
RankDataset:超大规模数据集加载利器

极市导读
文章介绍了RankDataset的代码训练过程,RankDataset从原理入手,在分布式的基础上,直接计算每个epoch当前rank需要训练的数据的index。优点是大量的节省内存,且不需要额外开server。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
问题阐述
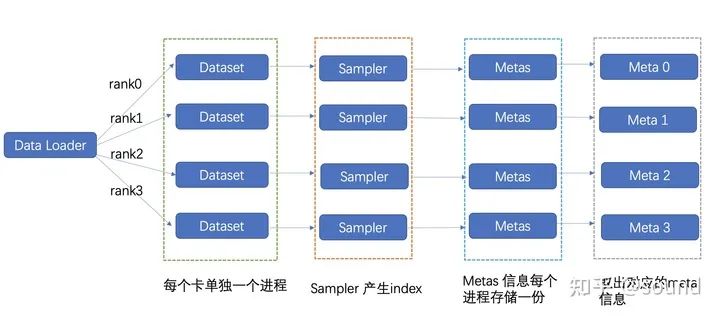
小王是一名炼丹术士,某一天小王逛着arxiv的时候,突然眼前一亮,发现一篇很好的论文:CLIP,看着论文开源的github,小王撸起袖子,准备自己爬一批数据尝试训一下clip。经过N久之后,终于凑齐了4亿数据。虽然没经过清洗,不过小王践行实践原则,准备先暴力开搞一下。小王使用了PyTorch框架,写完了build模型,把之前的Dataset拿过来抄了一下,写了个RandomSampler,用了官方的Dataloader,一切就绪之后,一份伪Code就写好了:(如果你不熟悉 Dataset和Sampler的具体含义,可以参考这里Dataset:https://zhuanlan.zhihu.com/p/337850513) 下图是一个简化后的加载示意图
meta_file 格式
#filename labelimage1.jpg "balabala"image2.jpg "balabala"image3.jpg "balabala"
NaiveDataset
from torch.utils.data import Datasetfrom torch.utils.data import DataLoaderfrom torch.utils.data.sampler import Samplerclass NaiveDataset(Dataset):def __init__(self, meta_file):super(NaiveDataset, self).__init__()self.metas = self.parse(meta_file)def parse(self, meta_file):metas = []with open(meta_file) as f:for line in f.readlines():metas.append(line.strip())return metasdef __getitem__(self, idx):return self.metas[idx]def __len__(self):return len(self.metas)
RandomSampler
class RandomSampler(Sampler):r"""Samples elements randomly, without replacement.Arguments:data_source (Dataset): dataset to sample from"""def __init__(self, dataset):self.dataset = datasetdef __iter__(self):return iter(torch.randperm(len(self.dataset)).tolist())def __len__(self):return len(self.dataset)
训练数据的流程可以表示如下:
dataset = NaiveDataset("/path/to/meta")sampler = RandomSampler(datset)dataloader = DataLoader(dataset=dataset,batch_size=32,shuffle=False,num_workers=4,sampler=sampler)model = build_model()for index, batch in enumerate(dataloader):label = batchoutput = model(image)loss = criterion(output, label)loss.backward()
写完代码之后,小王美滋滋的准备开始训练了一下,先拿一个小训练集测试一下有没有bug,一番修改之后,看着逐渐收敛的网络,小王很开心,准备上大数据集了。既然要训大数据量,那必然要上分布式训练,好在PyTorch的分布式训练比较容易,小王从表哥家借来了一个8GPU的挖矿机。准备使用world_size为8的分布式训练。小王在原来的sampler基础上略加修改,就得到了一个新的sampler (分布式sampler,负责分发训练数据index给不同的卡)
DistributedRandomSampler
