
10 亿级流量的搜索前端,是怎么做架构升级的?

- 前言 -
前端发展飞速,从最开始的静态页面到 JavaScript,再从 PC 端到移动端,随着大前端的复杂度不断提升,很多公司开始前后端分离,剥离出前、后端架构设计。那我们来看看,前端架构设计是什么?曾经非常简单的前端架构发展到现在有哪些问题,遇到前端代码体量巨大、跨团队协作效率、代码耦合、技术栈落后等问题又该怎么解决?
- 什么是前端架构? -
前端架构这一词,相信很多人的定义都不太一样;按照拆词的解释来看,我理解为“前端”+“架构”。前端是指,Web 端的前台页面,包括网页的内容、样式、脚本等,这三者通常封装在组件中,可能是模板引擎的文件模块,也可能是 MVVM 框架里的组件。“架构”就更好理解了,架构一词来自建筑行业,可以理解是房屋的整体结构、框架。结合前端和架构的概念,“前端架构”可以理解为,Web 页面组件的抽象和组织方式。
又因为各个公司的业务不同,每个公司的前端架构发展都不一样,这里,我会拿百度移动端经典的搜索场景来给大家举例,希望从百度的移动端架构演进过程中,发现一些共性的问题。
- 百度移动端背景及问题 -
为什么是以百度来举例?是因为百度是国内搜索引擎的领头人,并且,目前一直处于行业领先状态。据 statcounter 前瞻产业研究院在 2019 年中国搜索引擎行中可以知道,百度搜索占全世界搜索引擎市场份额12.3%,居第二位,仅次于谷歌。所以用百度来举例,更具有代表性。
言归正传,打开百度 App 你会发现,百度前端直接分为首页和搜索结果页,搜索结果页是搜索的主要入口,每天承载着十亿级流量。
