
伴鱼:借助 Flink 完成机器学习特征系统的升级
一、前言
在伴鱼,我们在多个在线场景使用机器学习提高用户的使用体验,例如:在伴鱼绘本中,我们根据用户的帖子浏览记录,为用户推荐他们感兴趣的帖子;在转化后台里,我们根据用户的绘本购买记录,为用户推荐他们可能感兴趣的课程等。
二、旧版特征系统 V1
特征系统 V1 由三个核心组件构成:特征管道,特征仓库,和特征服务。整体架构如下图所示:
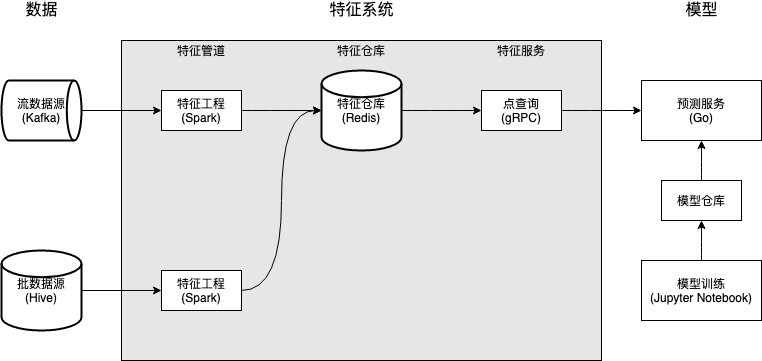
批特征管道使用 Spark 实现,由 DolphinScheduler 进行调度,跑在 YARN 集群上;
出于技术栈的一致考虑,流特征管道使用 Spark Structured Streaming 实现,和批特征管道一样跑在 YARN 集群上。
伴鱼有丰富的 Redis 使用经验;
包括 DoorDash Feature Store [1] 和 Feast [2] 在内的业界特征仓库解决方案都使用了 Redis。
特征服务屏蔽特征仓库的存储和数据结构,对外暴露 RPC 接口 GetFeatures(EntityName, FeatureNames),提供对特征的低延迟点查询。在实现上,这一接口基本对应于 Redis 的 HMGET EntityName FeatureName_1 ... FeatureName_N 操作。
算法工程师缺少控制,导致迭代效率低。这个问题与系统涉及的技术栈和公司的组织架构有关。在整个系统中,特征管道的迭代需求最高,一旦模型对特征有新的需求,就需要修改或者编写一个新的 Spark 任务。而 Spark 任务的编写需要有一定的 Java 或 Scala 知识,不属于算法工程师的常见技能,因此交由大数据团队全权负责。大数据团队同时负责多项数据需求,往往有很多排期任务。结果便是新特征的上线涉及频繁的跨部门沟通,迭代效率低;
特征管道只完成了轻量的特征工程,降低在线推理的效率。由于特征管道由大数据工程师而非算法工程师编写,复杂的数据预处理涉及更高的沟通成本,因此这些特征的预处理程度都比较轻量,更多的预处理被留到模型服务甚至模型内部进行,增大了模型推理的时延。
将控制权交还算法工程师,提高迭代效率;
将更高权重的特征工程交给特征管道,提高在线推理的效率。
三、新版特征系统 V2
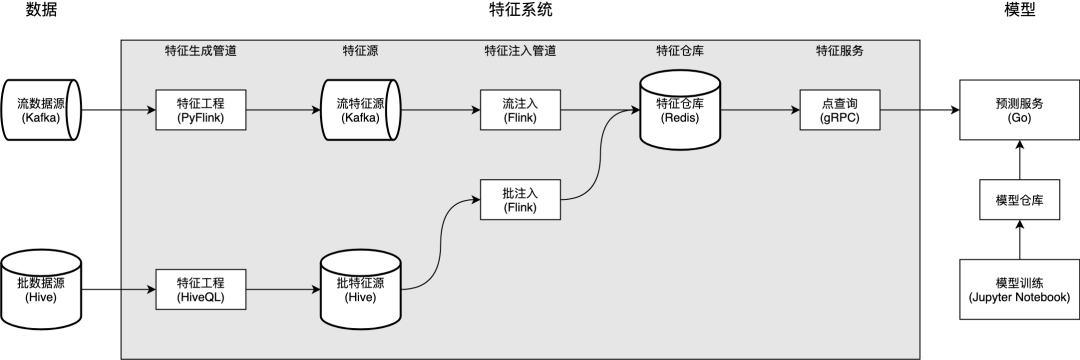
1. 特征生成管道
如果管道以流数据源作为原始数据源,则它是流特征生成管道;
如果管道以批数据源作为原始数据源,则它是批特征生成管道。
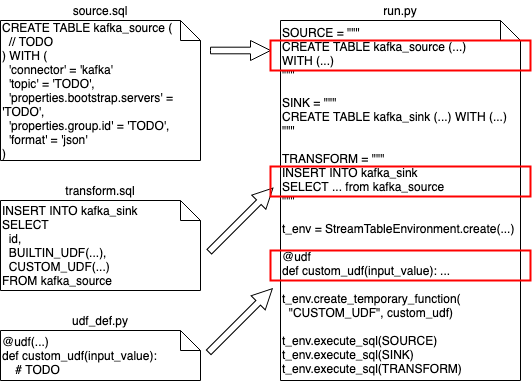
用 Flink SQL 声明 Flink 任务源 (source.sql) 和定义特征工程逻辑 (transform.sql);
(可选) 用 Python 实现特征工程逻辑中可能包含的 UDF 实现 (udf_def.py);
使用自研的代码生成工具,生成可执行的 PyFlink 任务脚本 (run.py);
本地使用由平台准备好的 Docker 环境调试 PyFlink 脚本,确保能在本地正常运行;
把代码提交到一个统一管理特征管道的代码仓库,由 AI 平台团队进行代码审核。审核通过的脚本会被部署到伴鱼实时计算平台,完成特征生成管道的上线。
算法工程师掌握上线特征的自主权;
平台工程师把控特征生成管道的代码质量,并在必要时可以对它们实现重构,而无需算法工程师的介入。
2. 特征源
3. 特征注入管道
StreamRedisSink 和 BatchRedisSink,很好地满足我们的需求。BatchRedisSink,通过 Flink Operator State [4] 和 Redis Pipelining [5] 的简单结合,大量参考 Flink 文档中的 BufferingSink,实现了批量写入,大幅减少对 Redis Server 的请求量,增大吞吐,写入效率相比逐条插入提升了 7 倍 [6]。BatchRedisSink 的简要实现如下。其中,flush 实现了批量写入 Redis 的核心逻辑,checkpointedState / bufferedElements / snapshotState / initializeState 实现了使用 Flink 有状态算子管理元素缓存的逻辑。