
亿级流量下的分布式锁架构解密!

作者个人研发的在高并发场景下,提供的简单、稳定、可扩展的延迟消息队列框架,具有精准的定时任务和延迟队列处理功能。自开源半年多以来,已成功为十几家中小型企业提供了精准定时调度方案,经受住了生产环境的考验。为使更多童鞋受益,现给出开源框架地址:
https://github.com/sunshinelyz/mykit-delay
PS: 欢迎各位Star源码,也可以pr你牛逼哄哄的代码。
写在前面
最近,很多小伙伴留言说,在学习高并发编程时,不太明白分布式锁是用来解决什么问题的,还有不少小伙伴甚至连分布式锁是什么都不太明白。明明在生产环境上使用了自己开发的分布式锁,为什么还会出现问题呢?同样的程序,加上分布式锁后,性能差了几个数量级!这又是为什么呢?今天,我们就来说说如何在高并发环境下实现分布式锁,不是所有的锁都是高并发的。
万字长文,带你深入解密高并发环境下的分布式锁架构,不是所有的锁都是分布式锁!!!
究竟什么样的锁才能更好的支持高并发场景呢?今天,我们就一起解密高并发环境下典型的分布式锁架构,结合【高并发】专题下的其他文章,学以致用。
锁用来解决什么问题呢?
在我们编写的应用程序或者高并发程序中,不知道大家有没有想过一个问题,就是我们为什么需要引入锁?锁为我们解决了什么问题呢?
在很多业务场景下,我们编写的应用程序中会存在很多的 资源竞争 的问题。而我们在高并发程序中,引入锁,就是为了解决这些资源竞争的问题。
电商超卖问题
这里,我们可以列举一个简单的业务场景。比如,在电子商务(商城)的业务场景中,提交订单购买商品时,首先需要查询相应商品的库存是否足够,只有在商品库存数量足够的前提下,才能让用户成功的下单。下单时,我们需要在库存数量中减去用户下单的商品数量,并将库存操作的结果数据更新到数据库中。整个流程我们可以简化成下图所示。
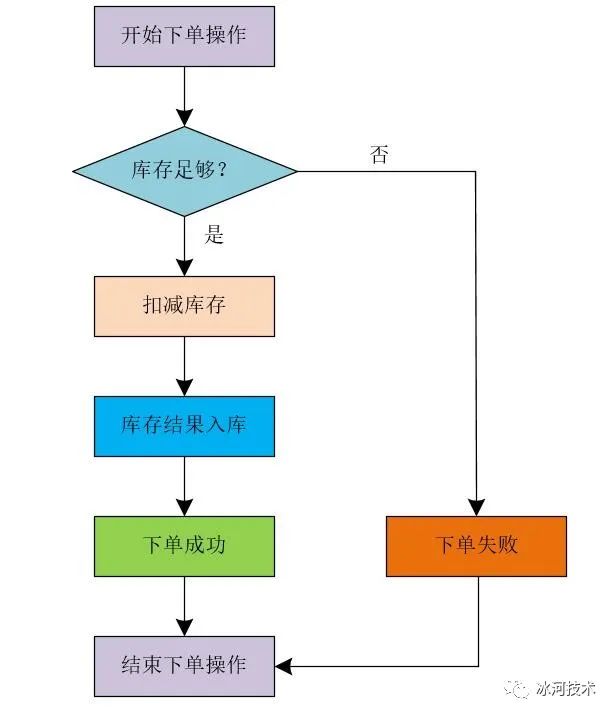
很多小伙伴也留言说,让我给出代码,这样能够更好的学习和掌握相关的知识。好吧,这里,我也给出相应的代码片段吧。我们可以使用下面的代码片段来表示用户的下单操作,我这里将商品的库存信息保存在了Redis中。
@RequestMapping("/submitOrder")
public String submitOrder(){
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
stock -= 1;
stringRedisTemplate.opsForValue().set("stock", String.valueOf(stock));
logger.debug("库存扣减成功,当前库存为:{}", stock);
}else{
logger.debug("库存不足,扣减库存失败");
throw new OrderException("库存不足,扣减库存失败");
}
return "success";
}
注意:上述代码片段比较简单,只是为了方便大家理解,真正项目中的代码就不能这么写了。
上述的代码看似是没啥问题的,但是我们不能只从代码表面上来观察代码的执行顺序。这是因为在JVM中代码的执行顺序未必是按照我们书写代码的顺序执行的。即使在JVM中代码是按照我们书写的顺序执行,那我们对外提供的接口一旦暴露出去,就会有成千上万的客户端来访问我们的接口。所以说,我们暴露出去的接口是会被并发访问的。
试问,上面的代码在高并发环境下是线程安全的吗?答案肯定不是线程安全的,因为上述扣减库存的操作会出现并行执行的情况。
我们可以使用Apache JMeter来对上述接口进行测试,这里,我使用Apache JMeter对上述接口进行测试。
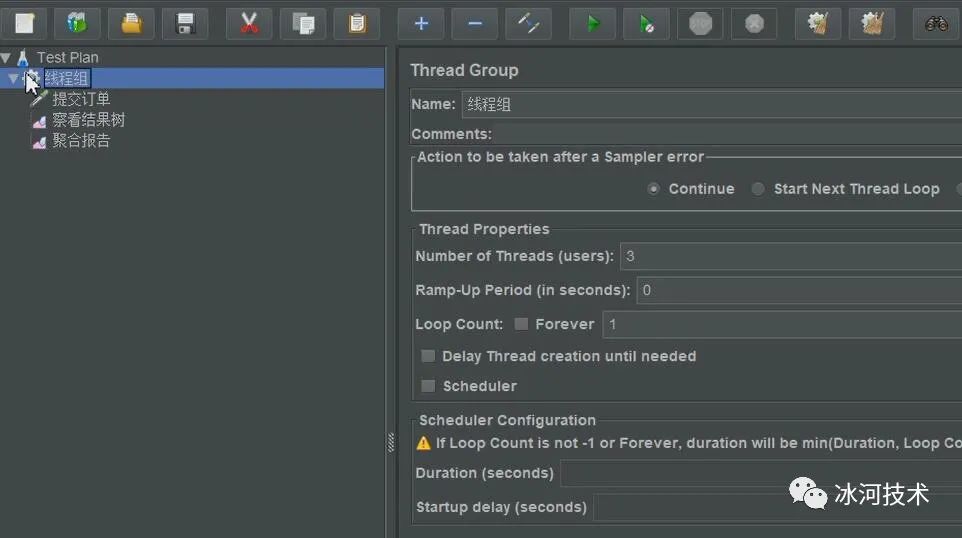
在Jmeter中,我将线程的并发度设置为3,接下来的配置如下所示。
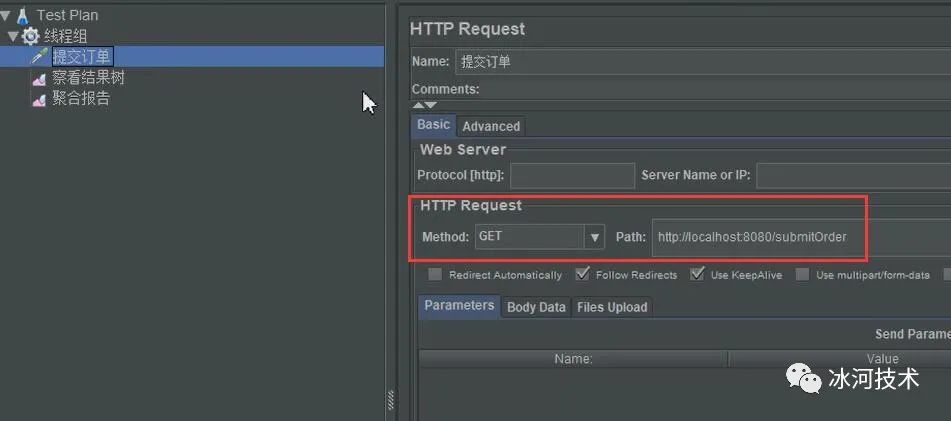
以HTTP GET请求的方式来并发访问提交订单的接口。此时,运行JMeter来访问接口,命令行会打印出下面的日志信息。
库存扣减成功,当前库存为:49
库存扣减成功,当前库存为:49
