累计命中次数就可以说明他是一个高置信度的套现用户,这种是比较传统的时序挖掘。
进阶版:
但HP滤波器毕竟是一种非参数方法(非参数方法在具体应用中不可避免地依赖于调节参数),如果HP滤波器过于粗糙,我们可以通过T-LSTM融合时序信息同边信息做卷积,结合ego network的概念,自研了新的算法EgoTLSTM,这样就解决了HP滤波器的问题。
4. 团伙快速挖掘
团伙挖掘也是风控中比较重要的工作,我们的工作也分为基础版和进阶版
基础版:
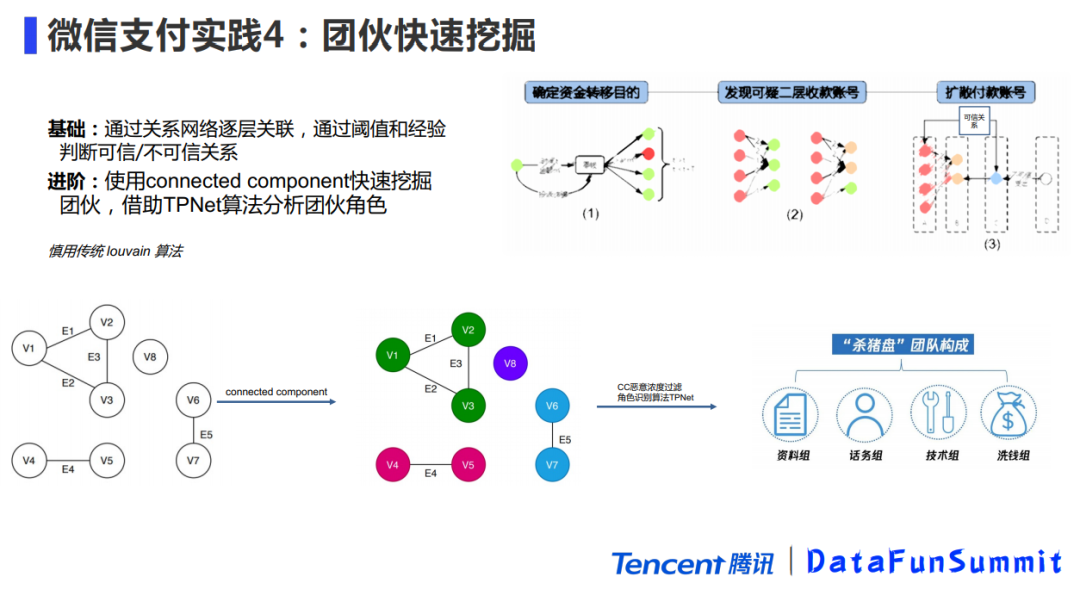
基础版比较简单但比较耗时,也就是通过网络去关联更多的用户。举个例子,我们可以针对一批高恶意样本,去挖掘他们的资金关系链,通过各种关系(资金,证件,设备,环境等)去扩散,再通过一些可信关系去做过滤,通过观察用户的资金流向,挖掘出相关的团伙和并找出涉及资金较大的头目。
进阶版:
进阶版是用了一个简单实用的方法:connected component,目前用到的是无方向的弱的连通图,这种算法可以快速把网络划分为一个个小的连通子图,再计算子图的密度或者聚集系数进行后过滤,得到的连通子图就会是一个关系紧密的小团伙,最后通过我们自研的TPNet这种角色识别算法就可以得到团伙里面的成员构成。比如一个杀猪盘中就包括了资料组、话务组、技术组和洗钱组,可以看到团伙不仅关系紧密且分工是比较明确的。
顺便补充一点,我们经常接触的Louvain算法,在大数据下很容易形成怪物社区,在业务中较少用到。
5. GNN在设备网络的应用
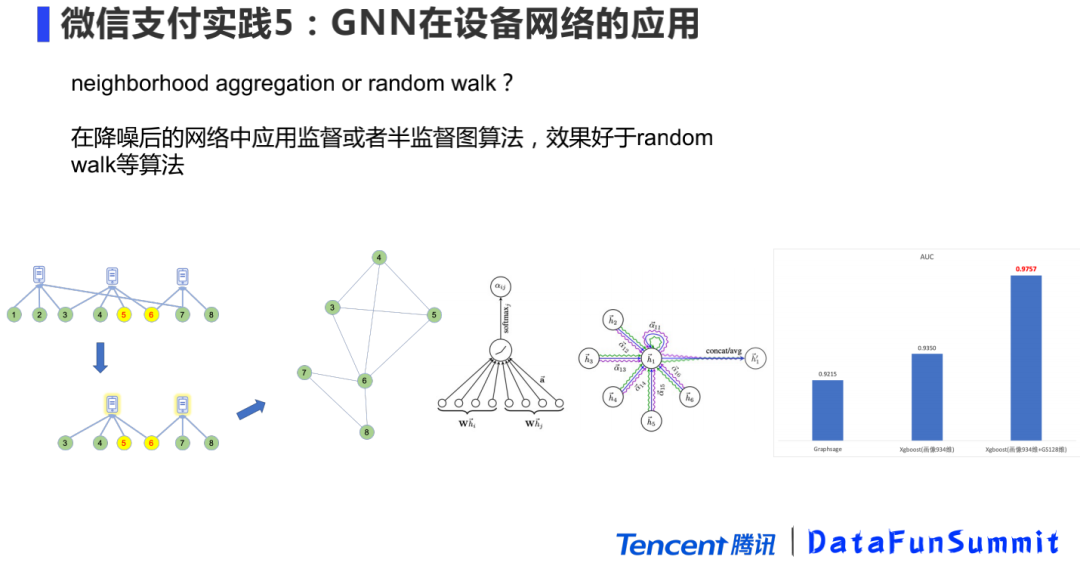
用户-设备网络在我们支付各种风控场景中的应用效果也是非常好的,大家也可以去搜索腾讯、阿里相关的论文,无论在交易欺诈,恶意账号识别,用户-设备二分网络都是非常有用的,原因是用户的设备是比较私人且有成本的,而人与人的连接往往带有大量的随机性。但是构建设备网络也是要降噪的,不仅是对边的降噪,也包括节点的降噪,包括剔除山寨机这类有噪音的节点。
