
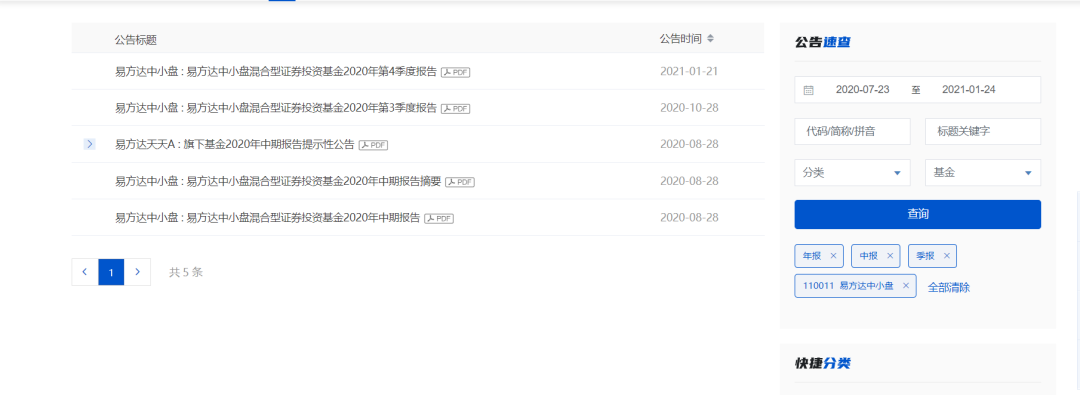
用python批量获取公募基金季报pdf
1


2
# 易方达中小盘
codes = '110011'
sdate = '20201231'
edate = '20210131'
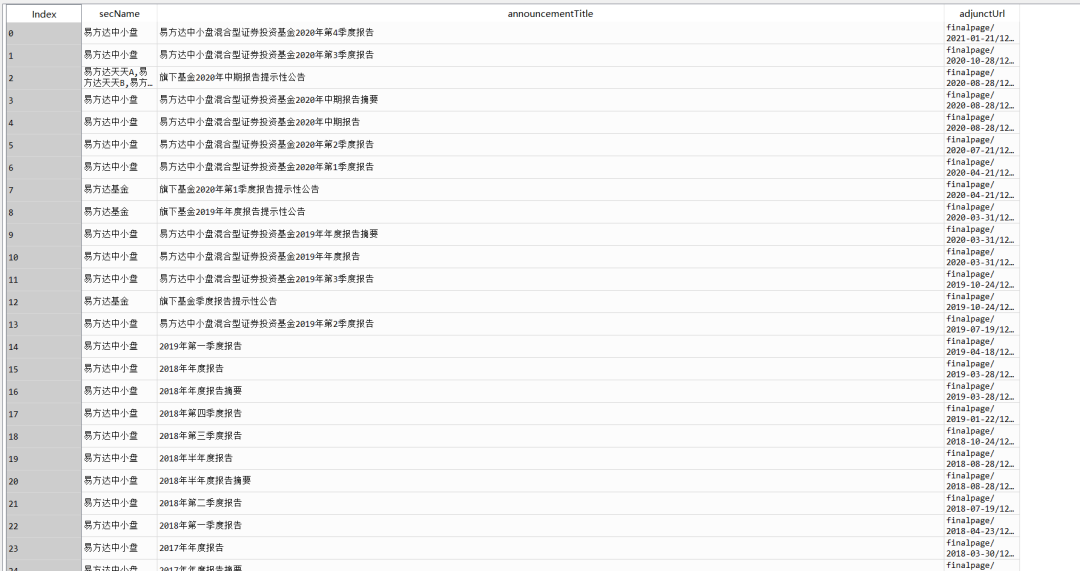
allpdf = getpdfurl(codes,sdate,edate)

# 易方达中小盘
codes = '110011'
sdate = '20151231'
edate = '20210131'
allpdf = getpdfurl(codes,sdate,edate)
fpath = 'E:\\基金公告\\pdf\\'
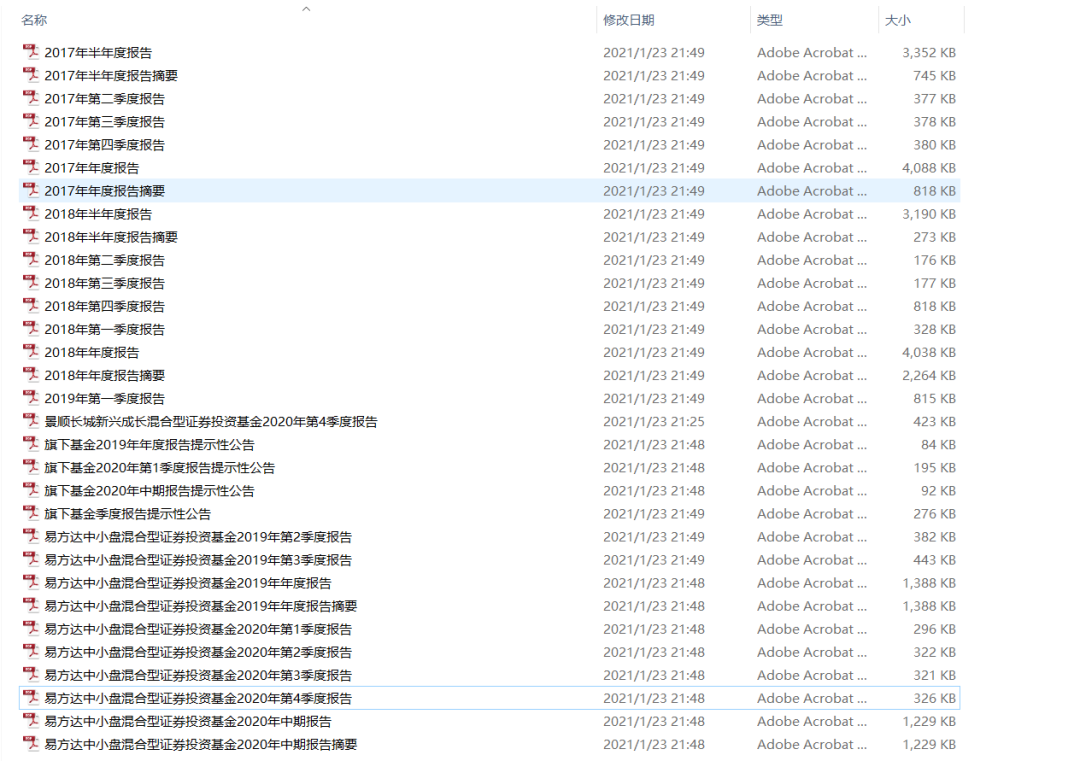
getFundReportpdf(allpdf,fpath)
3




import pandas as pd
import numpy as np
import os
import urllib
import requests
from fake_useragent import UserAgent
import json
import time
def getpdfurl(codes,sdate,edate):
sdate = pd.Timestamp(sdate).strftime('%Y-%m-%d')
edate = pd.Timestamp(edate).strftime('%Y-%m-%d')
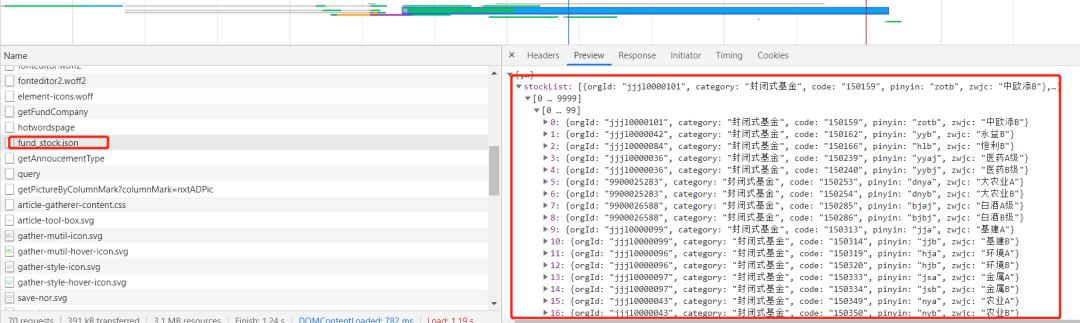
