
This is BigData, Hdoop组成及生态圈

引言
大数据概述
定义
数据单位
数据意义与价值
Hadoop概述
Hadoop组成
HDFS架构概述
YARN架构概述
MapReduce架构概述
三者之间的关系
Hadoop生态圈
学习资源
引言
随着科技的发展,我们在网上留下的数据越来越多,大到网上购物、商品交易,小到浏览网页、微信聊天、手机自动记录日常行程等,可以说,在如今的生活里,只要你还在,你就会每时每刻产生数据,但是这些数据能称为大数据么?不,这些还不能称为大数据。那么大数据数据到底是什么呢?

大数据概述
定义
百度百科的定义:大数据是指无法在一定时间范围内用常规的软件工具进行捕捉、管理和处理的大数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
可以总结出大数据的特点:
数据量大,需用采取某些工具才能采集,进而做分析计算。
举个例子来解释下:
Simon是个成龙影片的爱好者,他在网站上搜集到了100G的成龙经典电影(采集),为了收藏这些电影,他决定把这些电影都存储起起来(存储),有一天Simon突然想看成龙的主演的“十二生肖”,这部电影就在他存储的100G影片中,所以Simon按照上映年份(分析计算)找出了这部电影并观看了它。
因此,我们可以把大数据的定义凝练如下:
大数据主要解决的是海量数据的采集、存储和分析计算问题。
所谓大数据,数据的规模是怎么衡量呢?

数据单位
衡量数据的规模,需要先认识数据的单位。按照数据单位的从小到大划分,依次为:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
单位之间的换算如下:
1 Byte =8 bit
1 KB = 1,024 Bytes = 8192 bit
1 MB = 1,024 KB = 1,048,576 Bytes
1 GB = 1,024 MB = 1,048,576 KB
1 TB = 1,024 GB = 1,048,576 MB
1 PB = 1,024 TB = 1,048,576 GB
对于我们来讲,接触最多的可能是KB、MB、GB等单位。
但是由于计算机计算性能的不同,如果放在上古时代的计算机,让它们处理GB级别的数据就已经算是极限了;对于现在内存普遍是128G的服务器,多台并行处理EB级别的数据也不在话下。
数据意义与价值
每个时代都有对数据的定义,关键的目标是要挖掘出数据背后的意义和价值。
数据量那么大,格式又各不相同,我们处理数据的意义何在呢?