class DistributedRandomSampler(Sampler):r"""Samples elements randomly, without replacement.Arguments:data_source (Dataset): dataset to sample from"""def __init__(self, dataset, rank, world_size):self.dataset = datasetself.world_size = world_sizeself.rank = rankself.num_samples = int(math.ceil(len(self.dataset) * 1.0 / self.world_size))def __iter__(self):index_list = torch.randperm(len(self.dataset)).tolist()index_list = padding(len(self.dataset), self.rank, self.world_size) #padding函数保证index_list长度整除rankreturn iter(index_list[self.rank * self.num_samples: (self.rank + 1) * self.num_samples])def __len__(self):return self.num_samples
只需要替换一下之前的sampler就可以直接用,而且时间近似缩短到约原来的1/8. Money is all you need!小王直呼有钱真好。
sampler = DistributedRandomSampler(dataset)
分布式训练的code也写完了,小王把训练文件进行了替换,直接准备训练4亿数据。小王跑起了程序,然后相约王者峡谷。
连跪了三局后准备看一眼收敛的怎么样了,可是屏幕上OOM error让他关上了手机。
作为面向zhihu csdn stack overflow编程的行家,小王很快搜到了问题原因:
数据量太大了,内存放不下。
看着某乎上的答案,小王自信的吧worker改成了2,心想这下总算没问题了吧。
dataloader = DataLoader(dataset=dataset,batch_size=32,shuffle=False,num_workers=2,sampler=sampler)
可是结果依旧是OOM。接连验证了好几个网上的方法都不好使之后,小王束手无策了。
没办法,只能给表哥打电话,叙述了一下自己遇到的问题。表哥的解释让他明白了:
通常来说我们为了保证训练高效,在分布式训练时我们都会开启多进程,每块卡单独一个进程。每个进程里面会存储一些基本的模型和优化器信息,当然也会存储我们训练metas信息。
在原生的PyTorch 数据集加载过程中,我们的分布式sampler 负责给每块卡分发index,为了保证高效读取,每个进程都需要保存其所有的metas。那么对于8卡任务也就是会有8 * metas 需要在内存里存放(实际考虑到dataloader 的worker 数量,这个实际占用量会更大)。
当我们的metas信息比较大的时候,我们的内存就可能会出现溢出问题。
之前没有训练过这个大的数据,这次数据量上来了,内存吃不下很正常。
解决方案一
"那怎么解决呢?"小王问表哥。
你现在一台机器上要load 8份数据,当然内存要爆了。我在家的时候都是开两台机器,一台专门用来读数据(称为server),另一台专门用来训练(称为client)。
然后训练的时候client每次取数据都从server获得数据,这样数据只需要在server存一份就够了。
"Talk is cheap, show me the code?"
于是小王得到了表哥的祖传代码:
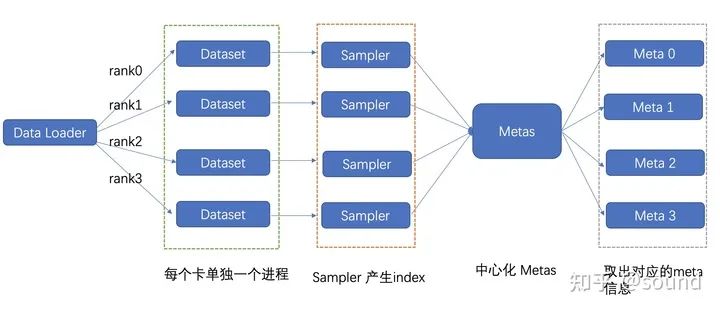
class ServerDataset(Dataset):def __init__(self, meta_file, server_ip, server_port):super(ServerDataset, self).__init__()self.server_ip = server_ipself.server_port = server_portself.meta_num = get_meta_num(server_ip, server_port)def get_meta(self, idx):meta = requests.get('http://{}:{}/get/{}'.format(self.server_ip, self.server_port, idx), timeout=1000).json()return metadef __getitem__(self, idx):return self.get_meta(idx)def __len__(self):return self.meta_num
看起来蛮简单的,只是把原来的从内存读变成了从server网络读取。可是这样的训练效率怎么样呢?