库存扣减成功,当前库存为:49
这里,我们明明请求了3次,也就是说,提交了3笔订单,为什么扣减后的库存都是一样的呢?这种现象在电商领域有一个专业的名词叫做 “超卖” 。
如果一个大型的高并发电商系统,比如淘宝、天猫、京东等,出现了超卖现象,那损失就无法估量了!架构设计和开发电商系统的人员估计就要通通下岗了。所以,作为技术人员,我们一定要严谨的对待技术,严格做好系统的每一个技术环节。
JVM中提供的锁
JVM中提供的synchronized和Lock锁,相信大家并不陌生了,很多小伙伴都会使用这些锁,也能使用这些锁来实现一些简单的线程互斥功能。那么,作为立志要成为架构师的你,是否了解过JVM锁的底层原理呢?
JVM锁原理
说到JVM锁的原理,我们就不得不限说说Java中的对象头了。
Java中的对象头
每个Java对象都有对象头。如果是⾮数组类型,则⽤2个字宽来存储对象头,如果是数组,则会⽤3个字宽来存储对象头。在32位处理器中,⼀个字宽是32位;在64位虚拟机中,⼀个字宽是64位。
对象头的内容如下表 。
| 长度 | 内容 | 说明 |
|---|---|---|
| 32/64bit | Mark Word | 存储对象的hashCode或锁信息等 |
| 32/64bit | Class Metadata Access | 存储到对象类型数据的指针 |
| 32/64bit | Array length | 数组的长度(如果是数组) |
Mark Work的格式如下所示。
| 锁状态 | 29bit或61bit | 1bit是否是偏向锁? | 2bit锁标志位 |
|---|---|---|---|
| 无锁 | 0 | 01 | |
| 偏向锁 | 线程ID | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 此时这一位不用于标识偏向锁 | 00 |
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 此时这一位不用于标识偏向锁 | 10 |
| GC标记 | 此时这一位不用于标识偏向锁 | 11 |
可以看到,当对象状态为偏向锁时, Mark Word 存储的是偏向的线程ID;当状态为轻量级锁时, Mark Word 存储的是指向线程栈中 Lock Record 的指针;当状态为重量级锁时, Mark Word 为指向堆中的monitor对象的指针 。
有关Java对象头的知识,参考《深入浅出Java多线程》。
JVM锁原理
简单点来说,JVM中锁的原理如下。
在Java对象的对象头上,有一个锁的标记,比如,第一个线程执行程序时,检查Java对象头中的锁标记,发现Java对象头中的锁标记为未加锁状态,于是为Java对象进行了加锁操作,将对象头中的锁标记设置为锁定状态。第二个线程执行同样的程序时,也会检查Java对象头中的锁标记,此时会发现Java对象头中的锁标记的状态为锁定状态。于是,第二个线程会进入相应的阻塞队列中进行等待。
这里有一个关键点就是Java对象头中的锁标记如何实现。
JVM锁的短板
JVM中提供的synchronized和Lock锁都是JVM级别的,大家都知道,当运行一个Java程序时,会启动一个JVM进程来运行我们的应用程序。synchronized和Lock在JVM级别有效,也就是说,synchronized和Lock在同一Java进程内有效。如果我们开发的应用程序是分布式的,那么只是使用synchronized和Lock来解决分布式场景下的高并发问题,就会显得有点力不从心了。
synchronized和Lock支持JVM同一进程内部的线程互斥
synchronized和Lock在JVM级别能够保证高并发程序的互斥,我们可以使用下图来表示。
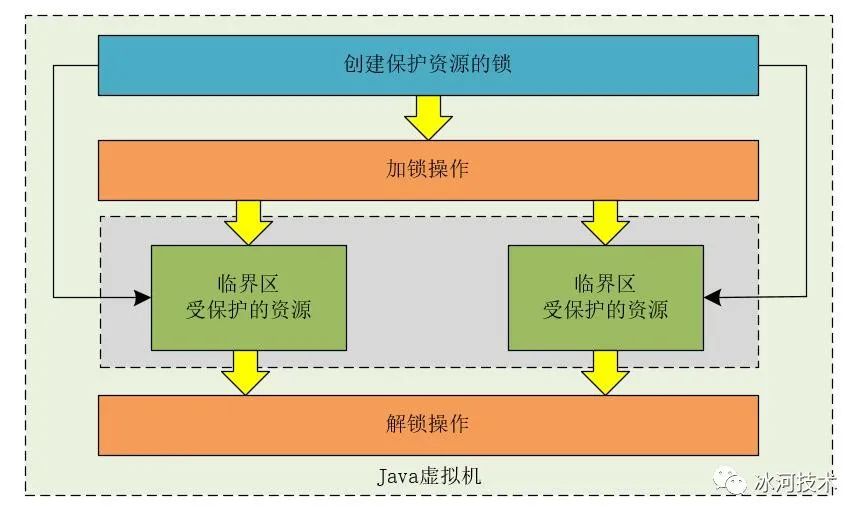
但是,当我们将应用程序部署成分布式架构,或者将应用程序在不同的JVM进程中运行时,synchronized和Lock就不能保证分布式架构和多JVM进程下应用程序的互斥性了。
synchronized和Lock不能实现多JVM进程之间的线程互斥