不仅如此,搜索结果页承载着许多产品线的需求和下游模块的运行时,每年内部的研发人员会提供五百多个产品需求,为十几个下游模块提供基础库和运行时。甚至还有后端协同,从图 1 我们可以看出结果页的整体架构。
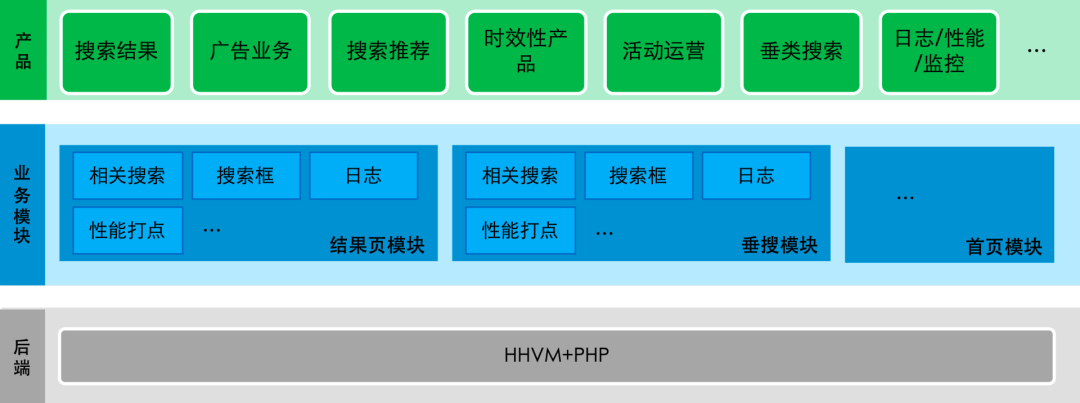
图 1:百度搜索结果页的整体架构
针对整体的架构设计,有这些问题:
细分业务线众多,单个库代码庞大;
平均每月有 200+ 提交,3w+ 行代码;
80+ 开发者在同一个代码库中开发;
没有人能完全掌握模块整体技术。
于是,梳理出三个方面的问题:
1. 人员职责不清晰,单个模块同时承担了多个团队的职责
框和 Tab:“全部”和垂类搜索共用;
运营产品:渗透在结果页代码库里;
其他:结果列表、用户反馈、搜索推荐、体验日志、速度日志、计费逻辑……
2. 代码耦合严重
容易出错,代码逻辑脆弱;
结构僵化,不易新增功能;
依赖牢固,代码很难复用。
3. 技术栈落后
页面没有组件化。没有 Vue、没有 React,还在用 Smarty 模板;
无法支持 Node.js。Smarty 模板强依赖 PHP 环境;
工具链落后。没有 TypeScript、没有 Jest。
这三个问题最终会影响到研发效率以及产品质量。那么百度又是怎么去具体做的呢?架构优化的目标只有两个,一是满足业务需求,二是技术上能对框架和工具灵活升级(也是为了持续的满足业务需求)。根据“满足业务需求”这一目标,百度内部是制定了三个层面的方向。(如图 2)
底层基础层是贴近社区,因为据内部调研来看,造轮子的成本不高,但是维护这些轮子成本极高,如果想更快的迭代,还是建议贴近社区,去用些开源的事情或者去贡献开源。主要是解决技术栈落后以及职责不清晰等问题。
