
如何挖掘评论中的关键信息
这篇论文解决了啥问题?

从上图中,我们可以看到,用户在点评里搜牛排,推荐的餐厅下面,有评论的精华。我们还发现,浓缩的评论,不仅简明扼要的突出了餐厅的优势,也和query强相关。要能做成这种效果,当然要想起无处不在的它:Attention!论文提到,每个餐厅评论的提炼,会帮助到用户做决策,而且和用户搜索内容也较为相关,而目前已有算法提炼评论的时候忽视了用户的query。
这篇论文本质上是从评论中提炼出和query相关的小贴士,属于文本生成。该文使用了transformer和RNN作为encoder和decoder,从评论中提取和query相关的内容。
小贴士生成模型
问题定义:有个用户评论序列 R = (r1, r2, ..., rN),N个词,还有个小贴士序列,长度为M,T=(t1, t2, ..., tM),最后还有用户的query序列 Q = (q1, q2, ..., qK),用Q和R生成T。
又到了回顾Transformer的时候(是不是有点看腻了):
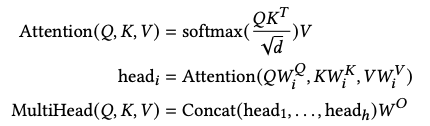
虽然transformer的公式一直长这样,可是用起来可是百花齐放。该文用这个transformer做了3个组件。
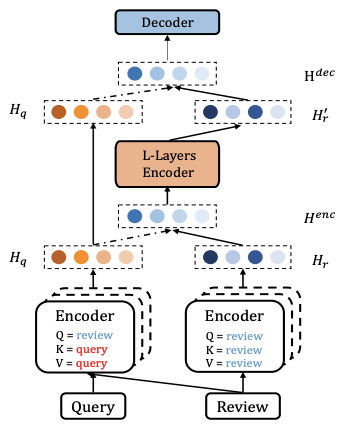
考虑评论的Query编码器:用户的query就是他需要的信息的精炼表达,而评论包含了很多细节信息表达了用户的兴趣。因此可以用transformer的self-atteion结构,挖掘query和评论之间的关系。我们知道正常transformer的Q,K,V都是同一份序列向量,只不过在进attention前做了线性变换,这篇论文做了个很小的改动。假若query的embeding是Emb(Q),评论的embedding是Emb(R),H = MultiHead(Emb(R), Emb(Q), Emb(Q)),用评论和query的attention对query进行聚合,最终输出Hq (N * d)。
考虑Query的评论编码器:这里用另一个transformer,Q,K,V都是Emb(R),会输出Hr(N*d)。这里我们知道Hq参考了评论编码了用户的query,Hr则直接编码了用户的评论,我们通过concat这两个embeding,过一个mlp,就可以把Hr和Hq编码成Henc。Hemc = [Hq;Hr]W。Henc同样会输入到第三个transformer去编码,挖掘更多信息,最后生成Hr'。
考虑Query的小贴士解码器:用Hq和Hr' concat后做线性变换成最终的embeding,Hdec = [Hq,Hr']W,作为decoder的输入。
整个基于transformer的模型框架图如下:
说完了transformer,再来说基于RNN的另一种方法先看框架图:
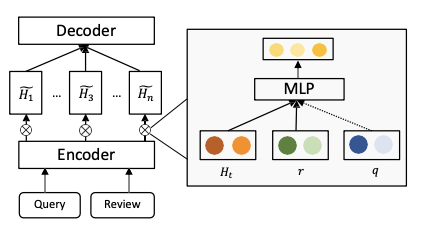
Query编码器:用双向LSTM,最终取最后一个向量,作为query的表达,hq( 2d),不赘述。
考虑Query的评论编码器:同样是Bi-LSTM,最终生成hr(N * 2d),然后用一个selective gate,通过hq去提取hr中有效的信息。
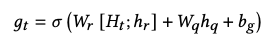
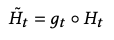
考虑Query的小贴士decoder:同样是用LSTM,生成了st序列。为了使得生成的小贴士和query相关,所以引入query的编码hq,在t步的时候,用下式通过attention方式生成最终emb:
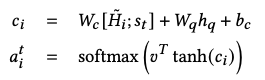
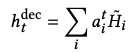
最后训练的时候,学习的是log loss:
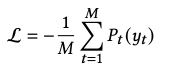
实验
先看下文本生成的效果:

tip确实和餐厅,评论,query都很相关。
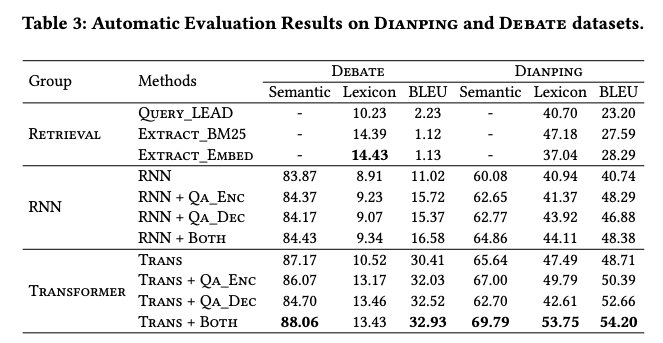
比较各个模型,transformer的的效果都要好。