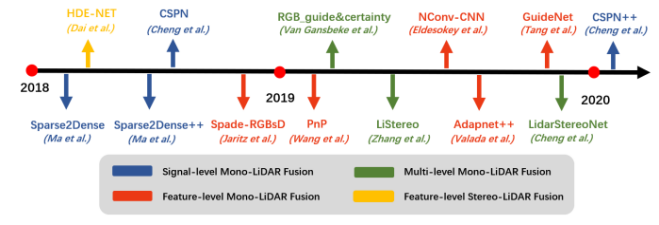
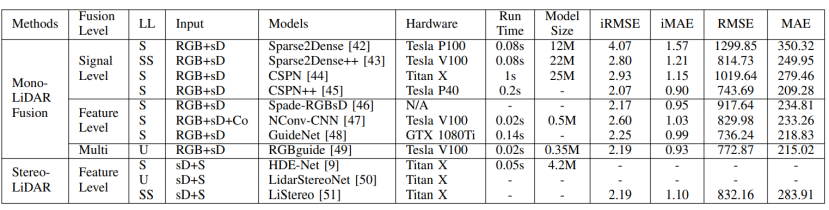
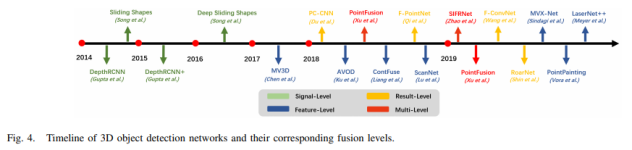
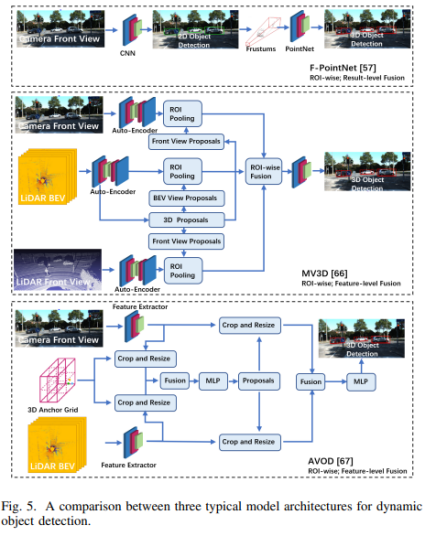
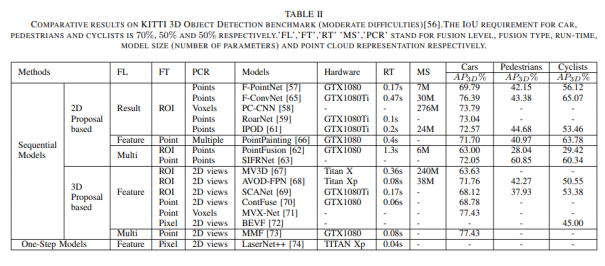
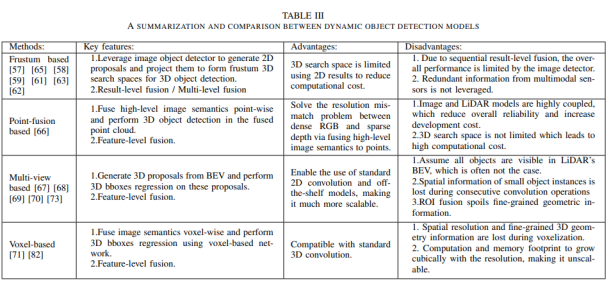
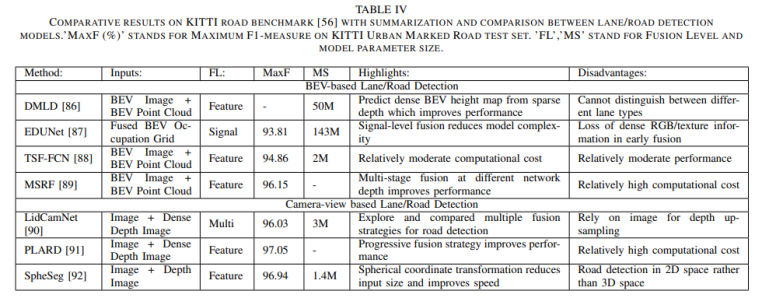
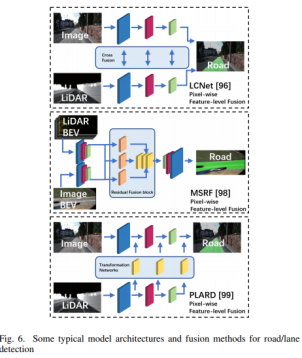
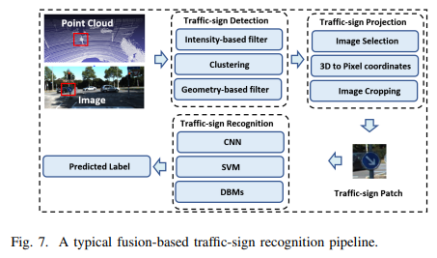
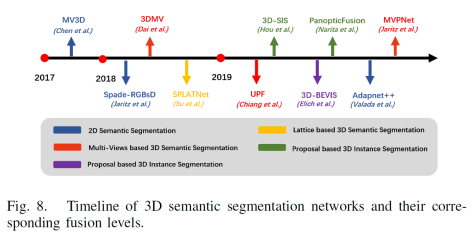
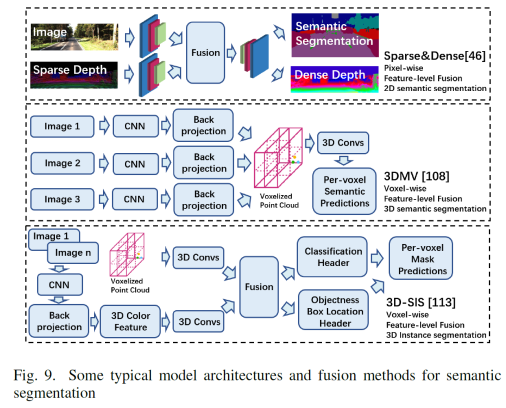
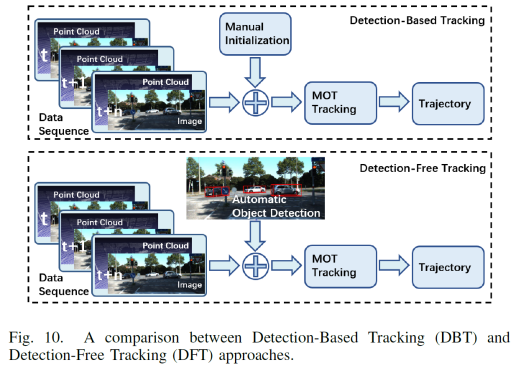
a)基于图像的深度学习方法 卷积神经网络(CNNs)是目前(2020年,因为2021年VIT大火)对图像理解和处理的最有效的模型之一。与MLP相比,CNN具有平移不变性,利用较少的权重和层次模式(卷积层、BN层、relu层、pooling层),可以以抽象的层次和学习能力完成对图像特征的提取和高阶语义的学习。 b)基于点云的深度学习方法 对于点云的方法,有很多种类型,如 b1)Volumetric representation based,即将点云按照固定的分辨率组成三维网格,每个网格的特征都是学出来的;这种方法可以很轻松的获取到网格内部结构,但在体素化过程中,失去了空间分辨率和细粒度的三维几何形状; b2)Index/Tree representation based,是将点云划分为一系列不平衡的树,可以根据区域的点密度进行分区,对于点密度较低的区域具有较低的分辨率,从而减少不必要的内存和计算资源; b3)2D views representation based,这种方式比较好理解,就是将点云按照不同的视图投影成深度图,然后利用CNN对图像进行检测; b4)Graph representation based,这种就是将点云表示为图,在空间或者光谱域上实现卷积操作。(这种吧,不太好评价) b5)Point representation based,这种直接适用点云,而不是将其转换为中间数据进行表示。这个也是目前点云深度学习的最流行的方式。如点网方法(PointNet,PointNet++,RandLA-Net等),点卷积是直接表征点之间的空间关系,其目的是将标准的二维离散卷积推广到三维连续空间中,即用连续权重函数替代离散权重函数,如PointConv、KPConv等。 深度估计 所谓深度估计,就是将稀疏的点云通过上采样方法生成稠密有规则地深度信息,这样生成的点云方便后续感知模块的应用,也能够改善激光雷达扫描得到点云的不均匀分布。直接给出最近的深度估计发展历程和相关方法: 不管哪种方法,其核心就是将图像的RGB信息与点云的3D几何信息相结合,从而使得图像RGB信息包含相关的3D几何信息。所以,图像可以作为深度采样的参考信息。从上面的方法可以看出,其包含Mono-Lidar融合方法和Stereo-Lidar融合方法。 Mono Camera and LiDAR fusion Mono-Lidar包含信号级、特征级、以及多层次融合: 其中信号级就是将点云深度图与图像结合,形成RGBD图像,然后将RGBD图像送入网络中。这种适配的网络有很多种,如Sparse-to-dense(基于ResNet的自动编码网络,但是真值比较难获取)、Self-supervised sparse-to-dense(Sparse-to-dense的改进,但只对静止物体有效,且输出的深度模糊)、CSPN(卷积空间网络,可以直接提取与图像相关的affinity 矩阵)、 CSPN++(CSPN改进版,可以动态调整卷积核大小)。 