中间层是独立模块,主要是应对之前提到的职责不清晰的问题以及交付效率低等问题。主要是解决职责不清晰以及交付效率低等问题。
顶层就是组件化,在独立模块的基础上去做组件化,加速业务的迭代。
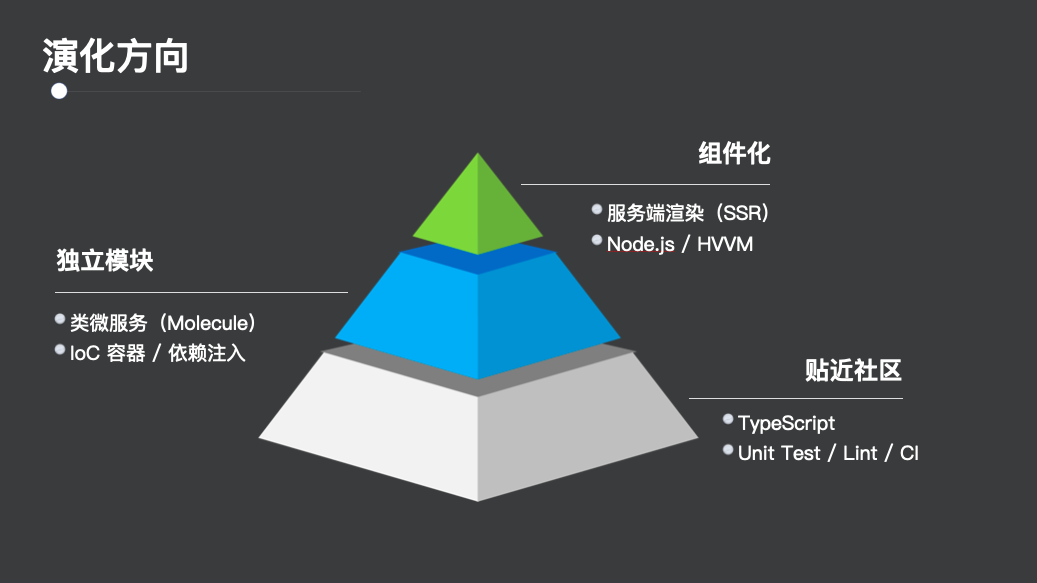 图 2:业务需求的三个方向
图 2:业务需求的三个方向
- 解决思路 -
根据这里提到的方向和目标,怎么结合百度自己的架构落地呢?首先,回顾下百度的架构,如下图 3 可以看到。
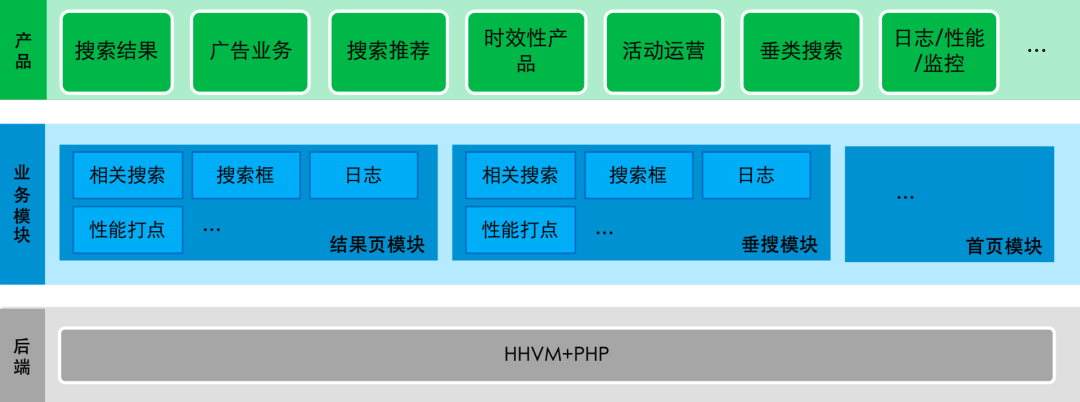
图 3:百度搜索结果页的整体架构
1. 这里有两块日志,意味着同一套代码要在两个部分维护;除了重复之外,它们的差异会对后续的维护引入更高的成本;
2. 底层这个 HHVM+PHP 和社区更加拥抱 Node.js 会有冲突。
所以,百度同学把目标架构调整为图 4 所示。
 图 4:结果页的目标架构
图 4:结果页的目标架构
图 4 中可以看到:
把日志、搜索框、相关搜索、性能打点等独立成单独的模块,有专门的同学来独立维护和迭代;
在前后端之间加了一层渲染层;让业务代码和后端的逻辑分开;
在底层加了 Node.js 机制。
目标、方向都解决好之后,就得看如何实施。对于一个小体量的库来说,从零构建架构就行;但是对于百度来说,实施也是难点。不仅要考虑平滑迁移、性能不退化,还要考虑长期可维护性、安全性、跨平台等。
前文也提到了,基本思路是按照基础设施、模块拆分、组件化的步骤执行;基础设施是业务模块划分的关键,完善的自动化和工具链是模块化的前提;模块化拆分可以为业务和团队提供更好的横向扩展能力;模块化的基础上,可以进一步在模块内部建设组件化方案来加速业务迭代。
在基础设施需要关注的事情包括:
TypeScript:大型项目必备,提前发现问题;也是跨平台的基础;
持续集成:确保每次变更新增功能和修复问题的同时,不引入新的问题;
单元测试:在重构之初引入,帮助防退化和辅助设计。
模块化拆分需要关注的事情包括:
识别和定义业务边界,把大一统的仓库分割成若干独立的小仓库;
在子模块内建设自动化机制,独立地选型、开发、上线。
注意:
模块化拆分不是技术问题,而是业务问题。只有根据业务和产品进行垂直划分,才有可能达到解耦和独立迭代的目的。否则只是形式上拆分耦合的代码,会造成更大的维护和沟通成本。
由于组件是业务模块内部的选型,组件化的方案相对比较自由。只需要不严重影响性能,且能够平滑过渡即可。
- 落地方案 -
1. 模块化
具体的落地方案,我们也用一张图(图5)来表示。可以看到它分为服务端和浏览器端两部分。
服务端关心的问题是业务模块的划分以及运行时的组合;
浏览器端关心的问题是依赖的解决以及如何支持组件化方案。
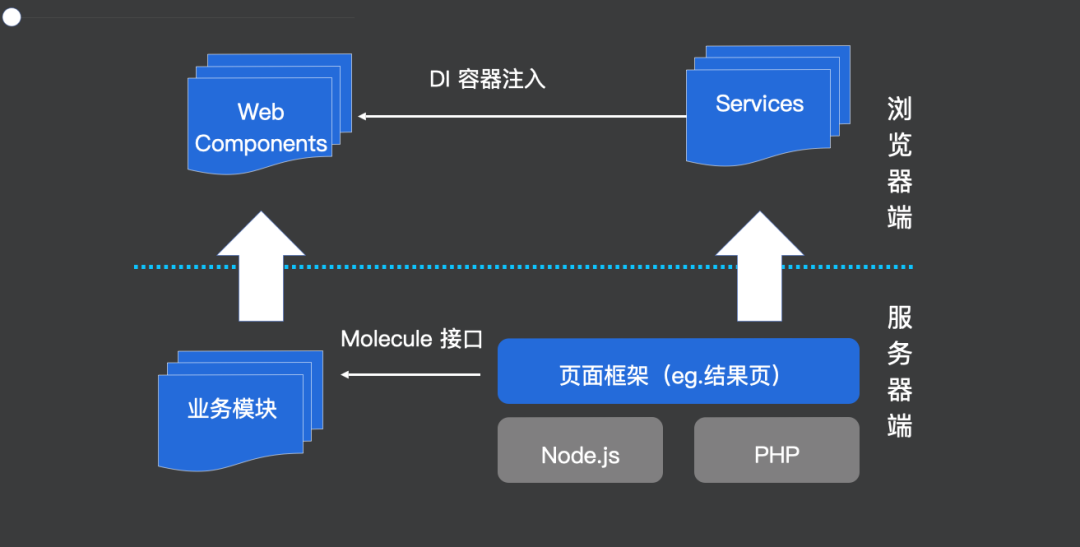 图 5:具体的落地方案
图 5:具体的落地方案
2. 服务端
百度是把整个大模块拆分成多个独立业务模块,最终页面由模块组合而成。这要求业务模块具有统一的接口,即上图所示的 Molecule 接口,它定义了模块如何渲染、有哪些依赖等信息。因为渲染过程封装在了模块内部,所以整个架构可以支持多语言、多框架。
相信你也发现,Molecule 和微服务非常相似。它们的关键区别在于,微服务的服务之间通过 IPC 互相操作,且每个服务可以独立伸缩、独立部署;而 Molecule 的各模块存在于同一个进程里。虽然有这样的区别,Molecule 仍然可以实现和微服务近乎相同的特性,如图 6 所示。