分布式架构和多JVM进程的本质都是将应用程序部署在不同的JVM实例中,也就是说,其本质还是多JVM进程。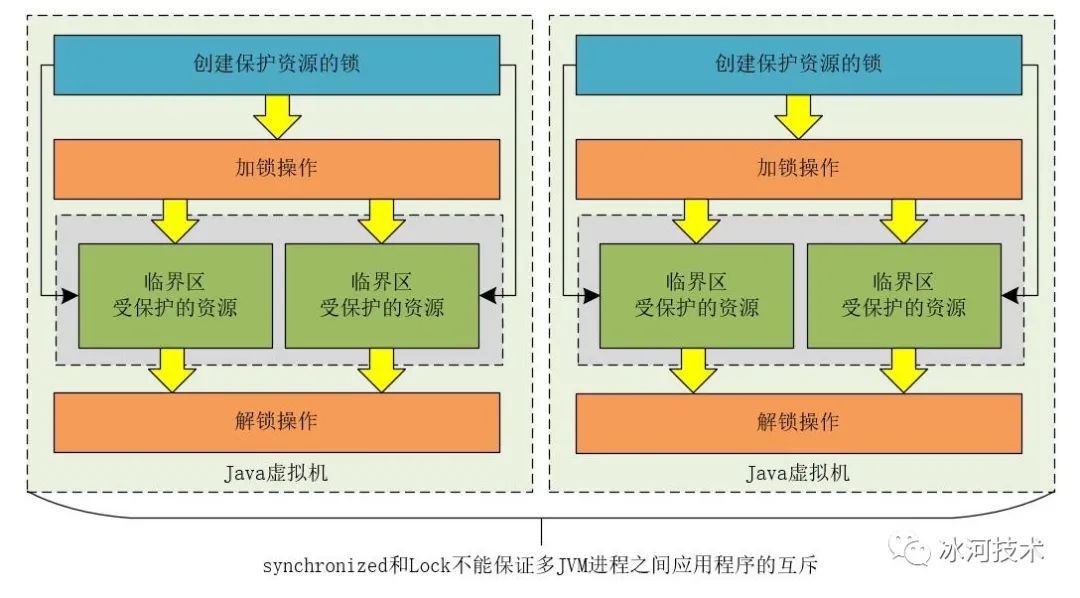
分布式锁
我们在实现分布式锁时,可以参照JVM锁实现的思想,JVM锁在为对象加锁时,通过改变Java对象的对象头中的锁的标志位来实现,也就是说,所有的线程都会访问这个Java对象的对象头中的锁标志位。
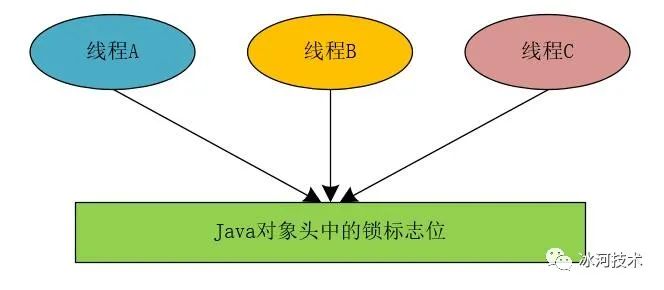
我们同样以这种思想来实现分布式锁,当我们将应用程序进行拆分并部署成分布式架构时,所有应用程序中的线程访问共享变量时,都到同一个地方去检查当前程序的临界区是否进行了加锁操作,而是否进行了加锁操作,我们在统一的地方使用相应的状态来进行标记。
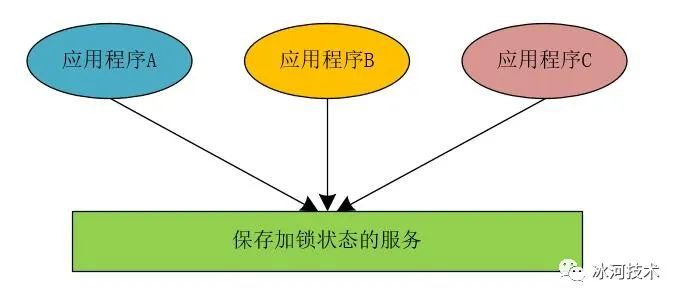
可以看到,在分布式锁的实现思想上,与JVM锁相差不大。而在实现分布式锁中,保存加锁状态的服务可以使用MySQL、Redis和Zookeeper实现。
但是,在互联网高并发环境中, 使用Redis实现分布式锁的方案是使用的最多的。 接下来,我们就使用Redis来深入解密分布式锁的架构设计。
Redis如何实现分布式锁
Redis命令
在Redis中,有一个不常使用的命令如下所示。
SETNX key value
这条命令的含义就是“SET if Not Exists”,即不存在的时候才会设置值。
只有在key不存在的情况下,将键key的值设置为value。如果key已经存在,则SETNX命令不做任何操作。
这个命令的返回值如下。
命令在设置成功时返回1。 命令在设置失败时返回0。
所以,我们在分布式高并发环境下,可以使用Redis的SETNX命令来实现分布式锁。假设此时有线程A和线程B同时访问临界区代码,假设线程A首先执行了SETNX命令,并返回结果1,继续向下执行。而此时线程B再次执行SETNX命令时,返回的结果为0,则线程B不能继续向下执行。只有当线程A执行DELETE命令将设置的锁状态删除时,线程B才会成功执行SETNX命令设置加锁状态后继续向下执行。
引入分布式锁
了解了如何使用Redis中的命令实现分布式锁后,我们就可以对下单接口进行改造了,加入分布式锁,如下所示。
/**
* 为了演示方便,我这里就简单定义了一个常量作为商品的id
* 实际工作中,这个商品id是前端进行下单操作传递过来的参数
*/
public static final String PRODUCT_ID = "100001";
@RequestMapping("/submitOrder")
public String submitOrder(){
//通过stringRedisTemplate来调用Redis的SETNX命令,key为商品的id,value为字符串“binghe”
//实际上,value可以为任意的字符换
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe");
//没有拿到锁,返回下单失败
if(!isLock){
return "failure";
}
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
stock -= 1;
stringRedisTemplate.opsForValue().set("stock", String.valueOf(stock));
logger.debug("库存扣减成功,当前库存为:{}", stock);
}else{
logger.debug("库存不足,扣减库存失败");
throw new OrderException("库存不足,扣减库存失败");
}
//业务执行完成,删除PRODUCT_ID key
stringRedisTemplate.delete(PRODUCT_ID);
return "success";
}
那么,在上述代码中,我们加入了分布式锁的操作,那上述代码是否能够在高并发场景下保证业务的原子性呢?答案是可以保证业务的原子性。但是,在实际场景中,上面实现分布式锁的代码是不可用的!!