ords = a[codes]
stocks = codes + ',' + ords
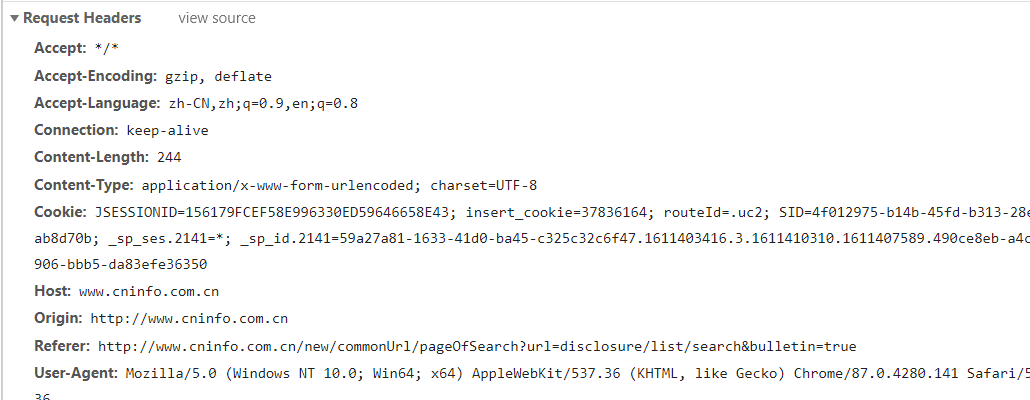
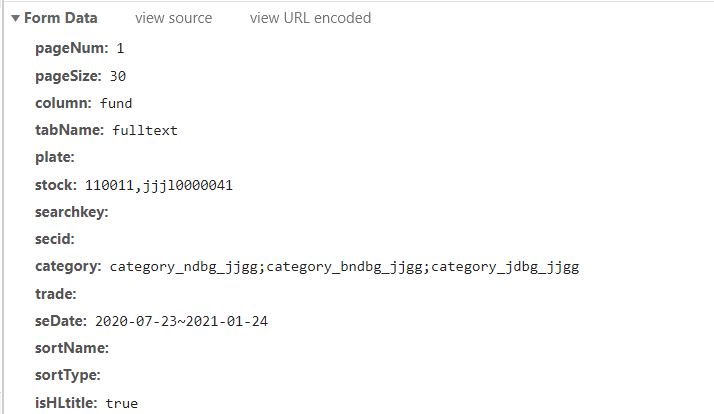
params = {
'pageNum': '1',
'pageSize': '30',
'column': 'fund',
'tabName': 'fulltext',
'plate':'' ,
'stock': stocks,
'searchkey':'' ,
'secid':'' ,
'category': 'category_ndbg_jjgg;category_bndbg_jjgg;category_jdbg_jjgg',
'trade':'' ,
'seDate': '{}~{}'.format(sdate,edate),
'sortName': '',
'sortType': '',
'isHLtitle': 'true'}
url = 'http://www.cninfo.com.cn/new/hisAnnouncement/query'
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
response_comment = requests.post(url,params = params,headers = headers )
res = json.loads(response_comment.text)
n = len(res['announcements'])
allpdf = []
for k in range(n):
allpdf.append(pd.DataFrame.from_dict(res['announcements'][k],orient='index').T)
allpdf = pd.concat(allpdf,axis = 0).reset_index(drop = True)
allpdf = allpdf[['secName','announcementTitle','adjunctUrl']]
return allpdf
def getFundReportpdf(allpdf,fpath):
headers = {"User-Agent": UserAgent(verify_ssl=False).random}
for k in range(allpdf.shape[0]):
url = allpdf.adjunctUrl[k]
urls = 'http://static.cninfo.com.cn/{}#navpanes=0&toolbar=0&statusbar=0&pagemode=thumbs&page=1'.format(url)
fname =allpdf.announcementTitle[k]
r = requests.get(urls, timeout = 300,headers = headers)
with open (fpath + '{}.pdf'.format(fname),'wb') as f:
f.write(r.content)
f.close()
time.sleep(2)
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)

评论