 图 6:Molecule 和微服务的比较
图 6:Molecule 和微服务的比较
图 7 展示的是一个具体的业务模块的服务端入口文件,其中 ToptipController 是实现了由 Molecule 提供的控制器接口;这个接口要求提供一个渲染函数,接受一个字典类型的数据,返回渲染之后的页面内容。由调用方决定如何组装页面。
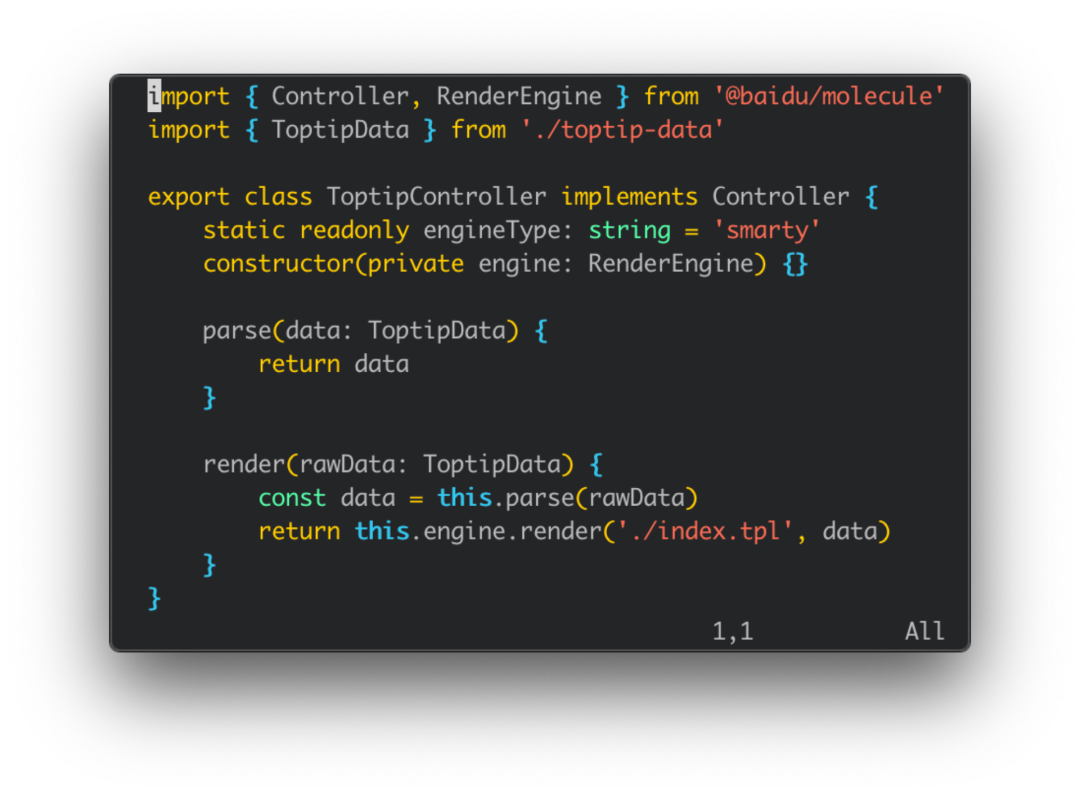 图 7:具体的业务模块的服务端入口文件
图 7:具体的业务模块的服务端入口文件
如上是业务模块提供方的接口。此外 Molecule 机制还为调用方(组装最终页面的那一侧)提供了方便的接口,可以在需要引入子模块的地方,传入子模块名称和参数即可在运行时渲染出来。整个机制的原理很简单,但实际使用中可能还需要引入命名空间、考虑模块版本等问题。
3. 客户端
那么客户端如何运行起来呢?我们也需要把每个模块的浏览器端组件运行起来,困难在于组件之间的依赖和代码共享。这些组件可能位于不同的代码库并属于不同的业务,所以我们需要一个非常松散的依赖方式。
这里我们引入的是一个依赖注入的容器(图 8),总的来说,框架逻辑和通用工具都封装成具体的Service提供给业务模块使用,每个业务模块则需要定义它依赖于哪些Service。
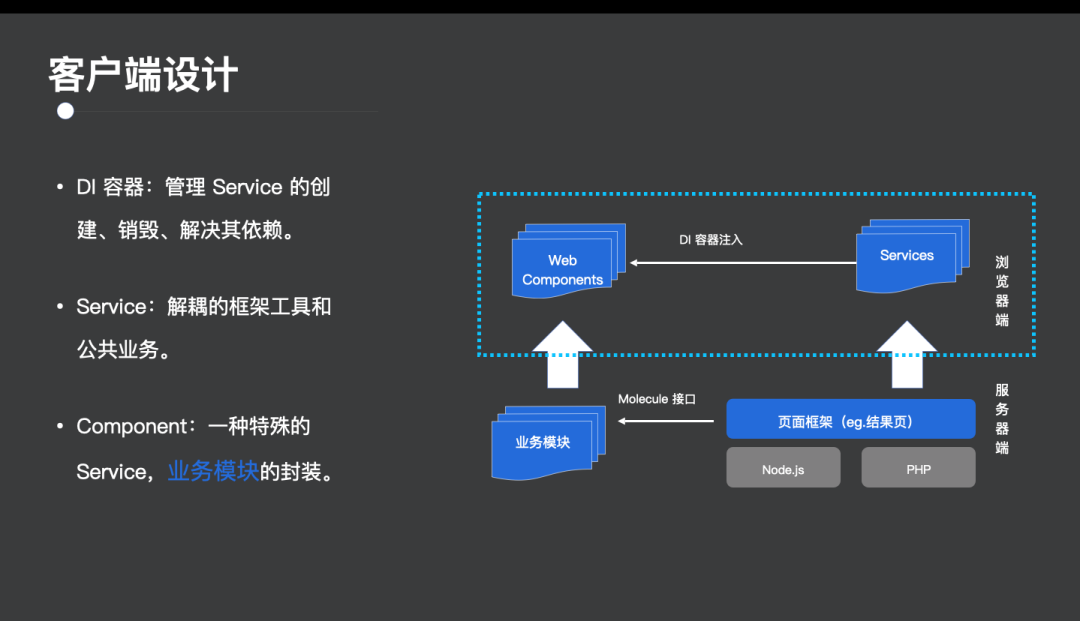 图 8:客户端设计
图 8:客户端设计
图 9 形象地描述了组件、Service 和容器间的关系。
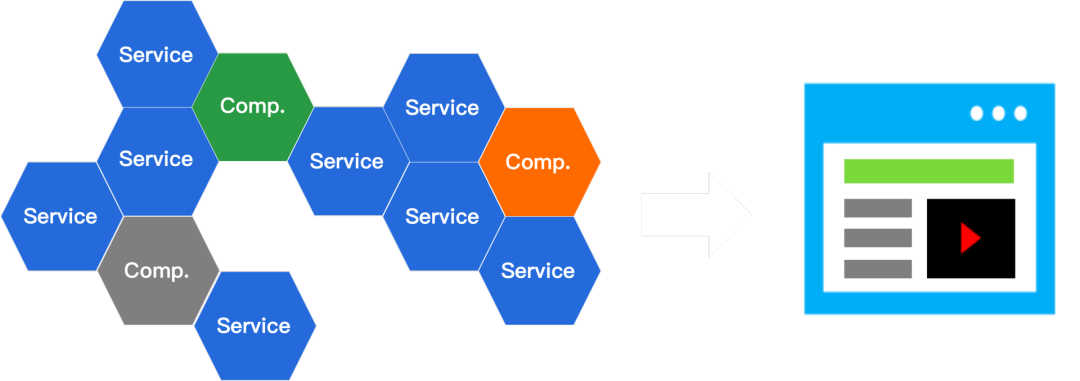 图 9:组件、Service 和容器之间的关系