试想下,再大的数据也是由许许多多的小数据组成,大数据可以认为是数据的集合,我们可以从这些数据中推理出一个近似客观的规律,利用这个规律可以预测产生数据的本体下一次要发生的概率。如一个用户经常在某电影网站上观看成龙的电影,那么当该用户下一次访问电影网站时,将有关成龙的电影放在推荐列表中比较靠前的位置,因为我们通过用户的浏览的数据发现他很喜欢成龙的电影,并且相信相信该用户的兴趣短时内不会发生变化。
这是大数据在生活中的一个简单应用--挖掘用户的偏好,建立推荐模型。
数据时代,我们的数据具有海量,多样性,实时性,不确定性等特点。那么,我们要存储,处理这些特点的海量数据,用什么样的方式或说什么样的平台比较适合呢,经过多年的技术发展和自然选择,Hadoop分布式模型脱颖而出。
因此,学习大数据肯定绕不开Hadoop,但是对于接触大数据时间较短或者尚未接触过大数据的同学来说,如果问他们我们应该学习Hadoop的那些内容,分布式存储和计算一定会说出来,但是仅仅这两个概念还是太笼统了,那么我们应该怎样把控Hadoop的学习呢,莫慌,且听Simon郎慢慢道来。

Hadoop概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它主要解决的是海量数据的存储和海量数据的分析计算问题,从广义上来说,Hadoop通常是指Hadoop生态圈。
我们先看Hadoop的组成结构,然后介绍Hadoop生态圈。
Hadoop组成
Hadoop的组成结构在1.x和2/3.x有所不同,如下图所示
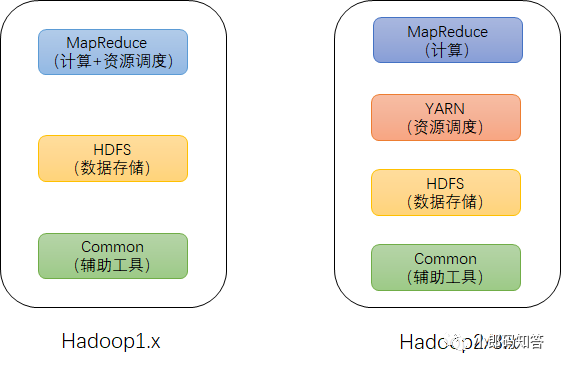
Hadoop主要是由:就计算、资源调度、数据存储和辅助工具组成。
在Hadoop1.x时代,Hadoop中的MapReduce 同时处理业务逻辑运算和资源调度,耦合性较大。在Hadoop2/3.x时代,增加了 Yarn,Yarn只负责资源的调度,MapReduce只负责运算。
Note:资源调度指的是CPU、内存、服务器计算的选择等
接下来,我们分别介绍:
用于存储的HDFS 用于资源调度的YARN 用于计算的MapReduce
HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统 ,HDFS的结构图如下:
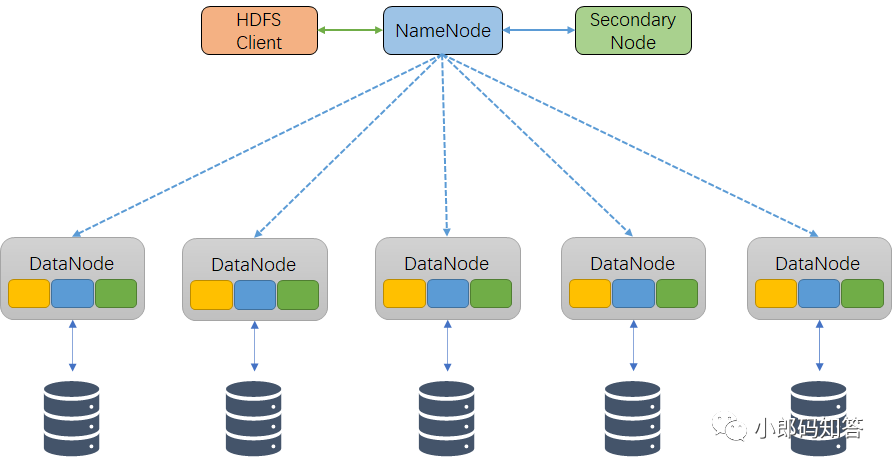
HDFS架构包含一个NameNode、DataNode和备用SecondaryNode。
NameNode(nn)
NameNode(nn)就是Master,它是一个主管,管理者,它主要有以下功能:
①管理HDFS的名称空间
②配置副本策略(如数据配置几个副本)
③管理数据块(block)的映射信息
数据存在Datanode的哪些数据块中,分布式存储的
④处理客户端的请求
DataNode(dn)
DataNode就是Slave,NameNode下达命令,DataNode执行实际的操作。
