
关键信息抽取【2】——体验篇
基本原理可以先看下文
Damon,公众号:人工智障与神经病网络研究所关键信息抽取【1】——初识篇
1. 环境准备
- Python版本:3.10.12
- 硬件:win11,CPU
# 构建Conda虚拟环境
conda create --name py310_paddle python=3.10.12
# 激活虚拟环境
conda activate py310_paddle
# 准备paddlepaddle
python -m pip install paddlepaddle==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 准备PaddleOCR和PP-Structure环境
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
pip install -r requirements.txt
pip install -r ppstructure/kie/requirements.txt
pip install paddleocr -U
2. 下载预训练模型文件
在./PaddleOCR/ppstructure下,创建一个weights文件夹,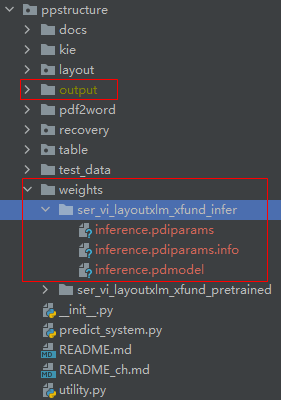
cd PaddleOCR/ppstructure
mkdir weights
cd weights
# 下载并解压SER预训练模型
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar && tar -xf ser_vi_layoutxlm_xfund_pretrained.tar
# 下载并解压RE预训练模型
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar && tar -xf re_vi_layoutxlm_xfund_pretrained.tar
3. 基于动态图预测(CPU)
- 更改一下
configs/kie/vi_layoutxlm中ser_vi_layoutxlm_xfund_zh.yml和re_vi_layoutxlm_xfund_zh.yml文件中,use_gpu参数改成False。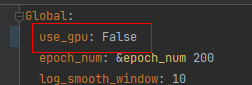
- 由于使用
XFUND数据集的预训练模型,因此需要用到一个类别列表文件;如果不想下载原始数据,可以在PaddleOCR根目录下新建train_data/XFUND/class_list_xfun.txt文件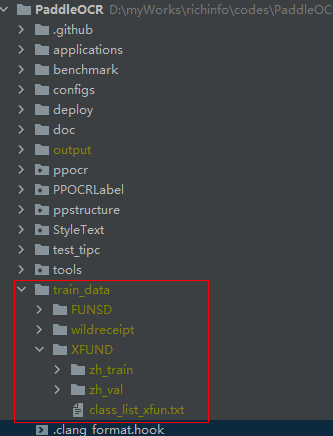
class_list_xfun.txt文件内容如下,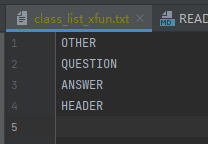
3.1 仅预测SER模型
cd PaddleOCR
python tools/infer_kie_token_ser.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=ppstructure/weights/ser_vi_layoutxlm_xfund_pretrained/best_accuracy Global.infer_img=ppstructure/docs/kie/input/zh_val_0.jpg

3.2 SER + RE模型串联
cd PaddleOCR