图 9:组件、Service 和容器之间的关系
其中蓝色代表具体的Service,其他颜色表示独立的业务模块。运行时容器会负责解决每个业务模块的依赖,并把这些业务模块组装起来,最终得到可交互的 Web 页面。
注意:
业务模块之间是独立的,一个业务模块无法依赖于其他业务模块,只能依赖于通用 Service。因此如果存在业务模块之间的产品逻辑耦合,可能需要一个通用 Service 作为媒介,比如容器里提供一个起事件总线作用的 EventService。
图10是业务模块的客户端代码示例。它的依赖通过构造函数来声明,运行时容器负责依赖的创建,而业务模块只需要关心依赖的使用。正是使用和创建操作的分离,使得业务模块之间、业务模块和页面框架之间可以解耦,可以独立地开发、独立地测试。
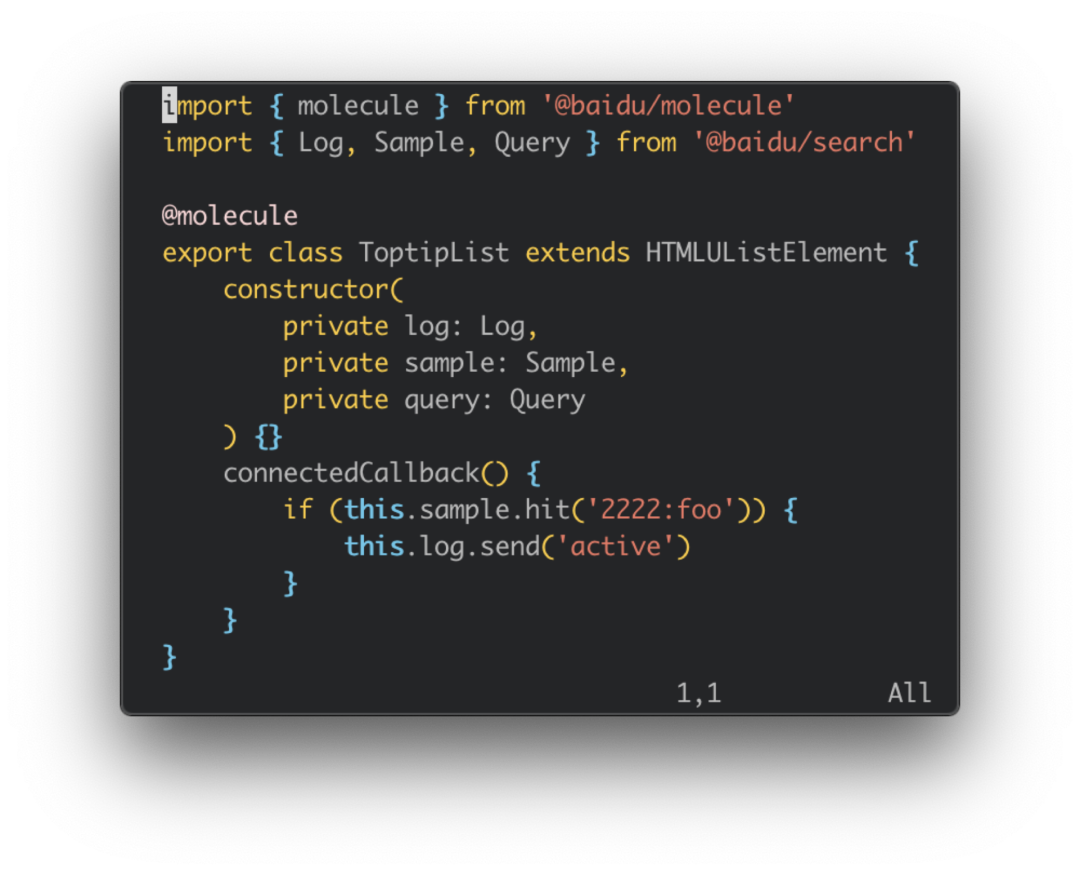
图 10:业务模块的客户端代码示例
以上是模块拆分的整体方案,我们回顾一下:在服务端通过一个叫做 Molecule 的接口来组合业务模块;在浏览器端通过一个 DI 容器来解决依赖关系,并启动所有业务模块。
4. 组件化
组件化方案直接影响业务开发的的效率,换句话说,组件化方案某种程度上决定了业务同学写怎样的代码。组件化也可以帮助解决职责不清晰等问题。我们选的组件化方案是 San,你也可以基于你的业务或偏好选则 Vue 或者 React。业务代码的迁移比较直观,就是从 Smarty 模板迁移到 San 组件,从 HTML 字符串拼接变成有业务语义的组件结构。
接下来重点关注组件化方案的两个关键技术问题,跨平台和页面性能。
一、跨平台
