
代码家:简明数据库史
在工业时代,煤炭和钢铁的使用量是一个国家发达程度的指标。而到了信息时代,数据量将是新的发达程度指标,几乎所有行业竞争本质上都是数据的竞争。支撑数据增长的背后,是一代又一代不断演化的数据库引擎,在真格基金的投资工作中,不断的开始有中国团队尝试挑战数据库领域海外的垄断地位,打造新一代的数据库引擎。业余时间,对整个数据库发展史做了个简单的总结。
整个数据库大致经历了四个发展阶段。
第一阶段:非关系型数据库
在现代意义的数据库出来之前(20 世纪 60 年代),文件系统(File system)可以说是最早的数据库,程序员们读取文本文件,并通过代码提取文件中的关键数据,在脑海中尝试构造数据与数据之间的关系。当年能流行起来的编程语言,往往都有很强的文件和数据处理能力(比如 Perl 语言)。随着数据量的增长,数据维度的多元化,以及对于数据可信和数据安全的要求不断提升,简单的将数据存储在 txt 文本中,成为极其具有挑战的事情。
随后,人们开始提出数据库管理系统(Database Management System, DBMS)的概念。数据库的演进抽象来看是人们对 数据结构 和 数据关系 这两个维度展开的思考和优化。
层次模型和网络模型(1960)
第一阶段的数据库模型(Database model) 是层次模型(Hierarchical Databases)。
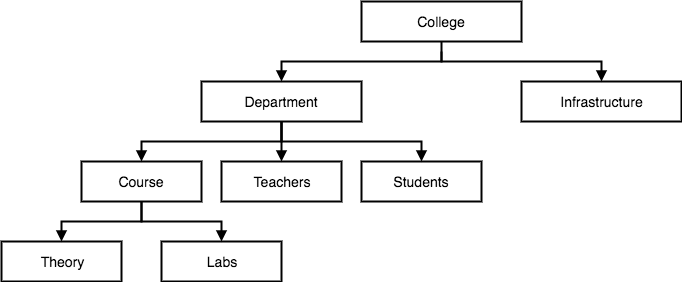
图 1:一个表达学校结构的层次模型数据库
层次模型是最早的数据库模型。随着早期 IBM 大型机逐渐推广开来。这个模型相对于文本文件管理数据,是个巨大的提升,但也有很多问题。
问题:
尽管能比较好的表达 一对一 ( one to one) 结构,但在 多对多(many to many) 结构上难以表达 如:图中能较好的表达一个系有多个老师,但很难表达一个老师可能属于多个系。 层次结构不够灵活 如:添加一个新的数据库关系有可能对整个数据库结构带来巨大变化,以至于在真正的开发中带来巨大的工作量 查询数据需要脑海中随时有最新的结构图,且需要遍历树状结构做推导
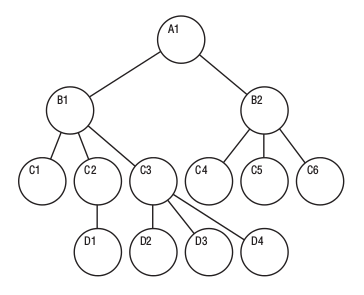
问题:
难以从代码层面实现和维护 查询数据需要脑海中随时有最新的结构图
第二阶段:关系型数据库
模型初期(1970)
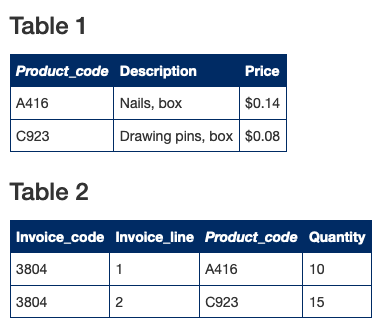
Table2 中的 Product_code 列指向了 Table1 中对应的数据,从而建立 Table2 和 Table1 的关系
