
用 Python 批量提取 PDF 的表格数据,保存为 Excel
作者:python与数据分析
链接:https://www.jianshu.com/p/1e796605248e
公众号后台回复:「Python提取PDF数据」,即可获取本文完整数据。
需求:想要提取 PDF 的数据,保存到 Excel 中。虽然是可以直接利用 WPS 将 PDF 文件输出成 Excel,但这个功能是收费的,而且如果将大量 PDF转 Excel 的时候,手动去输出是非常耗时的。我们可以利用 Python 的第三方工具库 pdfplumber 快速完成这个功能。
一、实现效果图
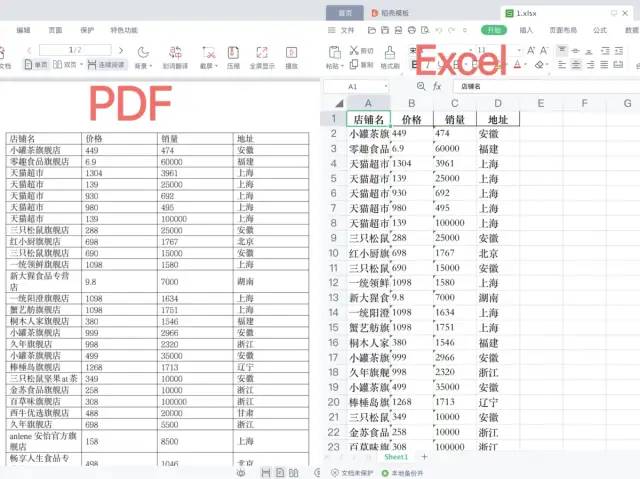
二、pdfplumber 库
pdfplumber 是一个开源 Python 工具库,可以方便获取 PDF 的各种信息,包括文本、表格、图表、尺寸等。完成我们本文的需求,主要使用 pdfplumber 提取 PDF 表格数据。
安装命令
pip install pdfplumber
三、代码实现
导入相关包
import pdfplumber
import pandas as pd
读取 PDF,并获取 PDF 的页数
pdf = pdfplumber.open("/Users/wangwangyuqing/Desktop/1.pdf")
pages = pdf.pages
提取单个 PDF 文件,保存成 Excel
if len(pages) > 1:
tables = []
for each in pages:
table = each.extract_table()
tables.extend(table)
else:
tables = each.extract_table()
data = pd.DataFrame(tables[1:], columns=tables[0])
data
data.to_excel("/Users/wangwangyuqing/Desktop/1.xlsx", index=False)
提取文件夹下多个 PDF 文件,保存成 Excel
import os
import glob
path = r'/Users/wangwangyuqing/Desktop/pdf文件'
for f in glob.glob(os.path.join(path, "*.pdf")):
res = save_pdf_to_excel(f)
print(res)
def save_pdf_to_excel(path):
# print('文件名为:',path.split('/')[-1].split('.')[0] + '.xlsx')
pdf = pdfplumber.open(path)
pages = pdf.pages
if len(pages) > 1:
tables = []
for each in pages:
table = each.extract_table()
tables.extend(table)
else:
tables = each.extract_table()
data = pd.DataFrame(tables[1:], columns=tables[0])
file_name = path.split('/')[-1].split('.')[0] + '.xlsx'
data.to_excel("/Users/wangwangyuqing/Desktop/data/{}".format(file_name), index=False)
return '保存成功!'
四、小结
Python 中还有很多库可以处理 pdf,比如 PyPDF2、pdfminer 等,本文选择 pdfplumber 的原因在于能轻松访问有关 PDF 的所有详细信息,包括作者、来源、日期等,并且用于提取文本和表格的方法灵活可定制。大家可以根据手头数据需求,再去解锁 pdfplumber 的更多用法。
原创推荐
太强了!Python 开发桌面小工具,让代码替我们干重复的工作!

评论