我们有非常多的业务代码,有上千个模板、几十万行代码,这些代码需要迁移到组件化方案上来,而且要确保后端从 PHP 迁移到 Node.js 的整个过程中,业务代码不需要重新开发。所以业务组件如何跨平台呢?关键在于抽象。
高层语言:我们业务代码需要使用一个足够高层的语言,这里我们用的是 TypeScript,可以翻译到多个平台;
依赖反转:我们的高层的业务的模块不应该依赖于具体的底层模块,而是它只依赖于接口,这样才有可能在不同的平台给它替换掉不同的底层的实现;
抽象接口:最后是 Molecule 这个接口的设计应该足够的简单;Molecule 接口不依赖底层实现,比如 PHP 的具体 API。
做到以上几点就可以完成平滑的过渡。这个过程中又分为三个阶段(图 11)。
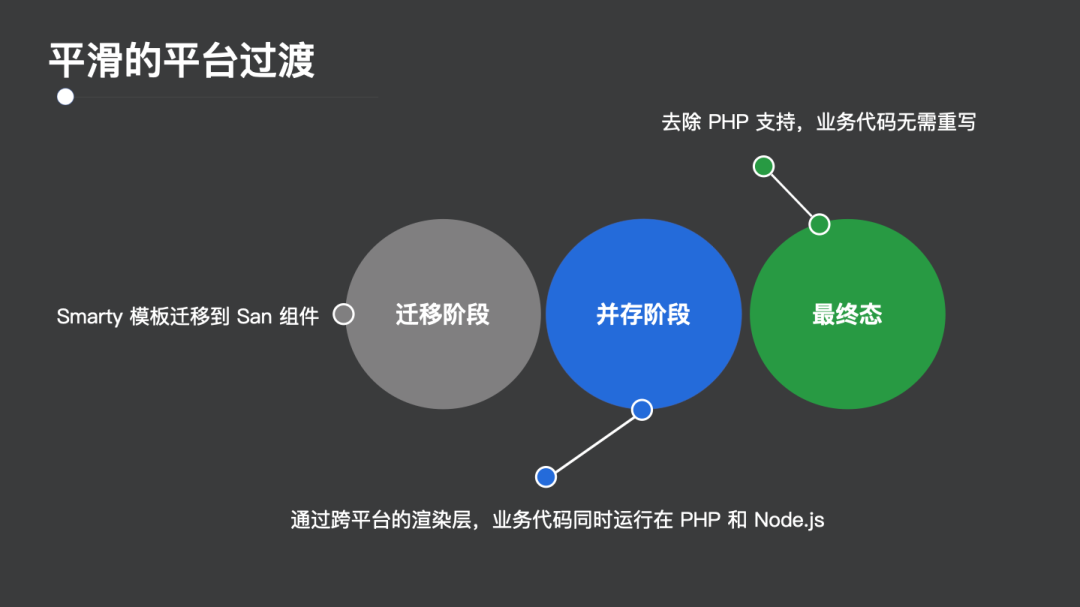 图 11:平台过渡的三个阶段
图 11:平台过渡的三个阶段
二、页面性能
引入前端框架通常意味着体积增加,性能下降,而性能直接影响搜索收入,因此页面性能是项目成功的关键。如果性能会比模板引擎的性能差,那么这个项目很可能会夭折。如何去保证页面性能?着重介绍两个优化点。
引入 SSR:引入服务端渲染,首屏性能可以得到明显提升;
SSR 优化:传统的 SSR 上还需要进一步优化性能。
引入SSR。为了解释SSR的重要性,请看图12。浏览器加载页面分为四步:请求页面、请求外链资源、执行脚本、渲染组件。从图中的对比可以看出,CSR在前面三步的时候,用户都是看不到页面的;而引入SSR之后,在第二步用户就能看到请求回来的页面。SSR它最大的一个用途就是提升首屏时间。
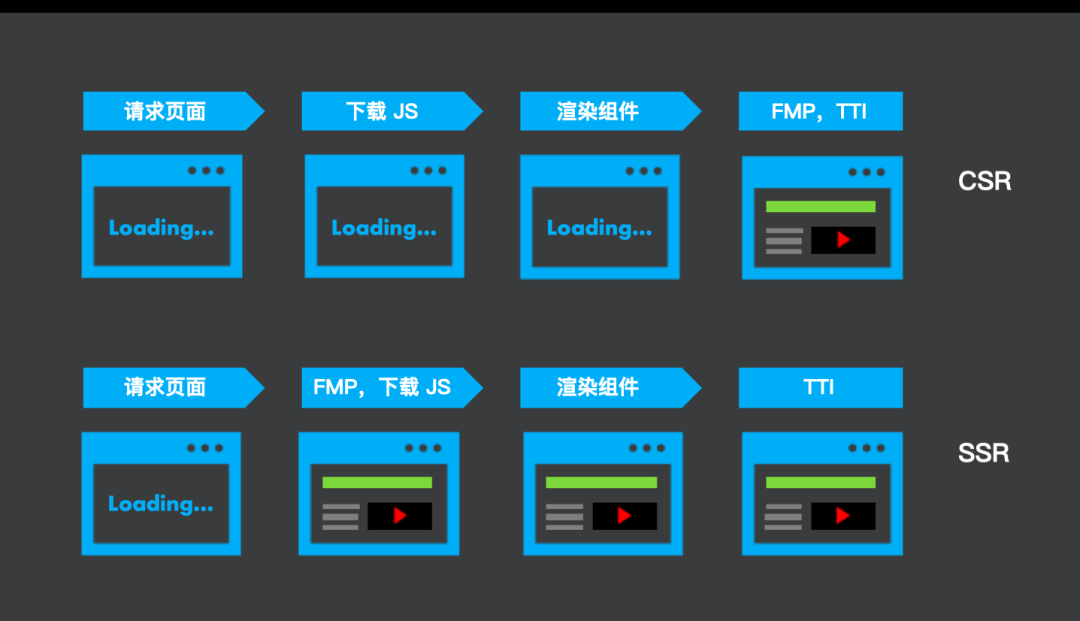 图 12:CSR和SSR的比较