python tools/infer_kie_token_ser_re.py -c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=ppstructure/weights/re_vi_layoutxlm_xfund_pretrained/best_accuracy Global.infer_img=ppstructure/docs/kie/input/zh_val_42.jpg -c_ser configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o_ser Architecture.Backbone.checkpoints=ppstructure/weights/ser_vi_layoutxlm_xfund_pretrained/best_accuracy
- 踩坑 1:ValueError: (InvalidArgument) Currently, Tensor.indices() only allows indexing by Integers, Slices, Ellipsis, None, tuples of these types and list of Bool and Integers, but received bool in 1th slice item (at ..\paddle/fluid/pybind/slice_utils.h:298)

解决:pip install paddlenlp==2.5.2
4. 基于PaddleInference的预测(CPU)
4.1 SER和RE的推理模型下载
cd PaddleOCR/ppstructure
mkdir weights
cd weights
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar && tar -xf ser_vi_layoutxlm_xfund_infer.tar
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_infer.tar && tar -xf re_vi_layoutxlm_xfund_infer.tar
4.2 SER推理
cd ppstructure
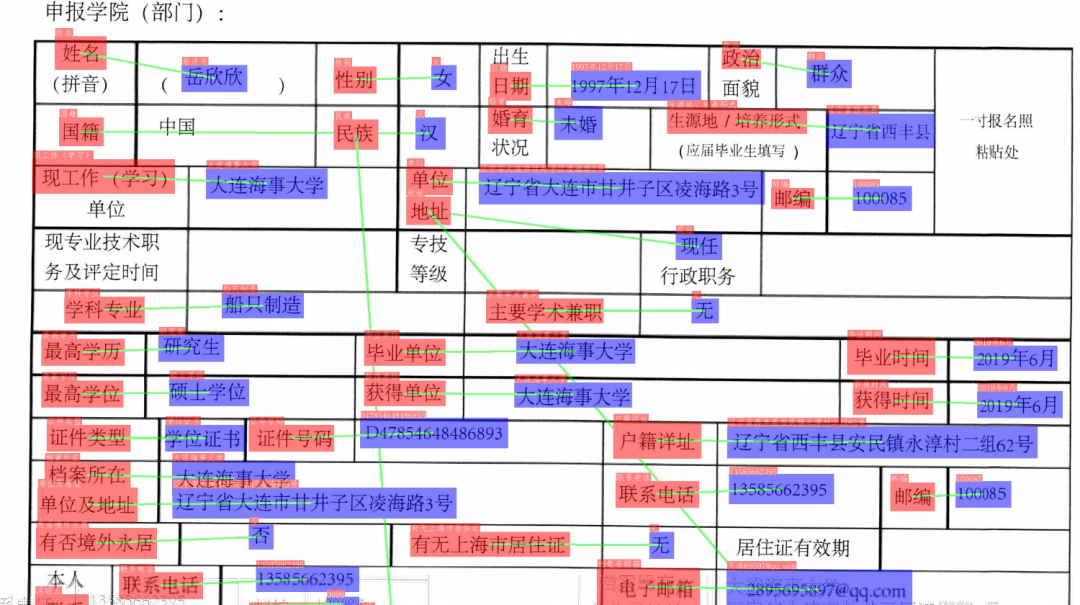
python kie/predict_kie_token_ser.py --kie_algorithm=LayoutXLM --ser_model_dir=./weights/ser_vi_layoutxlm_xfund_infer --image_dir=./test_data/Property_Ownership_Certificate_1a89c71b554eaea39b547254a6b092cd_0.jpg --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx"
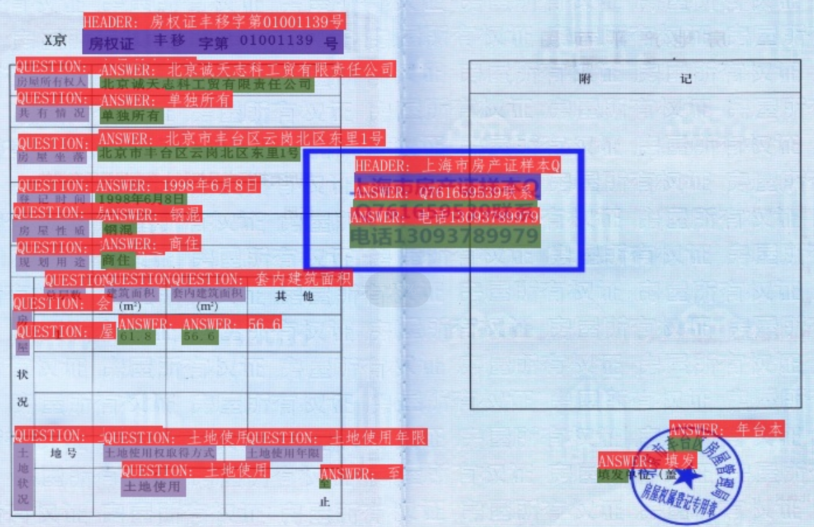
4.3 SER+RE串联推理
cd ppstructure
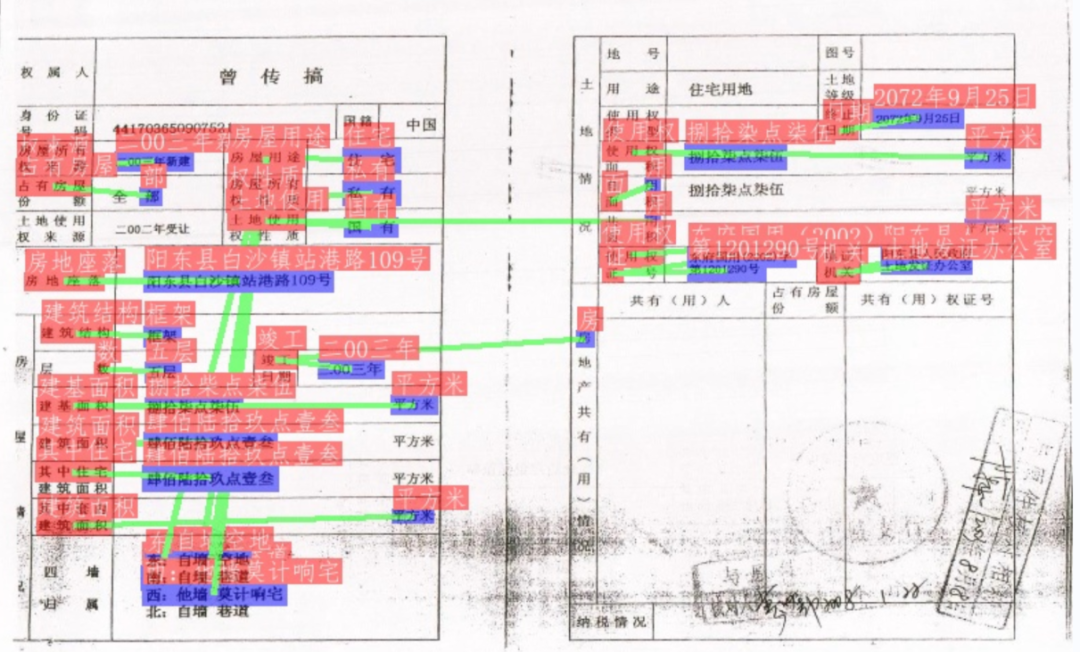
python kie/predict_kie_token_ser_re.py --kie_algorithm=LayoutXLM --re_model_dir=./weights/re_vi_layoutxlm_xfund_infer --ser_model_dir=./weights/ser_vi_layoutxlm_xfund_infer --use_visual_backbone=False --image_dir=./test_data/Property_Ownership_Certificate_bcefeb2c0e442e165554c7b381b1e024_0.jpg --ser_dict_path=../train_data/XFUND/class_list_xfun.txt --vis_font_path=../doc/fonts/simfang.ttf --ocr_order_method="tb-yx"
