
Mysql8.0新特性【详细版本】
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | cao-lei
来源 | urlify.cn/VVzIZn

1. 账户与安全
用户创建与授权
之前:创建用户并授权
1 grant all privileges on *.* to 'myuser'@'%' identified by '3edc#EDC';
2 select user, host form mysql.user;
之后:创建用户和授权必须分开
1 create user 'myuser'@'%' identified by '3edc#EDC';
2 grant all privileges on *.* to 'myuser'@'%';
3 select user, host form mysql.user;
认证插件更新
1 show variables like 'default_authentication%';
2 select user, host, plugin from mysql.user;
之前:mysql_native_password
之后:caching_sha2_password
1 #修改为之前的认证插件
2 #方法一 修改配置文件
3 default-authentication-plugin=mysql_native_password
4 #方法二 修改用户密码指定认证插件
5 alter user 'myuser'@'%' identified with mysql_native_password by '3edc#EDC';
密码管理
【新增】允许限制使用之前的密码。
password_history=3 #不能和最近3天的密码相同
password_reuse_interval=90 #不能同90天内使用过得密码相同
password_require_current=on #修改密码时需要输入当前密码
show variables like 'password%';
#修改全局密码策略-按天设置
#password_history 与 password_reuse_interval设置方法相同
#方法一 添加配置文件
password_history=3
#方法二 持久化参数设置
set persist password_history=3;
#方法三 通过用户设置
alter user 'myuser'@'%' password history 5;
select user, hostm password_reuse_histtory from mysql.user;
#修改全局密码策略-输入密码设置
#只针对普通用户有效,针对root等具有修改mysql.user表权限的用户无效
set persist password_require_current=on;
alert user user() identified by 'newpassword' replace 'oldpassword';角色管理
【新增】根据角色设置用户权限
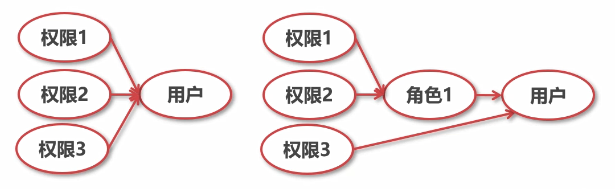
#创建角色
creaye role 'role_1_wirte';
#角色即用户
select user, host, authentication_string from mysql.user;
#给角色授权
grant insert, update, delete on test_db.* to 'role_1_wirte';
#给用户赋予角色
grant 'role_1_wirte' on 'myuser';
#查询用户权限
show grant for 'myuser';
show grant for 'myuser' using 'role_1_wirte';
#用户启用角色(普通用户登录)
set role 'role_1_wirte';
#设置默认角色(root用户)
set default role all to 'myuser';
select * from mysql.default_roles;
select * from mysql.role_edges;
#撤销角色
revoke insert, update, delete, select on test_db from 'role_1_wirte';
show grant for 'role_1_wirte';
show grant for 'myuser' using 'role_1_wirte';2. 优化器索引
隐藏索引(invisible index)
【新增】不会被优化器使用,但仍然需要维护。
应用场景:软删除,灰度发布。
#创建数据库、表
create database test_db;
use test_db;
create table test1 (id int(11), parent_id int(11));
#创建普通索引和隐藏索引
create index id_idx on test1(id);
create index parent_id_idx on test1(parent_id) invisible;
#查看索引
show index from test1\G
#查询优化器
explain select * from test1 where id = 1;
explain select * from test1 where parent_id = 1;
#当前会话测试隐藏索引
set session optimizer_switch="use_incisible_indexes=on";
select @@optimizer_switch\G
explain select * from test1 where parent_id = 1;
#设置隐藏索引可见于隐藏
alter table test1 alter index parent_id visible;
alter table test1 alter index parent_id invisible;
#注意:主键不能设置隐藏索引降序索引(descending index)
之前:虽然可指定降序索引,实为升序索引。
之后:支持降序索引。
进InnoDB存储引擎支持降序索引,并且只支持BTree降序索引。
group by不在对结果隐式排序,需要使用order by进行排序。
#Mysql5.7创建降序索引
create table test2 (read_num int(5), wirte_num int(5), index read_wirte_idx(read_num asc, wirte_num desc));