class BatchRedisSink(pipelineBatchSize: Int) extends RichSinkFunction[(String, Timestamp, Map[String, String])]with CheckpointedFunction {@transientprivate var checkpointedState: ListState[(String, java.util.Map[String, String])] = _private val bufferedElements: ListBuffer[(String, java.util.Map[String, String])] =ListBuffer.empty[(String, java.util.Map[String, String])]private var jedisPool: JedisPool = _override def invoke(value: (String, Timestamp, Map[String, String]),context: SinkFunction.Context): Unit = {import scala.collection.JavaConverters._val (key, _, featureKVs) = valuebufferedElements += (key -> featureKVs.asJava)if (bufferedElements.size == pipelineBatchSize) {flush()}}private def flush(): Unit = {var jedis: Jedis = nulltry {jedis = jedisPool.getResourceval pipeline = jedis.pipelined()for ((key, hash) <- bufferedElements) {pipeline.hmset(key, hash)}pipeline.sync()} catch { ... } finally { ... }bufferedElements.clear()}override def snapshotState(context: FunctionSnapshotContext): Unit = {checkpointedState.clear()for (element <- bufferedElements) {checkpointedState.add(element)}}override def initializeState(context: FunctionInitializationContext): Unit = {val descriptor =new ListStateDescriptor[(String, java.util.Map[String, String])]("buffered-elements",TypeInformation.of(new TypeHint[(String, java.util.Map[String, String])]() {}))checkpointedState = context.getOperatorStateStore.getListState(descriptor)import scala.collection.JavaConverters._if (context.isRestored) {for (element <- checkpointedState.get().asScala) {bufferedElements += element}}}override def open(parameters: Configuration): Unit = {try {jedisPool = new JedisPool(...)} catch { ... }}override def close(): Unit = {flush()if (jedisPool != null) {jedisPool.close()}}}
由于特征生成管道的编写只需用到 SQL 和 Python 这两种算法工程师十分熟悉的工具,因此他们全权负责特征生成管道的编写和上线,无需依赖大数据团队,大幅提高了迭代效率。在熟悉后,算法工程师通常只需花费半个小时以内,就可以完成流特征的编写、调试和上线。而这个过程原本需要花费数天,取决于大数据团队的排期;
出于同样的原因,算法工程师可以在有需要的前提下,完成更重度的特征工程,从而减少模型服务和模型的负担,提高模型在线推理效率。
四、总结
平台应该提供用户想用的工具。这与 Uber ML 平台团队在内部推广的经验 [7] 相符。算法工程师在 Python 和 SQL 环境下工作效率最高,而不熟悉 Java 和 Scala。那么,想让算法工程师自主编写特征管道,平台应该支持算法工程师使用 Python 和 SQL 编写特征管道,而不是让算法工程师去学 Java 和 Scala,或是把工作转手给大数据团队去做;
平台应该提供易用的本地调试工具。我们提供的 Docker 环境封装了 Kafka 和 Flink,让用户可以在本地快速调试 PyFlink 脚本,而无需等待管道部署到测试环境后再调试;
平台应该在鼓励用户自主使用的同时,通过自动化检查或代码审核等方式牢牢把控质量。