假设当线程A首先执行stringRedisTemplate.opsForValue()的setIfAbsent()方法返回true,继续向下执行,正在执行业务代码时,抛出了异常,线程A直接退出了JVM。此时,stringRedisTemplate.delete(PRODUCT_ID);代码还没来得及执行,之后所有的线程进入提交订单的方法时,调用stringRedisTemplate.opsForValue()的setIfAbsent()方法都会返回false。导致后续的所有下单操作都会失败。这就是分布式场景下的死锁问题。
所以,上述代码中实现分布式锁的方式在实际场景下是不可取的!!
引入try-finally代码块
说到这,相信小伙伴们都能够想到,使用try-finall代码块啊,接下来,我们为下单接口的方法加上try-finally代码块。
/**
* 为了演示方便,我这里就简单定义了一个常量作为商品的id
* 实际工作中,这个商品id是前端进行下单操作传递过来的参数
*/
public static final String PRODUCT_ID = "100001";
@RequestMapping("/submitOrder")
public String submitOrder(){
//通过stringRedisTemplate来调用Redis的SETNX命令,key为商品的id,value为字符串“binghe”
//实际上,value可以为任意的字符换
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe");
//没有拿到锁,返回下单失败
if(!isLock){
return "failure";
}
try{
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
stock -= 1;
stringRedisTemplate.opsForValue().set("stock", String.valueOf(stock));
logger.debug("库存扣减成功,当前库存为:{}", stock);
}else{
logger.debug("库存不足,扣减库存失败");
throw new OrderException("库存不足,扣减库存失败");
}
}finally{
//业务执行完成,删除PRODUCT_ID key
stringRedisTemplate.delete(PRODUCT_ID);
}
return "success";
}
那么,上述代码是否真正解决了死锁的问题呢?我们在写代码时,不能只盯着代码本身,觉得上述代码没啥问题了。实际上,生产环境是非常复杂的。如果线程在成功加锁之后,执行业务代码时,还没来得及执行删除锁标志的代码,此时,服务器宕机了,程序并没有优雅的退出JVM。也会使得后续的线程进入提交订单的方法时,因无法成功的设置锁标志位而下单失败。所以说,上述的代码仍然存在问题。
引入Redis超时机制
在Redis中可以设置缓存的自动过期时间,我们可以将其引入到分布式锁的实现中,如下代码所示。
/**
* 为了演示方便,我这里就简单定义了一个常量作为商品的id
* 实际工作中,这个商品id是前端进行下单操作传递过来的参数
*/
public static final String PRODUCT_ID = "100001";
@RequestMapping("/submitOrder")
public String submitOrder(){
//通过stringRedisTemplate来调用Redis的SETNX命令,key为商品的id,value为字符串“binghe”
//实际上,value可以为任意的字符换
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe");
//没有拿到锁,返回下单失败
if(!isLock){
return "failure";
}
try{
stringRedisTemplate.expire(PRODUCT_ID, 30, TimeUnit.SECONDS);
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
stock -= 1;
stringRedisTemplate.opsForValue().set("stock", String.valueOf(stock));
logger.debug("库存扣减成功,当前库存为:{}", stock);
}else{
logger.debug("库存不足,扣减库存失败");
throw new OrderException("库存不足,扣减库存失败");
}
}finally{
//业务执行完成,删除PRODUCT_ID key
stringRedisTemplate.delete(PRODUCT_ID);
}
return "success";
}
在上述代码中,我们加入了如下一行代码来为Redis中的锁标志设置过期时间。
stringRedisTemplate.expire(PRODUCT_ID, 30, TimeUnit.SECONDS);
此时,我们设置的过期时间为30秒。
那么问题来了,这样是否就真正的解决了问题呢?上述程序就真的没有坑了吗?答案是还是有坑的!!
“坑位”分析
我们在下单操作的方法中为分布式锁引入了超时机制,此时的代码还是无法真正避免死锁的问题,那“坑位”到底在哪里呢?试想,当程序执行完stringRedisTemplate.opsForValue().setIfAbsent()方法后,正要执行stringRedisTemplate.expire(PRODUCT_ID, 30, TimeUnit.SECONDS)代码时,服务器宕机了,你还别说,生产坏境的情况非常复杂,就是这么巧,服务器就宕机了。此时,后续请求进入提交订单的方法时,都会因为无法成功设置锁标志而导致后续下单流程无法正常执行。
既然我们找到了上述代码的“坑位”,那我们如何将这个”坑“填上?如何解决这个问题呢?别急,Redis已经提供了这样的功能。我们可以在向Redis中保存数据的时候,可以同时指定数据的超时时间。所以,我们可以将代码改造成如下所示。
/**
* 为了演示方便,我这里就简单定义了一个常量作为商品的id
* 实际工作中,这个商品id是前端进行下单操作传递过来的参数
*/
public static final String PRODUCT_ID = "100001";
@RequestMapping("/submitOrder")
public String submitOrder(){
//通过stringRedisTemplate来调用Redis的SETNX命令,key为商品的id,value为字符串“binghe”
//实际上,value可以为任意的字符换
Boolean isLocked = stringRedisTemplate.opsForValue().setIfAbsent(PRODUCT_ID, "binghe", 30, TimeUnit.SECONDS);
//没有拿到锁,返回下单失败
if(!isLock){
return "failure";
}
try{
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock > 0){
stock -= 1;
stringRedisTemplate.opsForValue().set("stock", String.valueOf(stock));
logger.debug("库存扣减成功,当前库存为:{}", stock);
}else{
logger.debug("库存不足,扣减库存失败");
throw new OrderException("库存不足,扣减库存失败");
}
}finally{
//业务执行完成,删除PRODUCT_ID key
stringRedisTemplate.delete(PRODUCT_ID);
}
return "success";
}
在上述代码中,我们在向Redis中设置锁标志位的时候就设置了超时时间。此时,只要向Redis中成功设置了数据,则即使我们的业务系统宕机,Redis中的数据过期后,也会自动删除。后续的线程进入提交订单的方法后,就会成功的设置锁标志位,并向下执行正常的下单流程。
到此,上述的代码基本上在功能角度解决了程序的死锁问题,那么,上述程序真的就完美了吗?哈哈,很多小伙伴肯定会说不完美!确实,上面的代码还不是完美的,那大家知道哪里不完美吗?接下来,我们继续分析。
在开发集成角度分析代码
在我们开发公共的系统组件时,比如我们这里说的分布式锁,我们肯定会抽取一些公共的类来完成相应的功能来供系统使用。
这里,假设我们定义了一个RedisLock接口,如下所示。
public interface RedisLock{
//加锁操作
boolean tryLock(String key, long timeout, TimeUnit unit);
//解锁操作
void releaseLock(String key);
}
接下来,使用RedisLockImpl类实现RedisLock接口,提供具体的加锁和解锁实现,如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
return stringRedisTemplate.opsForValue().setIfAbsent(key, "binghe", timeout, unit);
}
@Override
public void releaseLock(String key){
stringRedisTemplate.delete(key);
}
}
在开发集成的角度来说,当一个线程从上到下执行时,首先对程序进行加锁操作,然后执行业务代码,执行完成后,再进行释放锁的操作。理论上,加锁和释放锁时,操作的Redis Key都是一样的。但是,如果其他开发人员在编写代码时,并没有调用tryLock()方法,而是直接调用了releaseLock()方法,并且他调用releaseLock()方法传递的key与你调用tryLock()方法传递的key是一样的。那此时就会出现问题了,他在编写代码时,硬生生的将你加的锁释放了!!!