show create table test2\G
#Mysql8.0创建降序索引
create table test2 (read_num int(5), wirte_num int(5), index read_wirte_idx(read_num asc, wirte_num desc));
show create table test2\G
insert into test2 values(100, 2),(200, 4),(300, 6);
#Mysql5.7和Mysql8.0上分别测试
explain select * from test2 order by read_num, wirte_num desc;
explain select * from test2 order by read_num desc, wirte_num;
#Mysql5.7和Mysql8.0上分别测试group by
select count(*) as cnt, wirte_num from test2 group by wirte_num;
select count(*) as cnt, wirte_num from test2 group by wirte_num order by wirte_num;函数索引
之前:虚拟列创建索引。
之后:支持索引中使用函数的值;支持降序索引;支持JSON数据索引;
原理:基于虚拟列功能实现。
#创建表和索引
create table test3 ( id varchar(10), login_code varchar(20));
create index login_code_func_idx on test3((upper(login_code)));
show create table test3\G
#测试函数索引
explain select * from test3 where upper(id);
explain select * from test3 where upper(login_code);
#JSON索引
create table test4 ( result_data json, index((cast(result_data->>'$.code' as char(3)))));
show create table test4\G
explain select * from test4 where cast(result_data->>'$.code' as char(3)) = '200';
#Mysql5.7虚拟列实现
create table test5 ( id varchar(10), login_code varchar(20));
alter table test5 add column username varchar(20) generated always as (upper(login_code));
insert into test5(id, login_code) values ('A001', 'alan');
create index login_code_idx on test3((upper(login_code)));
create index username_idx on test5(username);
explain select * from test5 where upper(login_code) = 'ALAN';3. 通用表表达式
非递归
【新增】支持通用表达式,及WITH子句。
1 #派生语句
2 select a.* from (select 1) as a;
3 #通用表达式
4 with b as (select 1) select b.* from b;
递归
【新增】递归查询使用recursive关键字。
#递归查询组织上级组织机构
create table org (id int(5), parent_id int(5), org_name varchar(20));
insert into org values (0, null, '总公司'),(1, 0, '研发部'),(2, 1, '开发部');
with recursive org_paths(id, parent_id, org_name, paths) as (
select id, parent_id, org_name, cast(id as char(5)) as path from org where parent_id is null
union all
select o.id, o.parent_id, o.org_name, concat(op.paths, '/', o.id) from org o join org_paths op on op.id = o.parent_id
) select * from org_paths where org_name = '开发部';递归限制
【新增】递归查询必须指定终止条件。
#Mysql8.0提供两个参数避免用户未指定终止条件
#① cte_max_recursion_depth
#默认1000
show variables like 'cte_max%';
#测试-死循环
with recursive cte(n) as (select 1 union all select (n+1) as n from cte) select * from cte;
#当前会话/持久化设置cte_max_recursion_depth
set session cte_max_recursion_depth=10;
set persist cte_max_recursion_depth=10;
#② max_execution_time
#默认无限制,单位毫秒
show variables like 'max_execution_time%';
#当前会话/持久化设置max_execution_time为1秒
set session max_execution_time=1000;
set persist max_execution_time=1000;
#使用递归生成100以内的斐波那切数列
with recursive cte (a, b) as ( select 0, 1 union all select b, a + b from cte where b < 100 ) select a from cte;4. 窗口函数
基本概念
【新增】窗口函数(window function),也成为分析函数。窗口函数和分组
聚合函数类似,但是每一行数据都会生成一个结果。
聚合窗口函数:sum、avg、count、max、min......