“这种做法对于qps在1k以下还比较实用, 但是当训练的总batchsize 特别大的时候这种做法会有明显的瓶颈问题,受限于中心化的并发读取上限问题,因此此方法具有一定的局限性。”
小王用修改了之后的code,跌跌撞撞的算是跑起来训练了。
跑起来之后小王自己想了想:起server太麻烦了,有没有更好的方式呢。小王仔细分析了一下数据加载的流程,发现了一些不得了的事情。
解决方案二
从原理出发,小王进行了一下计算,其实每张卡实际使用的数据量为 len(metas) // world_size, 在一般的训练过程中为了访问方便,采用sampler 去划分不同的卡读取的index,每块卡还是会保留所有的meta信息,因此这样会导致前面的内存问题。而实际上,我保存了1000的数据,实际只使用其中了125张,那位为什么要把所有的都存下来呢?为什么我不能只把我需要用到的数据读取进来呢?说干就干,小王设计了一下方案。
具体方案
小王决定分rank + 切分数据集进一步的动态的去加载数据集。
如下图所示,在初始化的时候,每块卡只加载其对应的meta信息,这样总体的内存占用率可减少 world_size 倍。为了进一步的减少内存,还可以进一步将数据集进行切分,分成 mini_epoch 进行分组读取。两者配合使用,总体的内存减少量可达 world_size * mini_epoch 倍,基本上可以达到需求。
实际的流程图
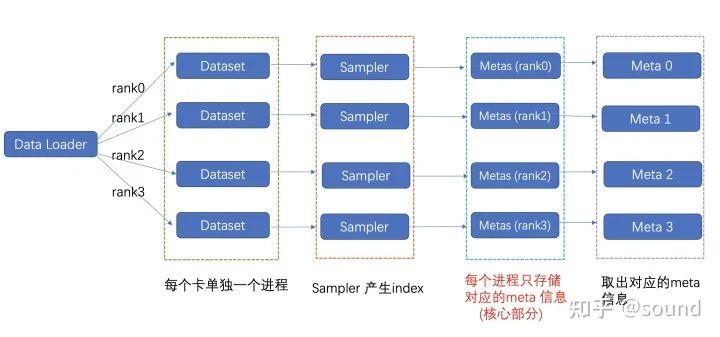
切分流程
'''Metas 切分过程, mini_epoch = 2, world_size = 8mini_epoch_idx = 0 mini_epoch_idx = 1---- ---- ---- ---- ---- ---- ---- ---- | ---- ---- ---- ---- ---- ---- ---- ----rk0 rk1 rk2 rk3 rk4 rk5 rk6 rk7 | rk0 rk1 rk2 rk3 rk4 rk5 rk6 rk7每次只加载 len(metas) // (world_size * mini_epoch) 这样我内存占用就会可以人为的进行调整'''
基本就是这样了,这样内存就是满足了,可是还有一点,之前的sampler是针对整个数据集来进行的,这里要怎么做呢?略作思索,小王得出来结论:
对于普通的dataloader,随机性一般由sampler进行控制,这里由于已经分rank进行加载meta信息,为了保证不同epoch 加载数据顺序保证随机性,每隔一个epoch需要重新分配一次每个 rank 的 meta 信息。小王在此基础上写出了新的code。
本地读取样例
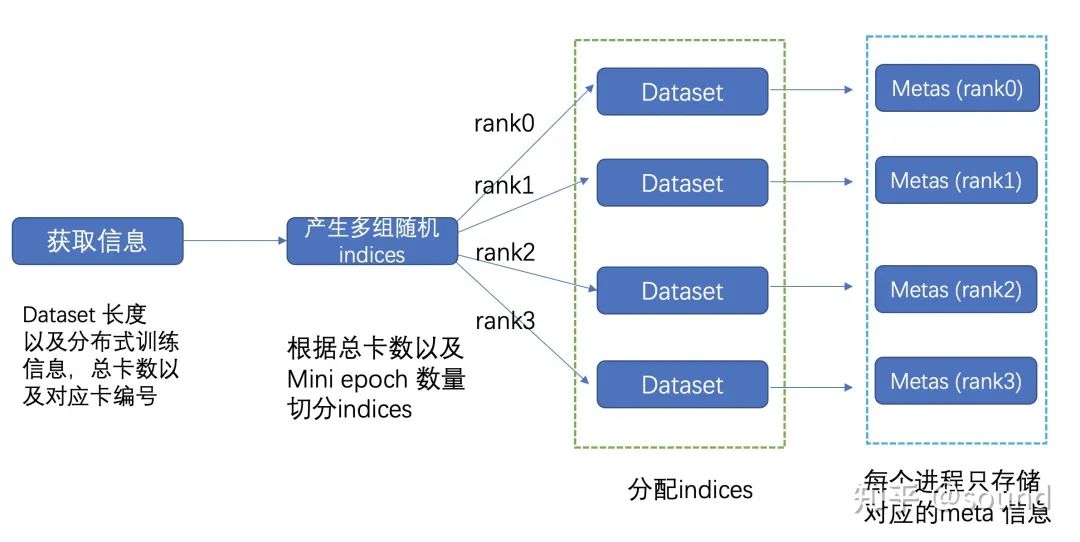
class RankDataset(Dataset):'''实际流程获取rank和world_size 信息 -> 获取dataset长度 -> 根据dataset长度产生随机indices ->给不同的rank 分配indices -> 根据这些indices产生metas'''def __init__(self, meta_file, world_size, rank, seed):super(RankDataset, self).__init__()random.seed(seed)np.random.seed(seed)self.world_size = world_sizeself.rank = rankself.metas = self.parse(meta_file)def parse(self, meta_file):dataset_size = self.get_dataset_size(meta_file) # 获取metafile的行数local_rank_index = self.get_local_index(dataset_size, self.rank, self.world_size) # 根据world size和rank,获取当前epoch,当前rank需要训练的index。self.metas = self.read_file(meta_file, local_rank_index)def __getitem__(self, idx):return self.metas[idx]def __len__(self):return len(self.metas)