①存储实际的数据块
②执行数据块的读/写操作
Secondary NameNode(2nn)
①辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
②在紧急情况下,可辅助恢复NameNode。
NOTE:Secondary NameNode并非NameNode的热备,即当NameNode挂掉的时候,它并不 能马上替换NameNode并提供服务。
YARN架构概述
Yet Another Resource Negotiator 简称YARN,它是Hadoop的资源管理器,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。如下图所示:
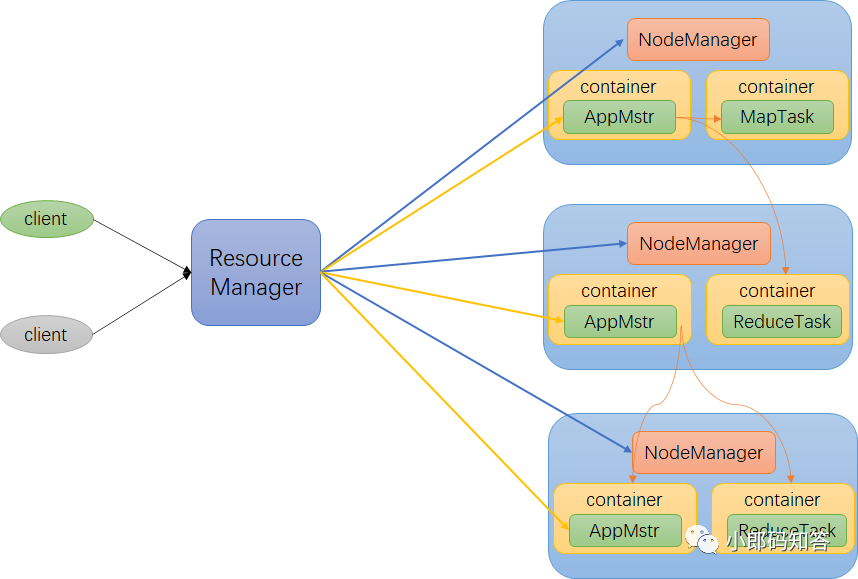
YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等组件构成。
ResourceManager(RM):整个集群资源(内存、cpu等)的老大 NodeManager(NM):单个节点服务器资源的老大 ApplicationMaster(AM):单个任务运行的老大 Container:容器,相当于一台独立的服务器,里面封装了任务运行所需的资源,如内存、CPU、磁盘、网络等。
NOTE:
ResourceManager是一个Master,在每一个子节点以下都有一个NodeManager,由RM给NM分配资源。在每一个节点中还会有ApplicationMaster(后面简称AM)的东西。他会负责与RM通信以获取资源,还会与NM通信来启动或者是停止任务。
MapReduce架构概述
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。他的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce将计算过程分为两个阶段:Map和Reduce
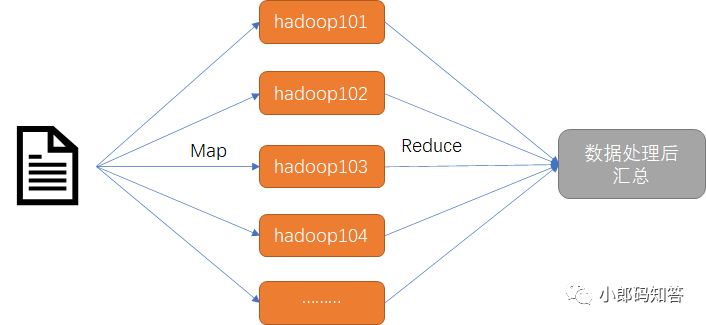
Map阶段并行处理输入数据 Reduce阶段对Map结果进行汇总
三者之间的关系
HDFS、YARN、MapReduce三者之间的关系
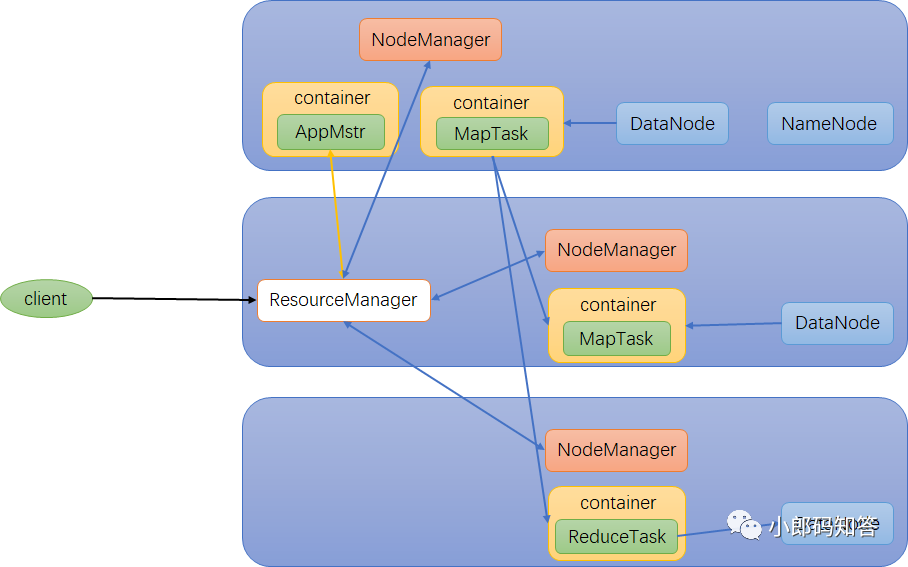
从HDFS中读取数据 Yarn资源调度处理这些数据 MapReduce收到Yarn的指令后开启相应的MapTask任务和ReduceTask任务 处理后的数据被存储在HDFS中
你以为Hadoop结束了,NO! NO! NO! Hadoop生态圈了解一波~
好吧,继续学!