图神经网络算法一般分为两种,一种是random walk ,比如大名鼎鼎的node2vec,另一种是neighborhood aggregation 比如GAT,Graphsage,我们比较推荐使用邻居汇聚这种算法,因为有监督的学习我们比较好把握优化的方向。举个例子,下面这个图有1到8个点,5,6是标注的异常的点(因为图计算都是半监督学习,所以我们也需要做一定的标注),然后1,2这两个点跟他们是多跳关系,可以去掉,这就是做了一步降噪。我们跑图算法,最终还是要把一个异构图变成一个同构图的,如上图,这个例子虽然只减少了2个节点,但生成同构图的边可能会少一半。通过实验对比,如果只用GNN来跑有监督学习的话,AUC是0.92,比XGBoost跑画像特征得到的0.93稍差,但如果把GNN学习到的个体Embedding拼接到原有的画像特征,再跑XGBoost,AUC会有大幅度提升至0.97,这也说明了网络结构特征能给原有的个体画像特征带来明显的增益。
6. 团队在图算法的探索和创新
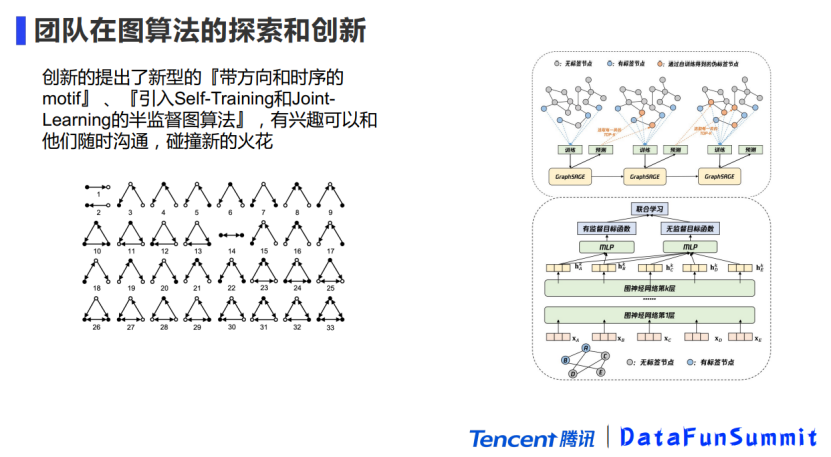
再讲讲我们的团队,他们都是一些很聪明的,来自于南洋理工、香港理工和北大清华的博士,他们也有很多新的想法,比如说motif是一个没有方向的东西,但是我们同事就把他变成了一个有方向的,还附带了时序,比如说左图的第3个motif是一个套现特征。另外一个创新是我们同事针对支付网络优化GNN,引入了Self-Training 和Joint-Learning两个半监督图算法,综合得到一个效果更好的图算法(如右图所示)。
04 科技向善成果
最后展示一下我们科技向善的成果。上市公司对股东的承诺都是保证收入、利润的增长。但今年不太一样,公司投入了非常大的资源,甚至专门成立一个科技向善的部门,希望通过互联网技术,让这个世界效率更高,社会变的更公平。所以我们做了很多事情,协助国家开展反诈反赌反洗钱等工作,去帮助很多弱势群体,我们也收到了大量感谢信和感谢锦旗。我们身处其中,感受到非常强的使命感和意义,希望以我们的技术所长为弱势群体多做一些事情。
05 问答环节
Q:老师用的是什么图数据库?