所以,上述代码是不安全的,别人能够随随便便的将你加的锁删除,这就是锁的误删操作,这是非常危险的,所以,上述的程序存在很严重的问题!!
那如何实现只有加锁的线程才能进行相应的解锁操作呢? 继续向下看。
如何实现加锁和解锁的归一化?
什么是加锁和解锁的归一化呢?简单点来说,就是一个线程执行了加锁操作后,后续必须由这个线程执行解锁操作,加锁和解锁操作由同一个线程来完成。
为了解决只有加锁的线程才能进行相应的解锁操作的问题,那么,我们就需要将加锁和解锁操作绑定到同一个线程中,那么,如何将加锁操作和解锁操作绑定到同一个线程呢?其实很简单,相信很多小伙伴都想到了—— 使用ThreadLocal实现 。没错,使用ThreadLocal类确实能够解决这个问题。
此时,我们将RedisLockImpl类的代码修改成如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
return stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
stringRedisTemplate.delete(key);
}
}
}
上述代码的主要逻辑为:在对程序执行尝试加锁操作时,首先生成一个uuid,将生成的uuid绑定到当前线程,并将传递的key参数操作Redis中的key,生成的uuid作为Redis中的Value,保存到Redis中,同时设置超时时间。当执行解锁操作时,首先,判断当前线程中绑定的uuid是否和Redis中存储的uuid相等,只有二者相等时,才会执行删除锁标志位的操作。这就避免了一个线程对程序进行了加锁操作后,其他线程对这个锁进行了解锁操作的问题。
继续分析
我们将加锁和解锁的方法改成如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
private String lockUUID;
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
lockUUID = uuid;
return stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(lockUUID.equals(stringRedisTemplate.opsForValue().get(key))){
stringRedisTemplate.delete(key);
}
}
}
相信很多小伙伴都会看出上述代码存在什么问题了!!没错,那就是 线程安全的问题。
所以,这里,我们需要使用ThreadLocal来解决线程安全问题。
可重入性分析
在上面的代码中,当一个线程成功设置了锁标志位后,其他的线程再设置锁标志位时,就会返回失败。还有一种场景就是在提交订单的接口方法中,调用了服务A,服务A调用了服务B,而服务B的方法中存在对同一个商品的加锁和解锁操作。
所以,服务B成功设置锁标志位后,提交订单的接口方法继续执行时,也不能成功设置锁标志位了。也就是说,目前实现的分布式锁没有可重入性。
这里,就存在可重入性的问题了。我们希望设计的分布式锁 具有可重入性 ,那什么是可重入性呢?简单点来说,就是同一个线程,能够多次获取同一把锁,并且能够按照顺序进行解决操作。
其实,在JDK 1.5之后提供的锁很多都支持可重入性,比如synchronized和Lock。
如何实现可重入性呢?
映射到我们加锁和解锁方法时,我们如何支持同一个线程能够多次获取到锁(设置锁标志位)呢?可以这样简单的设计:如果当前线程没有绑定uuid,则生成uuid绑定到当前线程,并且在Redis中设置锁标志位。如果当前线程已经绑定了uuid,则直接返回true,证明当前线程之前已经设置了锁标志位,也就是说已经获取到了锁,直接返回true。
结合以上分析,我们将提交订单的接口方法代码改造成如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
Boolean isLocked = false;
if(threadLocal.get() == null){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
}else{
isLocked = true;
}
return isLocked;
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
stringRedisTemplate.delete(key);
}
}
}
这样写看似没有啥问题,但是大家细想一下,这样写就真的OK了吗?
可重入性的问题分析
既然上面分布式锁的可重入性是存在问题的,那我们就来分析下问题的根源在哪里!
假设我们提交订单的方法中,首先使用RedisLock接口对代码块添加了分布式锁,在加锁后的代码中调用了服务A,而服务A中也存在调用RedisLock接口的加锁和解锁操作。而多次调用RedisLock接口的加锁操作时,只要之前的锁没有失效,则会直接返回true,表示成功获取锁。也就是说,无论调用加锁操作多少次,最终只会成功加锁一次。而执行完服务A中的逻辑后,在服务A中调用RedisLock接口的解锁方法,此时,会将当前线程所有的加锁操作获得的锁全部释放掉。
我们可以使用下图来简单的表示这个过程。
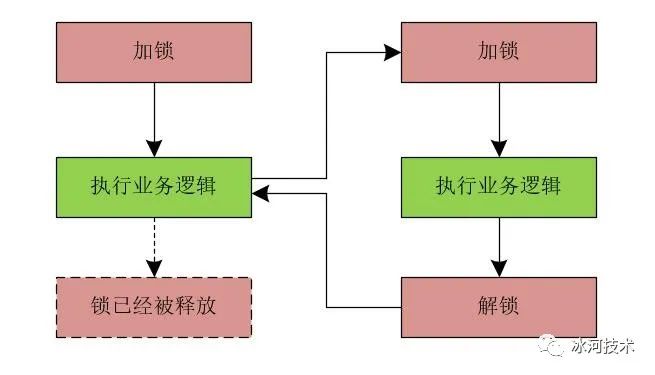
那么问题来了,如何解决可重入性的问题呢?
