
Python实时增量数据加载解决方案

单例模式详解篇:见以往推文单例模式。
 创建增量ID记录表
创建增量ID记录表
import sqlite3
import datetime
import pymssql
import pandas as pd
import time
pd.set_option('expand_frame_repr', False)←导入所需模块→
# 创建数据表
database_path = r'.\Database\ID_Record.db'
from sqlite3 import connect
with connect(database_path) as conn:
conn.execute(
'CREATE TABLE IF NOT EXISTS Incremental_data_max_id_record(id INTEGER PRIMARY KEY AUTOINCREMENT,F_SDaqID_MAX TEXT,record_date datetime)')
数据库连接类
2、增量数据源sqlserver连接类代码
class Database_sqlserver(metaclass=MetaSingleton):
"""
#实时数据库
"""
connection = None
# def connect(self):
def __init__(self):
if self.connection is None:
self.connection = pymssql.connect(host="xxxxx",user="xxxxx",password="xxxxx",database="xxxxx",charset="utf8")
if self.connection:
print("连接成功!")
# 打开数据库连接
self.cursorobj = self.connection.cursor()
# return self.cursorobj, self.connection
# 获取数据源中最大ID
@staticmethod
def get_F_SDaqID_MAX():
# cursor_insert = Database_sqlserver().connect()
cursor_insert = Database_sqlserver().cursorobj
sql_MAXID = """select MAX(F_SDaqID) from T_DaqDataForEnergy"""
cursor_insert.execute(sql_MAXID) # 执行查询语句,选择表中所有数据
F_SDaqID_MAX = cursor_insert.fetchone()[0] # 获取记录
print("最大ID值:{0}".format(F_SDaqID_MAX))
return F_SDaqID_MAX
# 提取增量数据
@staticmethod
def get_incremental_data(incremental_Max_ID):
# 开始获取增量数据
sql_incremental_data = """select F_ID,F_Datetime,F_Data from T_DaqDataForEnergy where F_ID > {0}""".format(
incremental_Max_ID)
# cursor_find = Database_sqlserver().connect()
cursor_find = Database_sqlserver().cursorobj
cursor_find.execute(sql_incremental_data) # 执行查询语句,选择表中所有数据
Target_data_source = cursor_find.fetchall() # 获取所有数据记录
# cursor_find.close()
cursor_find.close()
df = pd.DataFrame(
Target_data_source,
columns=[
"F_ID",
"F_Datetime",
"F_Data"])
print("提取数据", df)
return df
数据资源应用服务设计主要考虑数据库操作的一致性和优化数据库的各种操作,提高内存或CPU利用率。
实现多种读取和写入操作,客户端操作调用API,执行相应的DB操作。
注:
1、使用metaclass实现创建具有单例特征的类
Database_sqlserver(metaclass=MetaSingleton)
Database_sqlite(metaclass=MetaSingleton)
使用class定义新类时,数据库类Database_sqlserver由MetaSingleton装饰后即指定了metaclass,那么MetaSingleton的特殊方法__call__方法将自动执行。
class MetaSingleton(type):
_instances={}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(MetaSingleton,cls).__call__(*args,**kwargs)
return cls._instances[cls]
以上代码基于元类的单例实现,当客户端对数据库执行某些操作时,会多次实例化数据库类,但是只创建一个对象,所以对数据库的调用是同步的。
2、多线程使用同一数据库连接资源需采取一定同步机制
如果没采用同步机制,可能出现一些意料之外的情况
1)with cls.lock加锁
class MetaSingleton(type):
_instances={}
lock = threading.Lock()
def __call__(cls, *args, **kwargs):
with cls.lock:
if cls not in cls._instances:
time.sleep(0.05) #模拟耗时
cls._instances[cls] = super(MetaSingleton,cls).__call__(*args,**kwargs)
return cls._instances[cls]
锁的创建和释放需要消耗资源,上面代码每次创建都必须获得锁。
3、如果我们开发的程序非单个应用,而是集群化的,即多个客户端共享单个数据库,导致数据库操作无法同步,而数据库连接池是更好的选择。大大节省了内存,提高了服务器地服务效率,能够支持更多的客户服务。
数据库连接池的解决方案是在应用程序启动时建立足够的数据库连接,并讲这些连接组成一个连接池,由应用程序动态地对池中的连接进行申请、使用和释放。对于多于连接池中连接数的并发请求,应该在请求队列中排队等待。
增量数据服务客户端
class IncrementalRecordServer:
_servers = []
_instance = None
def __new__(cls, *args, **kwargs):
if not IncrementalRecordServer._instance:
# IncrementalRecordServer._instance = super().__new__(cls)
IncrementalRecordServer._instance = super(IncrementalRecordServer,cls).__new__(cls)
return IncrementalRecordServer._instance
def __init__(self,changeServersID=None):
"""
变量初始化过程
"""
self.F_SDaqID_MAX = Database_sqlserver().get_F_SDaqID_MAX()
self.record_date = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
self.changeServersID = changeServersID
# 回调更新本地记录,清空记录替换,临时记录
def record(func):
def Server_record(self):
v = func(self)
text_save(filename=r"F:\AutoOps_platform\Database\Server_record.txt",record=IncrementalRecordServer._servers)
print("保存成功")
return v
return Server_record
#增加服务记录
@record
def addServer(self):
self._servers.append([int(self.F_SDaqID_MAX),self.record_date])
print("添加记录")
Database_sqlite.Insert_Max_ID_Record(f1=self.F_SDaqID_MAX, f2=self.record_date)
#修改服务记录
@record
def changeServers(self):
# self._servers.pop()
# 此处传入手动修改的记录ID
self._servers.append([self.changeServersID,self.record_date])
#先删除再插入实现修改
Database_sqlite.Del_Max_ID_Records()
Database_sqlite.Insert_Max_ID_Record(f1=self.changeServersID, f2=self.record_date)
print("更新记录")
#删除服务记录
@record
def popServers(self):
# self._servers.pop()
print("删除记录")
Database_sqlite.Del_Max_ID_Records()
# 最新服务记录
def getServers(self):
# print(self._servers[-1])
Max_ID_Records = Database_sqlite.View_Max_ID_Records()
print("查看记录",Max_ID_Records)
return Max_ID_Records
#提取数据
def Incremental_data_client(self):
"""
# 提取数据(增量数据MAXID获取,并提取增量数据)
"""
# 实时数据库
# 第一次加载先判断是否存在最新记录
if self.getServers() == None:
# 插入增量数据库ID
self.addServer()
# 提取增量数据
data = Database_sqlserver.get_incremental_data(self.F_SDaqID_MAX)
return data
# 获取增量数据库中已有的最新最大ID记录
incremental_Max_ID = self.getServers()
#添加记录
self.addServer()
# 提取增量数据
Target_data_source = Database_sqlserver.get_incremental_data(incremental_Max_ID)
return Target_data_source
class IncrementalRecordServer:
_servers = []
_instance = None
def __init__(self,changeServersID=None):
"""
变量初始化过程
"""
self.F_SDaqID_MAX = Database_sqlserver().get_F_SDaqID_MAX()
self.record_date = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
self.changeServersID = changeServersID
if not IncrementalRecordServer._instance:
print("__init__对象创建")
else:
print("对象已经存在:",IncrementalRecordServer._instance)
self.getInstance()
@classmethod
def getInstance(cls):
if not cls._instance:
cls._instance = IncrementalRecordServer()
return cls._instancedef __del__(self):
class_name = self.__class__.__name__
print(class_name,"销毁")if __name__ == '__main__':
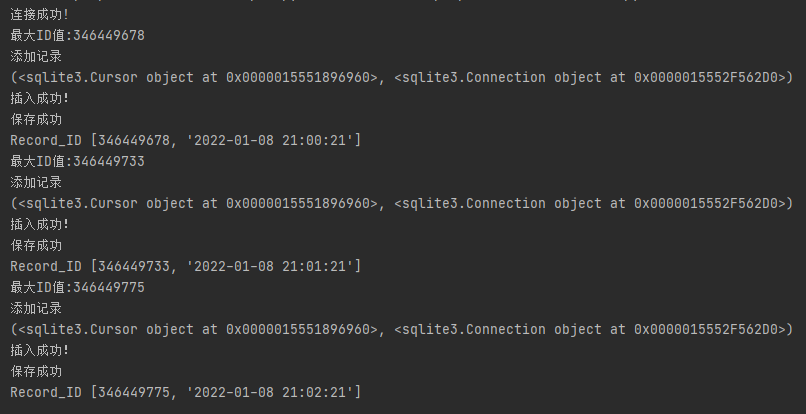
for i in range(6):
hc1 = IncrementalRecordServer()
hc1.addServer()
print("Record_ID",hc1._servers[i])
# del hc1
time.sleep(60)
#Server2-客户端client
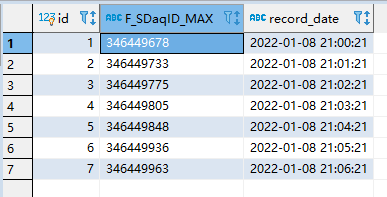
# 最新服务记录
hc2 = IncrementalRecordServer()
hc2.getServers()
#查看增量数据
hc2.Incremental_data_client()
if __name__ == '__main__':
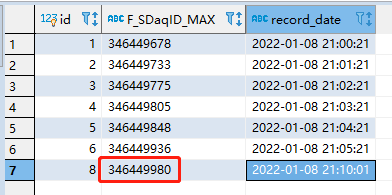
# Server3-客户端client
# 手动添加增量起始ID记录
hc3 = IncrementalRecordServer(changeServersID='346449980')
hc3.changeServers()

if __name__ == '__main__':
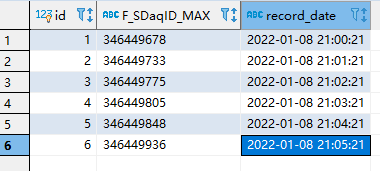
#删除ID
hc3 = IncrementalRecordServer(changeServersID='346449980')
# hc3.changeServers()
hc3.popServers()


评论