Hadoop生态圈
先看一张Hadoop生态体系的脑图。
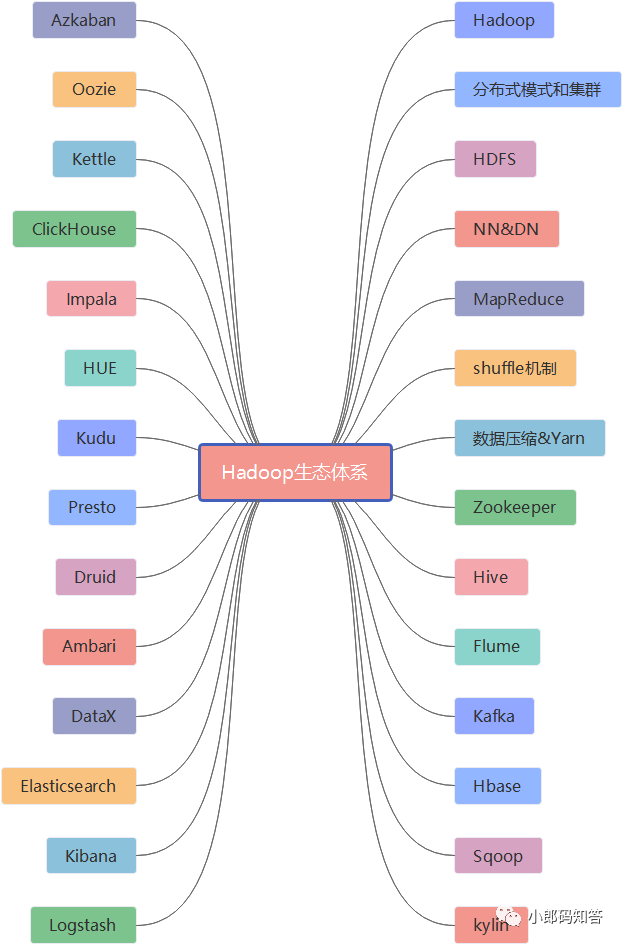
妈耶,咋那么多内容啊,快把我干懵逼了。千万别懵,虽然看起来很多,但是可以用一句总结:Hadoop是一个分布式计算开源框架,提供了一个分布式系统子项目(HDFS)和支持MapReduce分布式计算软件架构。既然脑图的内容有点多,咱们就介绍几个在Hadoop生态圈中占有地位较高的几个组件,如果小伙伴对其它组件感兴趣,可以自行查阅。
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hbase
Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建起大规模结构化存储集群。
Sqoop
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中
Zookeeper
Zookeeper 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
Ambari
Ambari是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
Oozie
Oozie是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
Hue
Hue是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
.........
Hadoop生态体系先介绍这么多,对其它内容感兴趣的同学自行补充。
学习资源
为了方便大家学习大数据,我整理了一份大数据学习资源,包含了学习路线、视频和项目。
公众号回复:02,即可获得。