解决可重入性问题
相信很多小伙伴都能够想出使用计数器的方式来解决上面可重入性的问题,没错,就是使用计数器来解决。 整体流程如下所示。
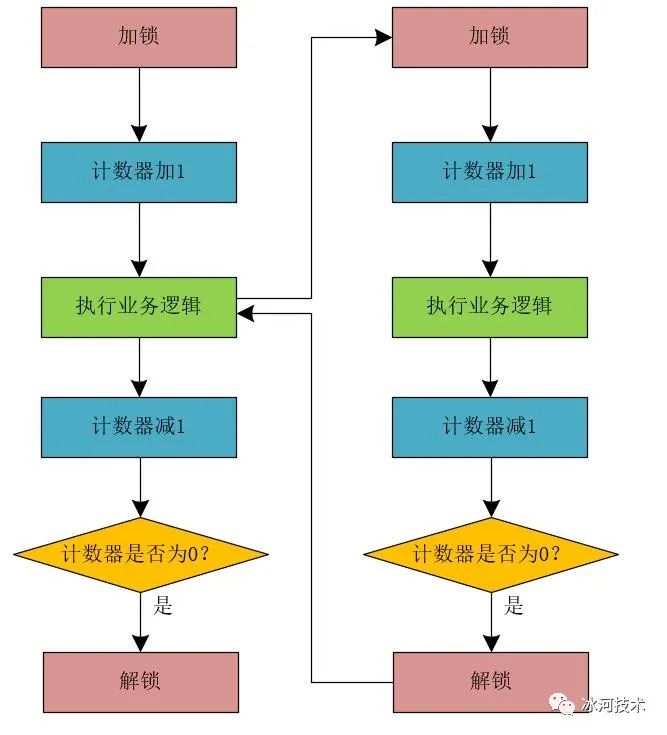
那么,体现在程序代码上是什么样子呢?我们来修改RedisLockImpl类的代码,如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<Integer>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
Boolean isLocked = false;
if(threadLocal.get() == null){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
}else{
isLocked = true;
}
//加锁成功后将计数器加1
if(isLocked){
Integer count = threadLocalInteger.get() == null ? 0 : threadLocalInteger.get();
threadLocalInteger.set(count++);
}
return isLocked;
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
Integer count = threadLocalInteger.get();
//计数器减为0时释放锁
if(count == null || --count <= 0){
stringRedisTemplate.delete(key);
}
}
}
}
至此,我们基本上解决了分布式锁的可重入性问题。
说到这里,我还要问大家一句,上面的解决问题的方案真的没问题了吗?
阻塞与非阻塞锁
在提交订单的方法中,当获取Redis分布式锁失败时,我们直接返回了failure来表示当前请求下单的操作失败了。试想,在高并发环境下,一旦某个请求获得了分布式锁,那么,在这个请求释放锁之前,其他的请求调用下单方法时,都会返回下单失败的信息。在真实场景中,这是非常不友好的。我们可以将后续的请求进行阻塞,直到当前请求释放锁后,再唤醒阻塞的请求获得分布式锁来执行方法。
所以,我们设计的分布式锁需要支持 阻塞和非阻塞 的特性。
那么,如何实现阻塞呢?我们可以使用自旋来实现,继续修改RedisLockImpl的代码如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<Integer>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
Boolean isLocked = false;
if(threadLocal.get() == null){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
//如果获取锁失败,则自旋获取锁,直到成功
if(!isLocked){
for(;;){
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
if(isLocked){
break;
}
}
}
}else{
isLocked = true;
}
//加锁成功后将计数器加1
if(isLocked){
Integer count = threadLocalInteger.get() == null ? 0 : threadLocalInteger.get();
threadLocalInteger.set(count++);
}
return isLocked;
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
Integer count = threadLocalInteger.get();
//计数器减为0时释放锁
if(count == null || --count <= 0){
stringRedisTemplate.delete(key);
}
}
}
}
在分布式锁的设计中,阻塞锁和非阻塞锁 是非常重要的概念,大家一定要记住这个知识点。
锁失效问题
尽管我们实现了分布式锁的阻塞特性,但是还有一个问题是我们不得不考虑的。那就是 锁失效 的问题。
当程序执行业务的时间超过了锁的过期时间会发生什么呢? 想必很多小伙伴都能够想到,那就是前面的请求没执行完,锁过期失效了,后面的请求获取到分布式锁,继续向下执行了,程序无法做到真正的互斥,无法保证业务的原子性了。
那如何解决这个问题呢?答案就是:我们必须保证在业务代码执行完毕后,才能释放分布式锁。 方案是有了,那如何实现呢?
说白了,我们需要在业务代码中,时不时的执行下面的代码来保证在业务代码没执行完时,分布式锁不会因超时而被释放。
springRedisTemplate.expire(PRODUCT_ID, 30, TimeUnit.SECONDS);
这里,我们需要定义一个定时策略来执行上面的代码,需要注意的是:我们不能等到30秒后再执行上述代码,因为30秒时,锁已经失效了。例如,我们可以每10秒执行一次上面的代码。
有些小伙伴说,直接在RedisLockImpl类中添加一个while(true)循环来解决这个问题,那我们就这样修改下RedisLockImpl类的代码,看看有没有啥问题。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<Integer>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
Boolean isLocked = false;
if(threadLocal.get() == null){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
//如果获取锁失败,则自旋获取锁,直到成功
if(!isLocked){
for(;;){
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
if(isLocked){
break;
}
}
}
//定义更新锁的过期时间
while(true){
Integer count = threadLocalInteger.get();
//当前锁已经被释放,则退出循环
if(count == 0 || count <= 0){
break;
}
springRedisTemplate.expire(key, 30, TimeUnit.SECONDS);
try{
//每隔10秒执行一次
Thread.sleep(10000);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}else{
isLocked = true;
}
//加锁成功后将计数器加1
if(isLocked){
Integer count = threadLocalInteger.get() == null ? 0 : threadLocalInteger.get();
threadLocalInteger.set(count++);
}
return isLocked;
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
if(threadLocal.get().equals(stringRedisTemplate.opsForValue().get(key))){
Integer count = threadLocalInteger.get();
//计数器减为0时释放锁
if(count == null || --count <= 0){
stringRedisTemplate.delete(key);
}
}
}
}
相信小伙伴们看了代码就会发现哪里有问题了:更新锁过期时间的代码肯定不能这么去写。因为这么写会 导致当前线程在更新锁超时时间的while(true)循环中一直阻塞而无法返回结果。 所以,我们不能将当前线程阻塞,需要异步执行定时任务来更新锁的过期时间。
此时,我们继续修改RedisLockImpl类的代码,将定时更新锁超时的代码放到一个单独的线程中执行,如下所示。
public class RedisLockImpl implements RedisLock{
@Autowired
private StringRedisTemplate stringRedisTemplate;
private ThreadLocal<String> threadLocal = new ThreadLocal<String>();
private ThreadLocal<Integer> threadLocalInteger = new ThreadLocal<Integer>();
@Override
public boolean tryLock(String key, long timeout, TimeUnit unit){