create table sales (id int(5), item_type varchar(20), brand varchar(20), sale_value int(10));
insert into sales values (1, '手机', '华为', 3999),(2, '手机', '小米', 2999),(3, '手机', 'OPPO', 1999),(4, '电脑', '联想', 7999),(5, '电脑', '戴尔', 5499),(6, '电脑', '华硕', 6899),(7, '耳机', '索尼', 120),(7, '耳机', '三星', 70);
#聚合函数-按商品分类统计总销售额
select item_type, sum(sale_value) as total_value from sales group by item_type order by total_value desc;
#分析函数-按商品分类统计总销售额
select id, item_type, brand, sum(sale_value) over (partition by item_type) as total_value from sales order by total_value desc;
专用窗口函数
create table test6(id int(2));
insert into test6 values (1),(3),(4),(4),(1),(6),(2),(7),(7),(8),(9),(0),(1
#增加序号列
select row_number() over (order by id) as row_num, id from test6;
#返回排序后的第一名
select id, first_value(id) over (order by id) as first_val from test6;
#返回排序后的最后一名
select id, last_value(id) over (order by id) as last_val from test6;
#返回每一行的后n名数据
select id, lead(id, 1) over (order by id) as lead_1 from test6;
select id, lead(id, 2) over (order by id) as lead_2 from test6;
#返回每一行的前n名数据
select id, lag(id, 1) over (order by id) as lag_1 from test6;
select id, lag(id, 2) over (order by id) as lag_2 from test6;
#查询排序后每一行数据占据总排行榜的百分位(若为4,则为四个扇区)
select id, ntile(3) over (order by id) as ntile_4 from test6;窗口定义
【新增】定义:
window_function(expr) over (
partition by xxx #分组,类似于group by
order by xxx #排序
frame_clause xxx #限制窗口函数,只在当前分组有效
)
#动态统计分组内的总和
select id, item_type, brand, sale_value, sum(sale_value) over (partition by item_type order by sale_value rows unbounded preceding) as dynamic_sum from sales order by item_type, sale_value;
#动态统计分组内的前一行和后一行和自己的平均值
select id, item_type, brand, sale_value, avg(sale_value) over (partition by item_type order by sale_value rows between 1 preceding and 1 following) as dynamic_sum from sales order by item_type, sale_value;
#动态统计第一名和最后一名,简化窗口函数定义
select id, item_type, brand, sale_value, first_value(sale_value) over w as first_val, last_value(sale_value) over w as last_val from sales window w as (partition by item_type order by sale_value rows unbounded preceding) order by item_type, sale_value;5. InnoDB增强
集成数据字典
【优化】简化information_schema表,提高访问性能。
提供了序列化字典信息(SDI)以及ibd2sdi工具。
#执行Shell
cd /var/lib/mysql
cd test_db/
ls
ibd2sdi test1.ibd > test1.sdi
#查看.sdi文件
cat test.sdiinnodb_read_only影响所有存储引擎;
show global variables like 'innodb_read_only%';
原子DDL操作
【新增】支持原子DDL操作。
注意:与表相关的原子DDL只支持InnoDB存储引擎。
一个原子DDL操作包括:更新数据字典表、存储引擎层操作、在binlog(二进制日志)中记录DDL操作。
支持表相关的DDL:数据库、表空间、表、索引的create、alter、drop,以及truncate table(删除表中所有记录);
支持其他的DDL:存储过程、触发器、视图、UDF(自定义函数)的create、alter、drop;
支持管理账户相关的DDL:用户角色的create、alter、drop,以及适用的rename(重命名),还有grant(授权)和revoke(撤销授权)语句。
create table test7 (id int(5));
#Mysql5.7