5. 模型查看
在PaddleOCR根目录下,
from typing import Dict
from tools.program import load_config
# 导入关系抽取(RE)默认配置re_configs
re_configs:Dict = load_config("configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml")
# 导入语义实体识别(SER)默认配置ser_configs
ser_configs:Dict = load_config("configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml")
# 修改配置,包括当前预训练模型路径
re_configs['Architecture']['Backbone']['checkpoints'] = 'ppstructure/weights/re_vi_layoutxlm_xfund_pretrained/best_accuracy'
ser_configs['Architecture']['Backbone']['checkpoints'] = 'ppstructure/weights/ser_vi_layoutxlm_xfund_pretrained/best_accuracy'
# 构建模型
import copy
import importlib
from ppocr.modeling.architectures import BaseModel
def build_model(config):
# 创建了config的一个深拷贝。深拷贝意味着原始的config字典及其嵌套的字典都会被复制,
# 这样在函数中对config的修改不会影响到外部的原始config对象
config = copy.deepcopy(config)
if not "name" in config:
arch = BaseModel(config)
else:
name = config.pop("name")
# 动态地导入当前模块(即包含build_model函数的模块)
mod = importlib.import_module(__name__)
arch = getattr(mod, name)(config)
return arch
re_model = build_model(re_configs['Architecture'])
# print(re_model) # 查看re模型结构
# re_model的骨架网络为LayoutXLMForRe类 -> ppocr/modeling/backbones/vqa_layoutlm.py::line 208
ser_model = build_model(ser_configs['Architecture'])
# print(ser_model) # 查看ser模型结构
# ser_model的骨架网络为LayoutXLMForSer类 -> ppocr/modeling/backbones/vqa_layoutlm.py::line 142
5.1 RE模型结构解读
RE是一个基于LayoutXLM的模型,包括4个模块:
- 嵌入层(LayoutXLMEmbeddings),包括几种嵌入:
-
单词嵌入: 将词汇映射到768维的向量空间。 -