Boolean isLocked = false;
if(threadLocal.get() == null){
String uuid = UUID.randomUUID().toString();
threadLocal.set(uuid);
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
//如果获取锁失败,则自旋获取锁,直到成功
if(!isLocked){
for(;;){
isLocked = stringRedisTemplate.opsForValue().setIfAbsent(key, uuid, timeout, unit);
if(isLocked){
break;
}
}
}
//启动新线程来执行定时任务,更新锁过期时间
new Thread(new UpdateLockTimeoutTask(uuid, stringRedisTemplate, key)).start();
}else{
isLocked = true;
}
//加锁成功后将计数器加1
if(isLocked){
Integer count = threadLocalInteger.get() == null ? 0 : threadLocalInteger.get();
threadLocalInteger.set(count++);
}
return isLocked;
}
@Override
public void releaseLock(String key){
//当前线程中绑定的uuid与Redis中的uuid相同时,再执行删除锁的操作
String uuid = stringRedisTemplate.opsForValue().get(key);
if(threadLocal.get().equals(uuid)){
Integer count = threadLocalInteger.get();
//计数器减为0时释放锁
if(count == null || --count <= 0){
stringRedisTemplate.delete(key);
//获取更新锁超时时间的线程并中断
long threadId = stringRedisTemplate.opsForValue().get(uuid);
Thread updateLockTimeoutThread = ThreadUtils.getThreadByThreadId(threadId);
if(updateLockTimeoutThread != null){
//中断更新锁超时时间的线程
updateLockTimeoutThread.interrupt();
stringRedisTemplate.delete(uuid);
}
}
}
}
}
创建UpdateLockTimeoutTask类来执行更新锁超时的时间。
public class UpdateLockTimeoutTask implements Runnable{
//uuid
private long uuid;
private StringRedisTemplate stringRedisTemplate;
private String key;
public UpdateLockTimeoutTask(long uuid, StringRedisTemplate stringRedisTemplate, String key){
this.uuid = uuid;
this.stringRedisTemplate = stringRedisTemplate;
this.key = key;
}
@Override
public void run(){
//以uuid为key,当前线程id为value保存到Redis中
stringRedisTemplate.opsForValue().set(uuid, Thread.currentThread().getId());
//定义更新锁的过期时间
while(true){
springRedisTemplate.expire(key, 30, TimeUnit.SECONDS);
try{
//每隔10秒执行一次
Thread.sleep(10000);
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
}
接下来,我们定义一个ThreadUtils工具类,这个工具类中有一个根据线程id获取线程的方法getThreadByThreadId(long threadId)。
public class ThreadUtils{
//根据线程id获取线程句柄
public static Thread getThreadByThreadId(long threadId){
ThreadGroup group = Thread.currentThread().getThreadGroup();
while(group != null){
Thread[] threads = new Thread[(int)(group.activeCount() * 1.2)];
int count = group.enumerate(threads, true);
for(int i = 0; i < count; i++){
if(threadId == threads[i].getId()){
return threads[i];
}
}
}
}
}
上述解决分布式锁失效的问题在分布式锁领域有一个专业的术语叫做 “异步续命” 。需要注意的是:当业务代码执行完毕后,我们需要停止更新锁超时时间的线程。所以,这里,我对程序的改动是比较大的,首先,将更新锁超时的时间任务重新定义为一个UpdateLockTimeoutTask类,并将uuid和StringRedisTemplate注入到任务类中,在执行定时更新锁超时时间时,首先将当前线程保存到Redis中,其中Key为传递进来的uuid。
在首先获取分布式锁后,重新启动线程,并将uuid和StringRedisTemplate传递到任务类中执行任务。当业务代码执行完毕后,调用releaseLock()方法释放锁时,我们会通过uuid从Redis中获取更新锁超时时间的线程id,并通过线程id获取到更新锁超时时间的线程,调用线程的interrupt()方法来中断线程。
此时,当分布式锁释放后,更新锁超时的线程就会由于线程中断而退出了。
实现分布式锁的基本要求
结合上述的案例,我们可以得出实现分布式锁的基本要求:
支持互斥性 支持锁超时 支持阻塞和非阻塞特性 支持可重入性 支持高可用
通用分布式解决方案
在互联网行业,分布式锁是一个绕不开的话题,同时,也有很多通用的分布式锁解决方案,其中,用的比较多的一种方案就是使用开源的Redisson框架来解决分布式锁问题。
有关Redisson分布式锁的使用方案大家可以参考《【高并发】你知道吗?大家都在使用Redisson实现分布式锁了!!》
既然Redisson框架已经很牛逼了,我们直接使用Redisson框架是否能够100%的保证分布式锁不出问题呢?答案是无法100%的保证。因为在分布式领域没有哪一家公司或者架构师能够保证100%的不出问题,就连阿里这样的大公司、阿里的首席架构师这样的技术大牛也不敢保证100%的不出问题。
在分布式领域,无法做到100%无故障,我们追求的是几个9的目标,例如99.999%无故障。
CAP理论
在分布式领域,有一个非常重要的理论叫做CAP理论。
C:Consistency(一致性) A:Availability(可用性) P:Partition tolerance(分区容错性)
在分布式领域中,是必须要保证分区容错性的,也就是必须要保证“P”,所以,我们只能保证CP或者AP。
这里,我们可以使用Redis和Zookeeper来进行简单的对比,我们可以使用Redis实现AP架构的分布式锁,使用Zookeeper实现CP架构的分布式锁。
基于Redis的AP架构的分布式锁模型
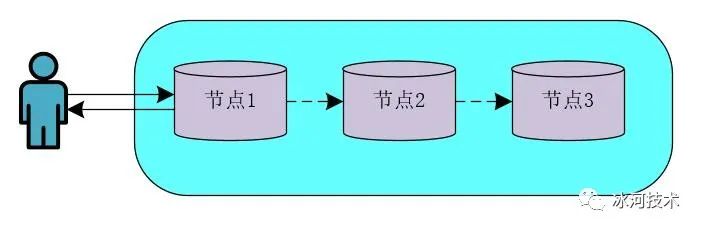
在基于Redis实现的AP架构的分布式锁模型中,向Redis节点1写入数据后,会立即返回结果,之后在Redis中会以异步的方式来同步数据。
基于Zookeeper的CP架构的分布式锁模型
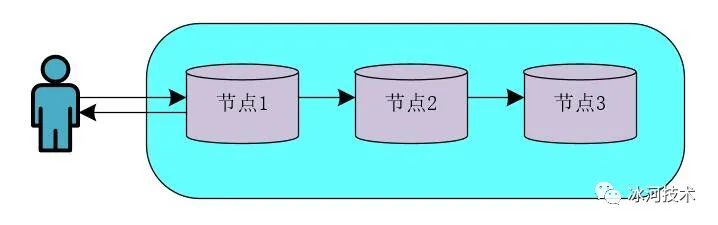
在基于Zookeeper实现的CP架构的分布式模型中,向节点1写入数据后,会等待数据的同步结果,当数据在大多数Zookeeper节点间同步成功后,才会返回结果数据。
当我们使用基于Redis的AP架构实现分布式锁时,需要注意一个问题,这个问题可以使用下图来表示。
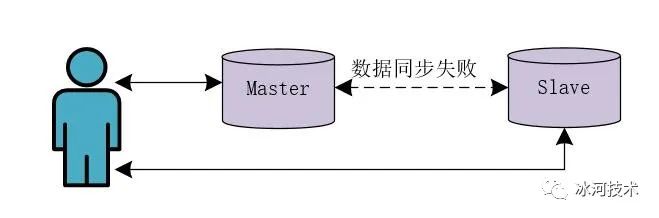
也就是Redis主从节点之间的数据同步失败,假设线程向Master节点写入了数据,而Redis中Master节点向Slave节点同步数据失败了。此时,另一个线程读取的Slave节点中的数据,发现没有添加分布式锁,此时就会出现问题了!!!