drop table test7, test77;
show tables;
#Mysql8.0
drop table test7, test77;
show tables;
drop table if exists test7, test77;
show tables;自增列持久化
之前:自增列计数器(auto_increment)的值只存储在内存中。
之后:自增列计数器的最大值写入redo log,同时每次检查点将其写入引擎私有的系统表,从而解决了自增列字段值重复的bug。
create table test8(id int auto_increment primary key, val varchar(5));
insert into test8(val) values ('a'),('b'),('c');
delete from test8 where id = 3;
select * from test8;
#重启Mysql,# systemstl restart mysqld
insert into test8(val) values ('d');
update test8 set id = 5 where val = 'a';
insert into test8(val) values ('e');
#查询Mysql自增列设置
show variables like 'innodb_autoinc%';Mysql8.0之前使用innodb_autoinc_lock_mode模式为1,及每次查询都会加锁,同时执行2个insert语句每个10条,会保证每次插入数据的自增列的连续性,
Mysql8.0之后使用的模式为2,及使用交叉锁,执行相同的insert语句,不能保证自增列的连续性,但可以并发保存。
死锁检查控制
【新增】增量变量innodb_deadlock_detect,用于控制系统是否执行InnoDB死锁检查。
高并发系统禁止死锁检查可能会提高性能。
show variables like 'innodb_deadlock_detect';
#关闭死锁检查
set global innodb_deadlock_detect=off;
#设置死锁默认等待时长,单位为秒,默认50
show variables like 'innodb_lock_wait%';
set global innodb_lock_wait_timeout=5;
#模拟死锁
create table test9(id int);
insert into test9 values(1);
#窗口1
#开始事务
start transaction;
#开启共享锁
select * from test9 where id = 1 for share;
#窗口2
#开始事务
start transaction;
delete from test9 where id = 1;
#窗口1
delete from test9 where id = 1;锁定语句选项
【新增】针对于select * from t for share和select * from t for update增加nowait和skip locked行级锁的限制。nowait表示不等待锁,若想获取被锁住的数据,则立即返回不可访问异常;skip locked表示跳过等待锁,若想获取被锁住的数据,则不返回该数据。
#窗口1
#开启是我
start transaction;
update test9 set id = 0 where id = 1;
#窗口2
#开启事务
start transaction;
select * from test9 where id = 1 for update;
#不等待锁
select * from test9 where id = 1 for update nowait;
#跳过锁
select * from test9 for update skip locked;其他
删除了之前版本的元数据文件,例如:.frm、.opt等;
默认字符集由latin1变为utf8mb4;
将系统表(mysql数据库)和数据字典由之前的MyISAM存储引擎改为InnoDB存储引擎。支持快速DDL,alter table ... algorithm =instant;
InnoDB临时表使用共享的临时表空间ibtmp1;
新增静态变量innodb_dedicated_server,会自动配置InnoDB内存参数:innodb_buffer_pool_size、innodb_log_file_size大小。
新增表information_schema.innodb_cache_indexes显示每个索引缓存在InnoDB缓冲池中的索引页数。
新增视图information_schema.innodb_tablespace_brief,为InnoDB表空间提供相关元数据信息。
支持alter tablespace ... rename to... ,重命名通用表空间。
默认创建2个undo表空间,不在使用系统表空间。
支持innod_directories选项在服务器停止时将表空间文件移动到新的位置。
InnoDB表空间加密特性支持重做日志和撤销日志。
redo & undo 日志加密,增加以下两个参数(innodb_undo_log_encrypt、innodb_undo_log_truncate),用于控制redo、undo日志的加密。innodb_undo_log_truncate参数在8.0.2版本默认值由OFF变为ON,默认开启undo日志表空间自动回收。innodb_undo_tablespaces参数在8.0.2版本默认为2,当一个undo表空间被回收时,还有另外一个提供正常服务。innodb_max_undo_log_size参数定义了undo表空间回收的最大值,当undo表空间超过这个值,该表空间被标记为可回收。
在sql语法中增加SET_VAR语法,动态调整部分参数,有利于提升语句性能。
1 select /*+ set_var(sort_buffer_size = 16M) */ id from test8 order by id;
2 insert /*+ set_var(foreign_key_checks=OFF) */ into test8 (id) values(1);