特征级融合就是分别将稀疏深度图和点云送入网络中,完成特征的提取,如:《Depth completion and semantic segmentation》(就是将图像和稀疏深度图先由NASNet进行编码处理,然后融合到共享解码器中,获得良好的深度效果)、Plug-and-Play(利用Pnp从稀疏深度图中计算梯度并更新现有深度图信息)、《Confidence propagation through cnns for guided sparse depth regression》(并行处理图像与稀疏深度映射,并归一化卷积来处理高度稀疏的深度和置信度)、《Self-supervised model adaptation for multimodal semantic segmentation》(将前面提到的单节段扩展到网络不同深度的多阶段)、GuideNet(将图像特征与不同层次的稀疏深度特征在编码其中进行融合,缺乏有效的gt)。 多层次融合就是把前两个做了一个融合。《“Sparse and noisy lidar completion with rgb guidance and uncertainty》(对RGBD数据和深度数据同时进行处理,然后根据置信图进行融合)。 Stereo Cameras and LiDAR fusion 这种方法相对于Mono,就是利用stereo相机之间的视差获取图像的深度值,然后结合稀疏的点云深度信息产生更精确的密集深度。如《“High-precision depth estimation using uncalibrated lidar and stereo fusion》(两阶段CNN,第一阶段采用激光雷达与Stereo的视差获取融合视差,第二阶段将融合视差与左RGB图像融合在特征空间中,以预测最终的高精度视差,然后再进行三维重建)、《Noise-aware unsupervised deep lidar-stereo fusion》(不需要gt,直接适用图像、点云自身的损失进行端到端训练,好处就是不太关注于点云与图像之间的对齐信息)、类似的还有《Listereo: Generate dense depth maps from lidar and stereo imagery 》,但是不管哪种,由于stereo本身的局限性(基线、遮挡、纹理等),所以不太考虑用在自动驾驶中。 Dynamic Object Detection 目标检测(3D)的目标是在三维空间中定位、分类和估计有方向的边界框。自动驾驶动态目标检测,类别包括常见的动态道路对象(汽车、行人、骑车人等),方法主要有两种:顺序检测和单步检测。基于序列的模型按时间顺序由预测阶段和三维边界框(bbox)回归阶段组成。在预测阶段,提出可能包含感兴趣对象的区域。在bbox回归阶段,基于从三维几何中提取的区域特征对这些建议进行分类。然而,序列融合的性能受到各个阶段的限制。另一方面,一步模型由一个阶段组成,其中二维和三维数据以并行方式处理。下面两幅图,给出了3D检测网络的时间线和经典网络架构图。 下面两张表给出了在KITTI上3D检测的对比结果以及动态检测模型。 5A)基于2D的序列模型 所谓基于2D的序列模型,就是首先对图片进行2D检测/分割,生成ROI区域,然后将ROI投影到3D空间中(将图像上的边界框投影到点云上,形成三维ROI空间;将点云投影到图像平面上,形成带有点向的2D语义点云)。 结果级:就是将2D的ROI来限制点云的搜索空间,这样可以显著减少计算量,提高运行时间。