所以,在设计分布式锁方案时,也需要注意Redis节点之间的数据同步问题。
红锁的实现
在Redisson框架中,实现了红锁的机制,Redisson的RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个RLock对象关联为一个红锁,每个RLock对象实例可以来自于不同的Redisson实例。当红锁中超过半数的RLock加锁成功后,才会认为加锁是成功的,这就提高了分布式锁的高可用。
我们可以使用Redisson框架来实现红锁。
public void testRedLock(RedissonClient redisson1,RedissonClient redisson2, RedissonClient redisson3){
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
try {
// 同时加锁:lock1 lock2 lock3, 红锁在大部分节点上加锁成功就算成功。
lock.lock();
// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
其实,在实际场景中,红锁是很少使用的。这是因为使用了红锁后会影响高并发环境下的性能,使得程序的体验更差。所以,在实际场景中,我们一般都是要保证Redis集群的可靠性。同时,使用红锁后,当加锁成功的RLock个数不超过总数的一半时,会返回加锁失败,即使在业务层面任务加锁成功了,但是红锁也会返回加锁失败的结果。另外,使用红锁时,需要提供多套Redis的主从部署架构,同时,这多套Redis主从架构中的Master节点必须都是独立的,相互之间没有任何数据交互。
高并发“黑科技”与致胜奇招
假设,我们就是使用Redis来实现分布式锁,假设Redis的读写并发量在5万左右。我们的商城业务需要支持的并发量在100万左右。如果这100万的并发全部打入Redis中,Redis很可能就会挂掉,那么,我们如何解决这个问题呢?接下来,我们就一起来探讨这个问题。
在高并发的商城系统中,如果采用Redis缓存数据,则Redis缓存的并发处理能力是关键,因为很多的前缀操作都需要访问Redis。而异步削峰只是基本的操作,关键还是要保证Redis的并发处理能力。
解决这个问题的关键思想就是:分而治之,将商品库存分开放。
暗度陈仓
我们在Redis中存储商品的库存数量时,可以将商品的库存进行“分割”存储来提升Redis的读写并发量。
例如,原来的商品的id为10001,库存为1000件,在Redis中的存储为(10001, 1000),我们将原有的库存分割为5份,则每份的库存为200件,此时,我们在Redia中存储的信息为(10001_0, 200),(10001_1, 200),(10001_2, 200),(10001_3, 200),(10001_4, 200)。
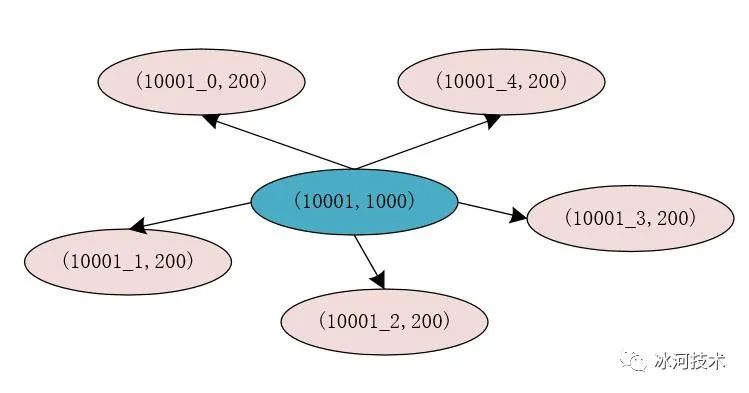
此时,我们将库存进行分割后,每个分割后的库存使用商品id加上一个数字标识来存储,这样,在对存储商品库存的每个Key进行Hash运算时,得出的Hash结果是不同的,这就说明,存储商品库存的Key有很大概率不在Redis的同一个槽位中,这就能够提升Redis处理请求的性能和并发量。
分割库存后,我们还需要在Redis中存储一份商品id和分割库存后的Key的映射关系,此时映射关系的Key为商品的id,也就是10001,Value为分割库存后存储库存信息的Key,也就是10001_0,10001_1,10001_2,10001_3,10001_4。在Redis中我们可以使用List来存储这些值。
在真正处理库存信息时,我们可以先从Redis中查询出商品对应的分割库存后的所有Key,同时使用AtomicLong来记录当前的请求数量,使用请求数量对从Redia中查询出的商品对应的分割库存后的所有Key的长度进行求模运算,得出的结果为0,1,2,3,4。再在前面拼接上商品id就可以得出真正的库存缓存的Key。此时,就可以根据这个Key直接到Redis中获取相应的库存信息。
同时,我们可以将分隔的不同的库存数据分别存储到不同的Redis服务器中,进一步提升Redis的并发量。
移花接木
在高并发业务场景中,我们可以直接使用Lua脚本库(OpenResty)从负载均衡层直接访问缓存。
这里,我们思考一个场景:如果在高并发业务场景中,商品被瞬间抢购一空。此时,用户再发起请求时,如果系统由负载均衡层请求应用层的各个服务,再由应用层的各个服务访问缓存和数据库,其实,本质上已经没有任何意义了,因为商品已经卖完了,再通过系统的应用层进行层层校验已经没有太多意义了!!而应用层的并发访问量是以百为单位的,这又在一定程度上会降低系统的并发度。
为了解决这个问题,此时,我们可以在系统的负载均衡层取出用户发送请求时携带的用户id,商品id和活动id等信息,直接通过Lua脚本等技术来访问缓存中的库存信息。如果商品的库存小于或者等于0,则直接返回用户商品已售完的提示信息,而不用再经过应用层的层层校验了。
重磅福利
微信搜一搜【冰河技术】微信公众号,关注这个有深度的程序员,每天阅读超硬核技术干货,公众号内回复【PDF】有我准备的一线大厂面试资料和我原创的超硬核PDF技术文档,以及我为大家精心准备的多套简历模板(不断更新中),希望大家都能找到心仪的工作,学习是一条时而郁郁寡欢,时而开怀大笑的路,加油。如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。如果有幸我们江湖再见!
另外,我开源的各个PDF,后续我都会持续更新和维护,感谢大家长期以来对冰河的支持!!
写在最后
如果你觉得冰河写的还不错,请微信搜索并关注「 冰河技术 」微信公众号,跟冰河学习高并发、分布式、微服务、大数据、互联网和云原生技术,「 冰河技术 」微信公众号更新了大量技术专题,每一篇技术文章干货满满!不少读者已经通过阅读「 冰河技术 」微信公众号文章,吊打面试官,成功跳槽到大厂;也有不少读者实现了技术上的飞跃,成为公司的技术骨干!如果你也想像他们一样提升自己的能力,实现技术能力的飞跃,进大厂,升职加薪,那就关注「 冰河技术 」微信公众号吧,每天更新超硬核技术干货,让你对如何提升技术能力不再迷茫!