
爱了!0.052s 打开 100GB 数据,这个开源库火爆了!
不点蓝字,我们哪来故事?


# 为什么要选择vaex?
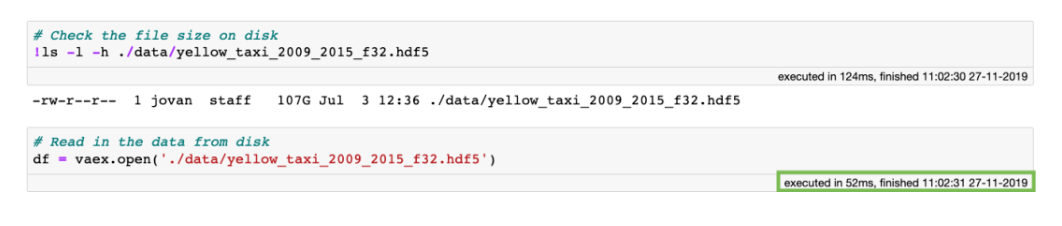
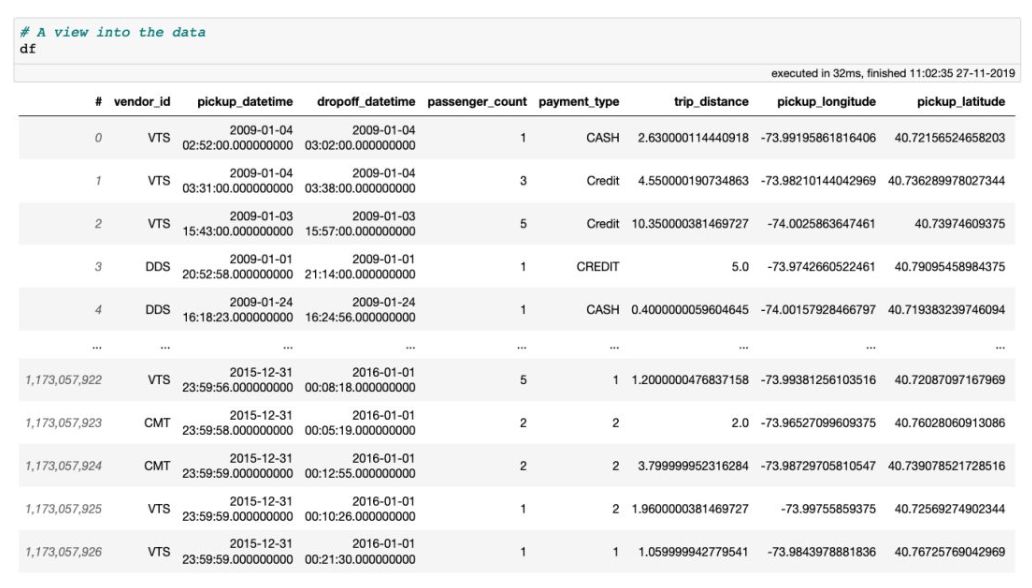