如FPointNes《Frustum pointnets for 3d object detection from rgb-d data》(将图像生成的2D边界框投影到3D空间中,然后将产生的投影送入到PointNet中进行3D检测)、《A general pipeline for 3d detection of vehicles》(利用基于模型拟合的方法过滤掉不必要的背景点,然后将过滤后的点送入网络中进行回归)、RoarNet(利用《3d bounding box estimation using deep learning and geometry》将每个2Dbbox生成多个3D圆柱,然后利用PointNet的head去进行处理,并最终细化)。 上述方法都需要假设每个ROI区域内只包含一个感兴趣的对象,对于拥挤的场景或者行人等不太适用。所以需要有改进版。解决方案就是用二维语义分割和region-wise seed proposal with point-wise seed proposals替代2D检测器,如IPOD就是类似的方法,首先采用二维语义分割来过滤出背景点,留下的前景点云保留了上下文信息和细粒度的位置,然后送入到PointNet++中用于特征提取和bbox的预测,这里提出了PointsIoU来加速训练和推理。 特征融合:最直观的就是将点云投影到图像上,然后利用图像处理方法进行特征提取,但输出也是图像级,对于3D空间的定位不是很准确。如DepthRCNN就是一种基于RCNN的二维对象检测、实例和语义分割架构。《Cross modal distillation for supervision transfer》则是在图像数据和深度图像之间做迁移,当然还有其他,这一块后续会专门介绍。 多级融合,这个其实是结果级融合与特征级融合的结合,主要工作可以归结为点融合(Pointfusion),点融合首先利用现有的2D检测模型生成2D bbox,然后用于通过向图像平面的投影点来定位通过方框的点,最后采用一个ResNet和一个PointNet结合的网络将点云与图像特征结合来估计3D目标。类似的方案还很多,如SIFRNet、Pointsift。 5B)基于3D的模型 略(个人对这一块很感兴趣,会专门对提到的文章进行阅读,见谅)。 Stationary Road Object Detection 静止物体检测,其实对在线校准起到很大的作用。固定的道路物体包括路面、道路标记、交通标识牌等。 道路/车道检测,有很多方法,这里专门介绍一下基于深度学习的融合策略。可以分为基于BEV的方法或者基于前视图的方法。《Deep multi-sensor lane detection》利用CNN从点云中预测密集的BEV高度估计,然后与BEV图像融合,以进行精确的车道检测,但这种方法无法区分不同的车道类型。类似的还有《A novel approach for detecting road based on two-stream fusion fully convolutional network》。另外还有一种多阶段融合策略(MSRF)方法, 结合了不同网络层次的图像深度特征,显著提高了其性能,但也增加了计算成本。《Early fusion of camera and lidar for robust road detection based on u-net fcn》使用信号级融合生成一个融合的BEV特征,并基于UNet来进行道路分割,但这种方法容易导致密集纹理信息的丢失。 基于前视图的方法主要讲激光雷达深度投影到前视图平面上,以提取路面,这类方法在3D投影2D时存在精度损失,方法有:《Lidarcamera fusion for road detection using fully convolutional neural networks》、《Progressive lidar adaptation for road detection》、《Fast road detection by cnn-based camera-lidar fusion and spherical coordinate transformation》。 交通标志牌检测,这种方法太多了,主要是因为交通标识牌具有较高的反射特性,但缺乏密集的纹理,而图像则可以很好的对其进行分类,所以都是讲相机与点云进行结合,即利用了图像的纹理信息,也利用了标识牌对点云的高反射特性,形成一个带有色彩的点云。 