数据仓库(1980s)
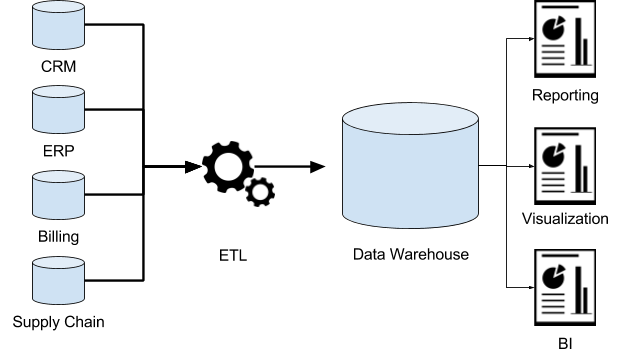
解释:ETL 是 Extract(提取),Transform(转换),Load(加载)的缩写。因为数据在不同的数据库或者系统中,可能存在格式不统一,单位不统一等等情况。需要做一次数据的预处理。
OLAP(联机分析处理)
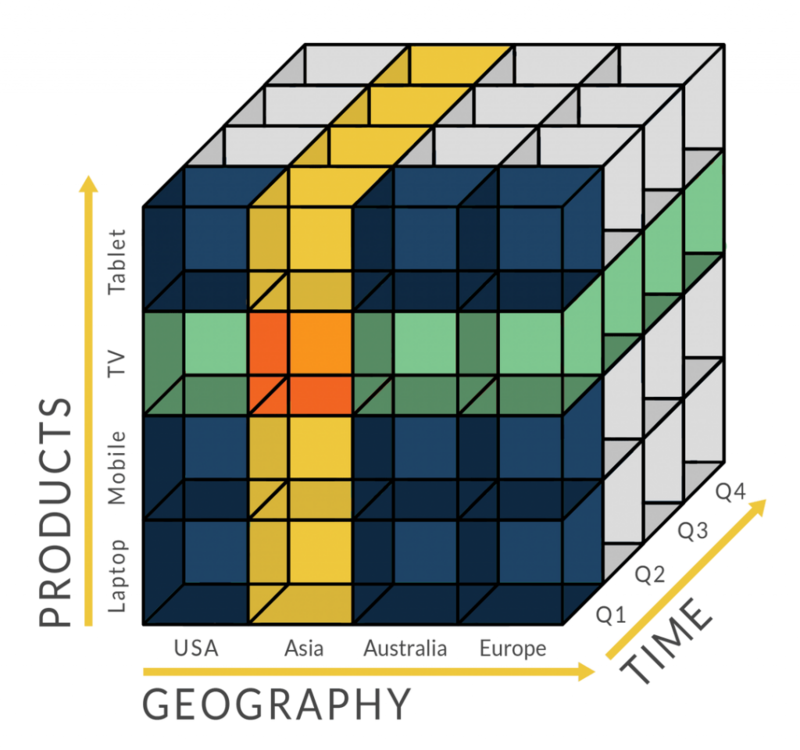
将多个维度的数据组织和展示
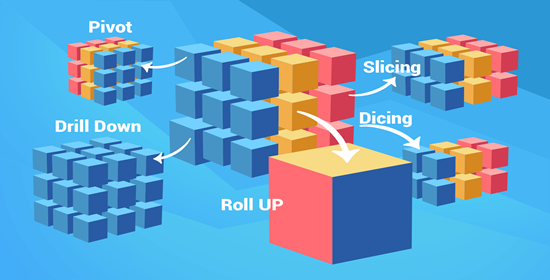
第三阶段:NoSQL
挑战一:数据列的扩展成本巨高
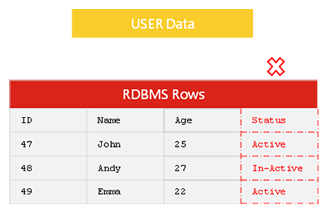
挑战二:数据库性能的挑战
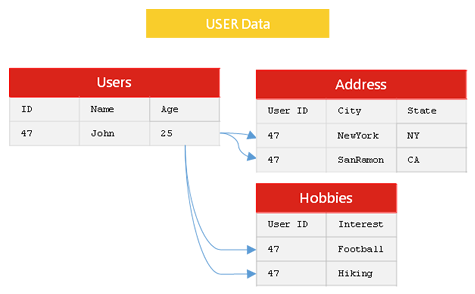

文档型数据库(Document-Oriented):如大名鼎鼎的 MongoDB、CouchDB。文档泛指一种数据的存储结构,如 XML、JSON、JSONB 等。 键值数据库(Key-Value Database) :大家所听说的 Redis、Memcached、Riak 都是键值对数据库 列式存储数据库(Column-Family):如 Cassandra、HBase 图数据库(Graph-oriented):如 Neo4j、OrientDB 等。聚焦在数据间关系链的数据组织方式。
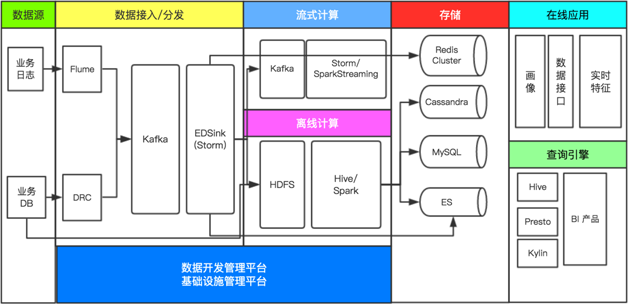
第四阶段:
云原生数据库和托管/自建数据库最大的区别就是:云原生数据库是面向独立资源的云化,其CPU、内存、存储等均可实现独立的弹性,利用大型云厂商的海量资源池,最大化其资源利用率,降低成本,同时支持独立扩展特定资源,满足多种用户不断变化的业务需求,实现完全的Serverless; 而托管数据库还是局限于传统的服务器架构,各项资源等比率的限制在一个范围内,其弹性范围,资源利用率都受到较大的限制,无法充分利用云的红利。 http://mysql.taobao.org/monthly/2020/05/01/
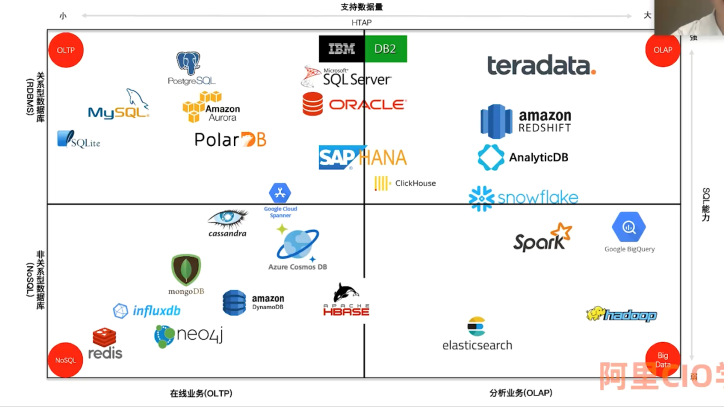
CAP 理论
Consistency(数据一致性) Availability(数据可用性) Partition tolerance(分区容错)
如果你想与代码家交流,可以加他的微信:daimajia(著名来源和身份),如果你在创业,或者有想法创业,也欢迎投递 BP 或者和代码家邮件交流:huiwen@zhenfund.com

评论