A:用过两种图数据库,一种是底层基于S2Graph开发的,我们内部叫Easygraph, 经过3年打磨,已经优化的非常好,界面也很友好,但目前仅限于内部使用,如果是外部的话可以考虑TigerGrpah,还有一个叫Nebula Graph,体验也不错,也是开源的,推荐去试试。
Q:图是同质还是异质的?
A:在微信支付来说,很多有用的图都是异构的,比如人和物,比如说用户和商户是一个异构关系,用户和设备在风控好用的网络,这也是异构的,但是在做算法的时候,会先把异构图变成同构图。
Q:为什么异构图要转成同构图?
A:因为异构图算法不好跑,甚至很多算法本身虽然可以接受异构图数据的输入,但是内部他也需要转化成同构图才能执行,比如说GNN,在跑GNN的时候需要把用户和设备转成用户和用户之间的连接,因为设备只是起到一个媒介的作用,关键是我们看用户和用户之间的关联。图的问题都是半监督的问题,相对于网络来说,我们只有很少量的样本,需要从这少量的标注样本中在网络中找到更多相似的样本。刚刚有朋友也问到了怎么做样本增强,我们其实也可以通过这种方法,去半监督学习,找到更多相似样本(有关系且预测概率相近),就能做到样本增强了。
Q:反洗钱方面应用
A:反洗钱方面有刚刚提到的资金盘,资金盘其实涉及到传销反洗钱,涉及到使用USDT,现在很多洗钱都是通过USDT去走,还会涉及到二维码、银行卡,我们这里的话会通过很多关系的数据,先建立一个纯度高的网络,然后用 WCC,就是不考虑方向的connected component, 得到一个个小团伙之后,再用角色识别算法区分它们的角色。比如说在一些虚拟币、租码跑分平台,是属于国家管控洗钱领域的,这些平台我们是有进行反洗钱打击的,把里面的号该封封了,该处置的号处置了,该上策略上策略,这就是反洗钱的其中一个应用。
Q:GNN的降噪
A:图(参GNN在设备网络的应用ppt图)本来这个网络是有1到8的节点,但是不需要那么多,因为有一些点没有跟我们标注的样本节点产生直接的联系的话,是可以直接把它剔除的,这样的话整个网络纯度会高一些,有可能会牺牲一些召回率,但这个问题不大,因为我们做了一轮后有可能会得到更多的样本,得到更多的样本后再持续标注和分析可以得到更多新的样本。
编辑:王菁
校对:林亦霖