Semantic Segmentation 前面已经有了基于检测的融合方法,这里还有基于分割的融合方法,旨在预测每个像素与每个点的类标签。下面两幅图给出了3D语义分割和典型模型架构的时间线。 7a)二维语义分割 2D语义分割方法有很多种,大多是将点云深度图和图像进行特征提取,然后利用图像与深度的2D语义分割和深度完成,如《Sparse and dense data with cnns : Depth completion and semantic segmentation》。当然也有不同的方法进行特征提取和融合,如《Self-supervised model adaptation for multi modal semantic segmentation》采用了不同深度的多阶段特征级融合,以促进语义分割。《Lidarcamera fusion for road detection using fully convolutional neural networks》则是利用上采样的深度图像和图像进行2D语义分割。《Pedestrian detection combining rgb and dense lidar data》则是对rgb和稠密点云进行上采样并分别进行CNN特征提取,在最终的卷积层融合两个特征图。 7b)三维语义分割 3D语义分割,根据对点云的处理方法,可以分为不同的方法,如:基于点云体素的3DMV(从多个对齐的图像中提取2D特征,然后投影到3D空间内,并与3D几何图像融合,并最终输入到3DCNN中进行语义预测),为了减轻点云体素化引起的问题,还有UPF(该方法利用语义分割网络提取渲染的多视图图像的特征,并投影到三维空间进行点特征融合,其中点云由两个基于PointNet++的编码器进行处理,提取局部和全局特征,然后进行点的语义标签预测)、MVPNet(可以理解为融合了多视图图像语义和三维几何图形来预测每点的语义标签)等。 SPLATNet是一种多模态数据融合的方法,主要采用稀疏双边卷积来实现空间感知表示学习和多模态(图像和点云)推理。(个人觉得这篇文章的思路比较独特,后面会专门解读)。 7c)实例分割 实例分割本质上是语义分割和目标检测的联合。用于区分类中的单个实例来扩展语义分割任务。实例分割包括Proposal-based和Proposal-free-based两种。 Proposal-based包括3D-SIS(基于ENet对多视图提取特征,和下采样,实现解决高分辨率图像特征与低分辨率像素化点云特征图不匹配问题的RGB-D体素实例分割的3DCNN网络)和Panoptic-fusion(以RGB和深度图作为输入,然后通过关联和积分方法跟踪帧之间的标签,并适用CRF来进行深度和语义分割,但这种方法不适合动态场景)。 Proposal-free-based代表性的为3DBEVIS,该方法主要是适用2D语义信息点在聚类方法上联合执行3D语义和实例分割任务。具体如下图: Objects Tracking 谈到融合,不得不提跟踪,而目标跟踪,是基于历史帧数据信息对目标障碍物的长期监测。在实际应用中,MOT是很常见的场景,而MOT算法又可以分为基于检测的跟踪(DBT)和不基于检测的跟踪(DFT)。 DBT:其实就是逐帧进行检测,然后通过数据关联或者多个假设来进行对象跟踪。这种类型的算法也是目前最流行,最容易出成果的。主要包括两部分:检测目标,将目标进行关联。比较常用的方法包括《End-to-end learning of multi-sensor 3d tracking by detection》(该方法同时检测图像和点云,然后通过深度结构化模型DSM对连续帧的目标进行匹配和优化),《Robust multi-modality multi-object tracking》(该方法包括检测、相邻帧估计以及在线优化等,在检测阶段使用VGG16和PointNet进行图像和点云的特征提取,然后使用(A模型+多模态)鲁棒融合模块进行融合,然后通过adjacent matrix learning 将adjacency estimation扩展到多模态,并求min-cost flow,从而计算出一个最优的路径。 