位置嵌入: 为了保留单词的位置信息,使用位置嵌入,也是768维的。 -
视觉位置嵌入(x/y/h/w_position_embeddings): 分别为文档中的视觉元素(如图像块或文本块)的x坐标、y坐标、高度和宽度提供128维的嵌入表示。 -
类型嵌入(token_type_embeddings): 用于区分不同类型的标记(例如区分单词和视觉特征)。
- 自注意力机制 (LayoutXLMAttention): 用于捕捉序列内不同元素之间的依赖关系,允许模型在处理一个元素时考虑序列中的其他元素,这对理解文本和视觉上下文非常重要。
- 前馈网络 (LayoutXLMIntermediate和LayoutXLMOutput): 对自注意力的输出进行进一步的处理和转换,包含线性变换和激活函数的网络。
模块之间的关系如下:
嵌入层首先将输入文本和视觉信息转换为嵌入向量。编码器接收嵌入向量,并通过一系列的层来提取高级特征。池化层从编码器的输出中提取特征,以得到适合分类任务的表示。分类器使用池化层的输出来预测最终的类别。
5.2 SER模型结构解读
- BaseModel: 这是模型的最外层,它包含了整个模型的架构。
- backbone (LayoutXLMForSer): 这是模型的主干网络,负责特征提取的重要部分。
- model (LayoutXLMForTokenClassification): 这个子模块是针对标记分类任务定制的,它使用主干网络输出的特征来执行分类。
- layoutxlm (LayoutXLMModel): 这是实现LayoutXLM模型架构的核心模块,它包含以下组件:
- (1) attention (LayoutXLMAttention): 使用自注意力机制来捕获输入序列内不同元素之间的关系。
- (2) intermediate 和 output: 一个两阶段的前馈神经网络,包括密集连接和规范化。
- (1) word_embeddings: 将文本输入的单词转换为固定大小的向量。
- (2) position_embeddings: 提供单词在序列中的位置信息。
- (3) x/y/h/w_position_embeddings: 提供文档图像中对象的位置(x坐标和y坐标)和尺寸(高度h和宽度w)信息。
- (4) token_type_embeddings: 提供不同类型标记的嵌入。
- (5) LayerNorm 和 dropout: 用于嵌入向量的规范化和正则化。
- 4.1 embeddings (LayoutXLMEmbeddings): 该模块负责将输入的文本和视觉特征转换为嵌入向量,其中又包括以下细分的模型层:
- 4.2 encoder (LayoutXLMEncoder): 包括多个LayoutXLMLayer层,每个层都包含以下组件:
- 4.3 pooler (LayoutXLMPooler): 对编码器的输出进行池化,通常用于提取分类任务所需的特征。
模块之间的关系可以描述为以下流程:
- 输入数据首先通过embeddings模块,转换成嵌入向量。
- 嵌入向量被传递到encoder模块,进行深层特征提取。
- encoder的输出被pooler处理,以提取适合分类的特征。
- dropout层应用于这些特征,以提供正则化。
- classifier层使用这些特征来预测每个标记的分类。
备注
- LayoutXLMForRelationExtraction类 -> paddlenlp/transformers/layoutxlm/modeling.py::line 1265
- LayoutXLMModel类 -> paddlenlp/transformers/layoutxlm/modeling.py::line 598
评论