6. JSON增强
内联路径操作符
之前:json_unquote(column -> path) 或json_unquote(json_extract(column, path))
之后:column ->> path
with cte(data) as (select json_object('id','01','name','zhangsan')) select json_unquote(data -> '$.name') from cte;
with cte(data) as (select json_object('id','01','name','zhangsan')) select json_unquote(json_extract(data, '$.name')) from cte;
#使用内联路径操作符
with cte(data) as (select json_object('id','01','name','zhangsan')) select data ->> '$.name' from cte;
#区间查询-查询下标为1的值
select json_extract('["a", "b", "c", "d", "e", "f"]', '$[1]');
#区间查询-查询下标从0到3的值
select json_extract('["a", "b", "c", "d", "e", "f"]', '$[0 to 3]');
#区间查询-查询下标从最后3位到最后一个位的值
select json_extract('["a", "b", "c", "d", "e", "f"]', '$[last - 2 to last]');JSON聚合函数
【新增】Mysql8.0(Mysql5.7.22)增加了2个聚合函数:json_arrayagg()用于生产json数组,json_objectagg()用于生产json对象。
create table goods(id int(5), attribute varchar(10), data_value varchar(10));
insert into goods values (1, 'color', 'red'),(1, 'size', '10'),(2, 'color', 'green'),(2, 'size', '12');
#生成json数组
select id, json_arrayagg(attribute) as attribute_json from goods group by id;
#生产json对象
select id, json_objectagg(attribute, data_value) as attribute_json from goods group by id;
#对重复值处理
insert into goods values (2, 'color', 'white');
select id, json_objectagg(attribute, data_value) as attribute_json from goods group by id;JSON实用函数
【新增】Mysql8.0(Mysql5.7.22)增加了json_pretty()用于格式化json,增加了json_storage_size()用于查询json占用空间大小;
【新增】json_storage_free()用于查询更新列后释放的存储空间。
create table test10 (jdata json);
insert into test10 values ('{"id" : 1, "name" : "zhangsan", "age" : 18}');
#格式化json
select json_pretty(jdata) from test10;
#查询json字段占用大小
select json_storage_size(jdata) from test10;
#更新json
update test10 set jdata=json_set(jdata, "$.id", 2, "$.name", "lisi", "$.age", 4);
select json_storage_size(jdata) from test10;
#查询json字段更新后释放的大小
select json_storage_free(jdata) from test10;JSON合并函数
【新增】Mysql8.0(Mysql5.7.22)增加了json_merge_patch()和json_merge_preserve(),用于合并json数据,区别在于前者重复属性会使用最新的属性值,后者会保留所有的属性值。并且废弃了json_merge()函数。
#会覆盖旧值
select json_merge_patch('{"a" : 1 , "b" : 2}', '{"a" : 3, "c" : 4}');
#会保留所有值
select json_merge_preserve('{"a" : 1 , "b" : 2}', '{"a" : 3, "c" : 4}');
#json_merge()
select json_merge('{"a" : 1 , "b" : 2}', '{"a" : 3, "c" : 4}');
#查看警告
show warnings\GJSON表函数
【新增】json_table()格式化json为关系表。
select
*
from
json_table (
'[{"id" : "001"}, {"id" : "002"}, {"name" : "zhangsan"}, {"id" : "003"}, {"id" : [1, 2]}]',
"$[*]" columns (
row_num for ordinality,
uid varchar (20) path "$.id" default '999' on error default '111' on empty,
user_details json path "$.name" default '{}' on empty,
is_exists_name int exists path "$.name"
)
) as t;
粉丝福利:Java从入门到入土学习路线图
👇👇👇

👆长按上方微信二维码 2 秒
感谢点赞支持下哈 