另外,跟踪和三维重建也可以同时进行。《Track to reconstruct and reconstruct to track》就是这么一种方法,其利用三维重建来进行跟踪,使跟踪对遮挡有很好的鲁棒性。当然,MOTSFusion也可以将lidar、mono和stereo depth进行融合。 DFT:主要是基于 finite-setstatistics(FISST,这个在NLP或者情感分析中用的比较多)进行状态估计,常见的方法包括多目标多伯努利(MeMBer)滤波器和概率假设密度(PHD)滤波器。比较经典的如Complexer-yolo就是将图像和点云数据进行解耦,然后进行3D检测和跟踪的实时框架,该方法采用了尺度-旋转-转换分数(SRTS)的度量来取代IOU,并评估bbox位置的3个自由度。当然,该方法最终通过带有标记的伯努利随机有限集滤波器(LMBRFS)来实现推理过程。 Online Cross-Sensor Calibration 所谓的在线cross-sensor calibration,就是将激光雷达与相机之间进行在线校准,也就是所谓的空间同步,由于机械本身的振动,传感器之间的外参不断地变化,这会导致融合算法的性能和可靠性。所以online cross-sensor calibration的意义重大。 经典的在线校正,更多的是利用自然环境进行校准。如《Cross-calibration of push-broom 2d lidars and cameras in natural scenes》、《Automatic calibration of lidar and camera images using normalized mutual information》、《Automatic extrinsic calibration of vision and lidar by maximizing mutual information》、《Hybrid online mobile laser scanner calibration through image alignment by mutual information》是基于最大化不同模式之间的相互信息(原始强度值或边缘强度)发现外在的信息,但基于Mi的方法对纹理变化、传感器抖动不是很友好。而《Visual odometry driven online calibration for monocular lidar-camera systems》采用相机的自身运动估计来评估相机与激光雷达的外参,这话方法计算量较大,无法实时运行。 基于DL的在线校准,主要是为了解决传统方法实时性不好的情况,RegNet就是一个实时的用于估计外参的网络,它是在两个平行分支中提取图像和深度特征,然后将它们连接起来生成融合特征图,然后将该特征图送入到一个NiN加2个FC的网络中,进行特征匹配和全局回归。但RegNet对传感器的固有参数敏感,如果内参发生了变化,就需要重新训练。为了是模型对传感器不内参不敏感,Calibnet采用几何自监督的方法,将点云与单目图像以及相机外参矩阵K输入到网络中,然后实现3D点云与2D图像之间6自由度刚体转换,有效的降低了校准的工作量。但基于深度学习的校验方法,计算量比较大,计算资源消耗较多。 目前已经有越来越多的研究在关注于关于点云和图像的融合,除了融合方法外,也需要考虑激光雷达与相机之间的时空同步,尤其是两者之间的rotation的变化。而且不光要考虑点云和图像之间的关系,还需要加入IMU信息或者HD信息,来更准确的检测所关注的障碍物。另外,文章中的某些论文或章节,个人比较感兴趣,会详细阅读和整理。所以这里没有贴出来。本文仅做学术分享,如有侵权,请联系删文。












 下载APP
下载APP