
GAN如何异常检测?最新《生成式对抗网络异常检测》综述论文,概述异常检测的典型GAN模型
新智元报道
新智元报道
作者:专知
【新智元导读】异常检测是许多研究领域所面临的重要问题。生成对抗网络(GANs)和对抗训练过程最近被用来面对这一任务,产生了显著的结果。本文综述了主要的基于GAN的异常检测方法,并突出了它们的优缺点。

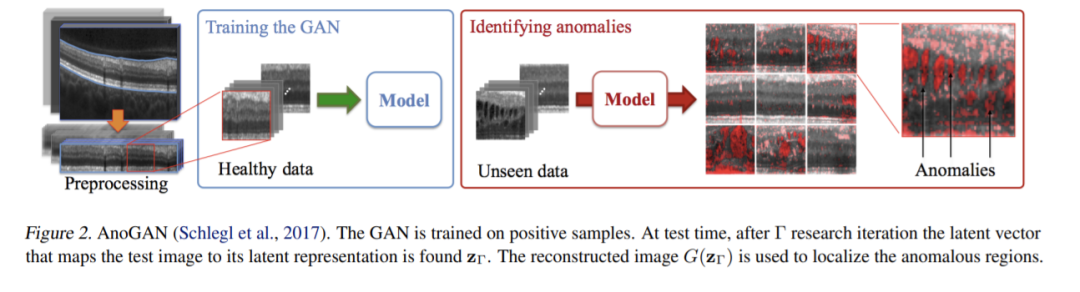
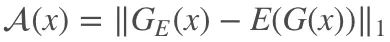 ,通过设定阈值 ϕ,一旦 A(x)>ϕ 模型就认定送入的样本 x 是异常数据。
,通过设定阈值 ϕ,一旦 A(x)>ϕ 模型就认定送入的样本 x 是异常数据。 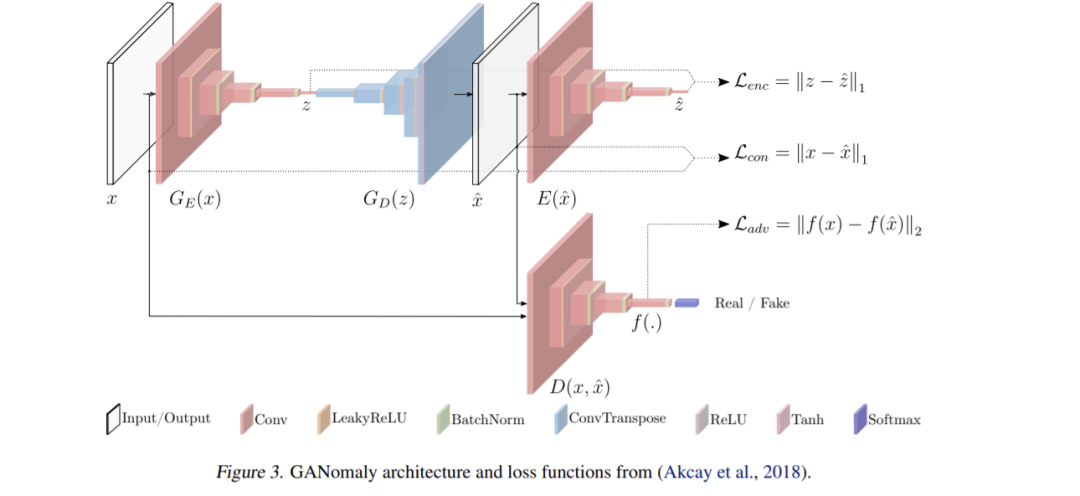

参考资料:
https://mp.weixin.qq.com/s/yOoDkTyZMmaFygt5MiGWtw
https://arxiv.org/abs/1906.11632

评论