因为这里的dataset读取进来的数据已经是分片之后的了,对应的sampler只需要使用一开始的RandomSampler就可以:
epoch_num = 0dataset = RankDataset("/path/to/meta", world_size, rank, seed=epoch_num)sampler = RandomSampler(datset)dataloader = DataLoader(dataset=dataset,batch_size=32,shuffle=False,num_workers=4,sampler=sampler)
再次运行一看,使用的内存确实已经降低了很多,很稳!。由于每个epoch都要重新读取数据,因此每个epoch要重新build dataloader:
for epoch_num in range(epoch_num):dataset = RankDataset("/path/to/meta", world_size, rank, seed=epoch_num)sampler = RandomSampler(datset)dataloader = DataLoader(dataset=dataset,batch_size=32,shuffle=False,num_workers=4,sampler=sampler)
这样看起来每个epoch都要读取数据很麻烦,但是和4亿数据的训练时间相比,读取的时间便不算什么了。不过这种方法是否合理呢,会不会影响精度?小王在不同任务上进行了实验,分类任务上用imagenet和imagenet22k数据集,检测任务上使用了Open-Image数据集,均发现没有精度的损失。
总结
忙碌了这么久,小王把今日所做的事情做了一个总结:
对于一般的数据集:
自己实现一个继承torch.data.Dataset类就可以,需要实现init,getitem,len三个函数; 使用torch默认的RandomSampler即可满足一般的random shuffle需求 使用torch默认的dataloader就制定完成数据迭代器
使用分布式训练:
Dataset保持不变 sampler进行修改,保证每个rank读到的index可以覆盖到整个dataset,并且每个rank读的数据要是等量的 dataloader保持不变
使用中心化server:
为了解决大数据量加载内存不够的问题,可以专门使用一个节点当做server,为训练集供给训练。好处是可以节省内存,坏处是麻烦,以及对网络带宽和qps有需求。
Dataset进行修改, getitem从内存读取数据改成向server发出请求,获得对应index的数据。 可以直接使用分布式的sampler dataloader保持不变
RankDataset:
从原理入手,在分布式的基础上,直接计算每个epoch当前rank需要训练的数据的index。好处是大量的节省内存,且不需要额外开server。坏处是每个epoch都需要重新build dataloader,但是当数据量大的时候这个时间是可以接受的。
支持进一步切分数据集,分批去读取数据集。 Dataset进行修改:每个epoch先计算该rank需要使用的index,然后根据index获取meta_file对应行,加载到内存中。 改为torch默认的使用torch默认的RandomSampler即可满足一般的random。 dataloader保持不变,但是在训练过程中,每个epoch到要用不同的随机数重新build dataloader。
美好的一天结束了,实验终于训起来了,小王再次美汁汁的钻进了王者峡谷。
最后我们来对比一下实际的内存优化效果。
| 方案 | PyTorch 官方处理 | 中心化Metas | RankDataset |
|---|---|---|---|
| 内存占用 | M | 0 | M / world_size / mini_epoch |
| 并发 | 内存读取 | 网络读取(qps < 1k) | 内存读取 |
后记
RankDataset已经在公司内部的分类和检测框架(POD)进行精度和速度验证,同时已经集成到Spring2 内部,方便公司内部用户的使用,欢迎各位使用。
推荐阅读
2020-11-18

2020-12-24

2020-09-20


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