图 12:CSR和SSR的比较
SSR 优化。只是引入 SSR 还不能让性能达到预期,因为相比于模板引擎直接拼接字符串,SSR 需要递归渲染组件,尤其是递归 VNode 比较耗时。对此 San SSR 相比于 Vue/React SSR 做了很多改进。
去 VNode:编译期递归 VNode,运行时只做 HTML 拼接;
编译期计算:尽可能把工作移到编译期,减小运行时开销;
图 13 展示了最终的 San SSR 和改造前的 Smarty 模板引擎的性能对比。
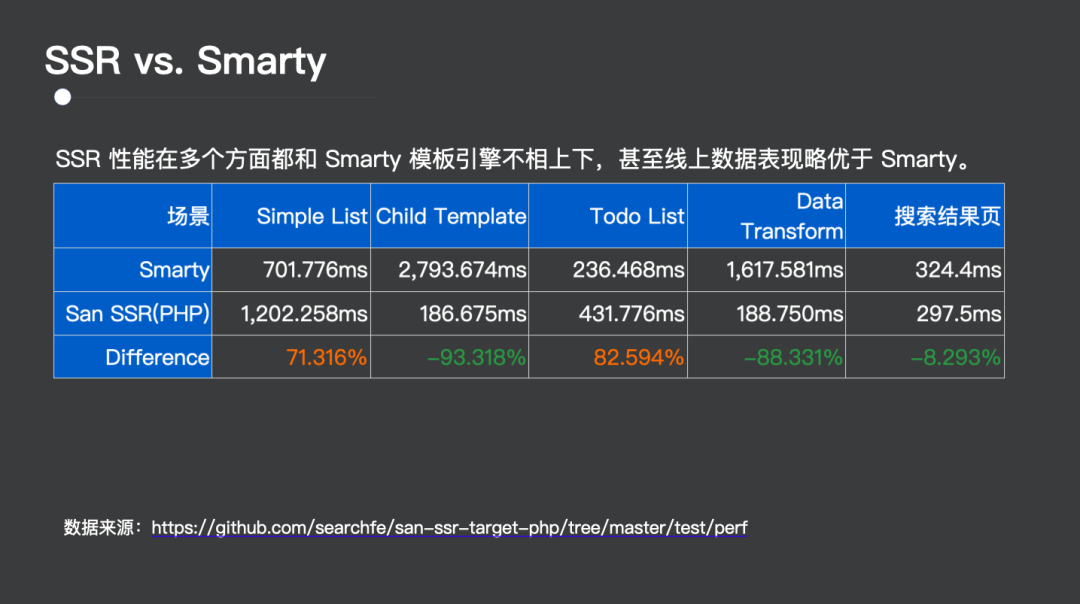 图 13:最终的 San SSR 和改造前的 Smarty 模板引擎的性能对比
图 13:最终的 San SSR 和改造前的 Smarty 模板引擎的性能对比
可以看到 Smarty 和 San SSR 在不同的场景会有不同的表现,因为它们的渲染方式非常不同。最终搜索结果页的组件化的 SSR 上线之后,线上实验效果显示比 Smarty 要快 10ms左右。这个已经是一个很不错的效果了,我们用组件化从性能上打败了模版引擎。
- 总结 -
针对百度搜索引擎在架构演化中遇到的问题,相信在其他领域也会有一些共性的东西。通过百度的解决思路,希望能对正在做前端架构的你有一些启发。
作者:Harttle
简介:百度资深研发工程师,北京大学物理学学士和计算机科学硕士。2016年加入百度,曾负责和参与百度搜索Web极速浏览框架、MIP开源项目的研发,目前负责搜索结果页和搜索推荐业务。LiquidJS 的作者,贡献于San、Realworld Apps、hightlight.js、ALE、HTML5 Standard等项目。
来源:百度架构师