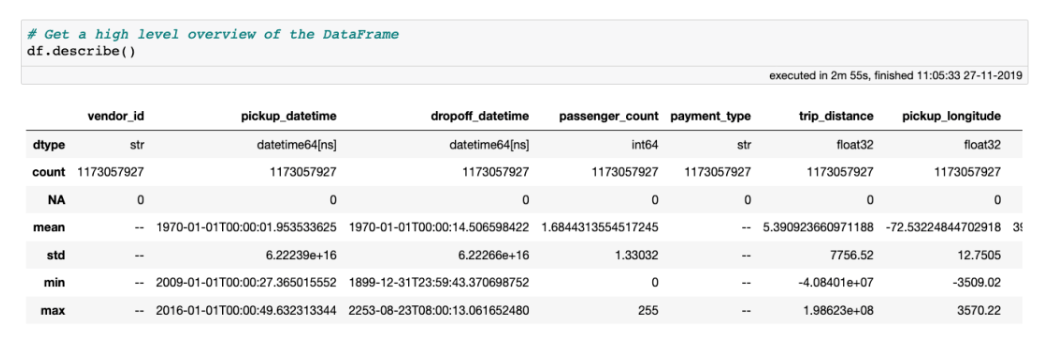
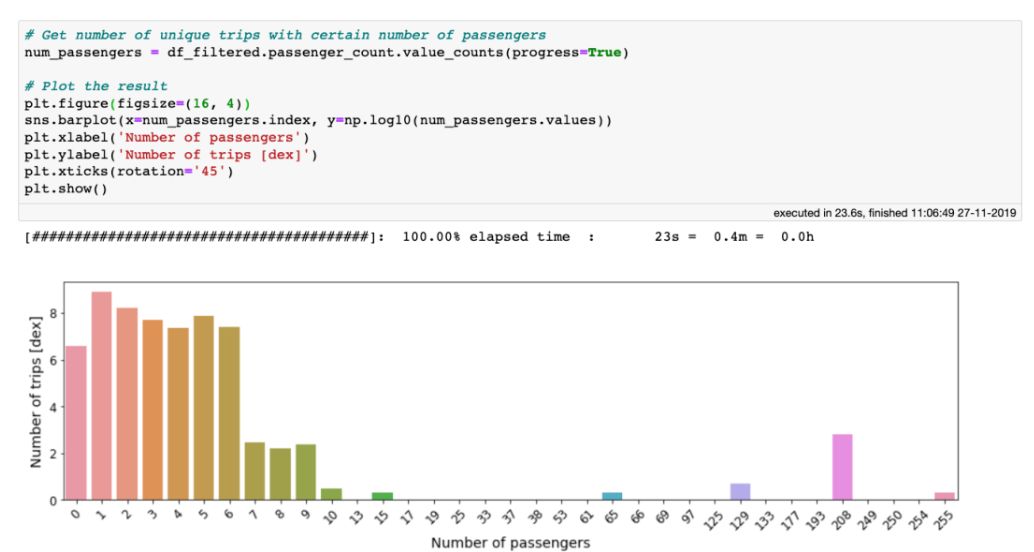
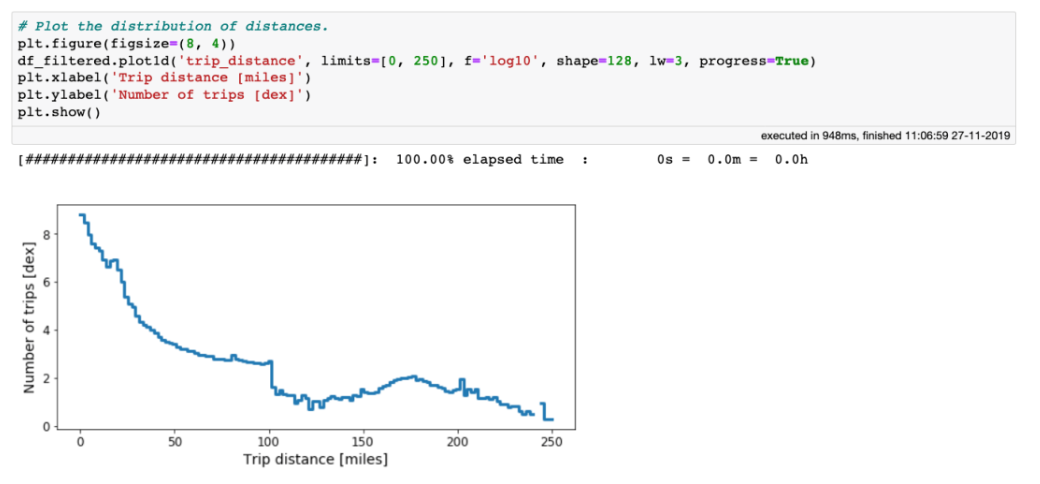
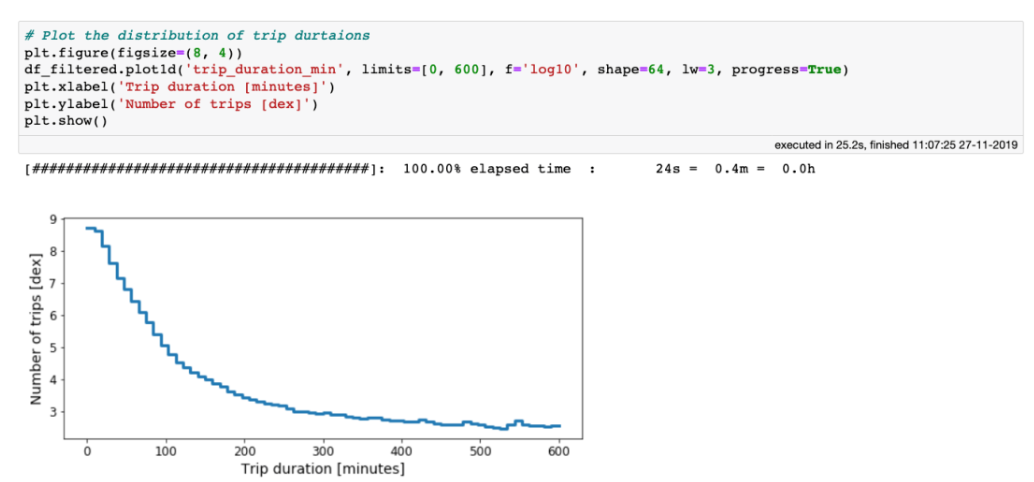
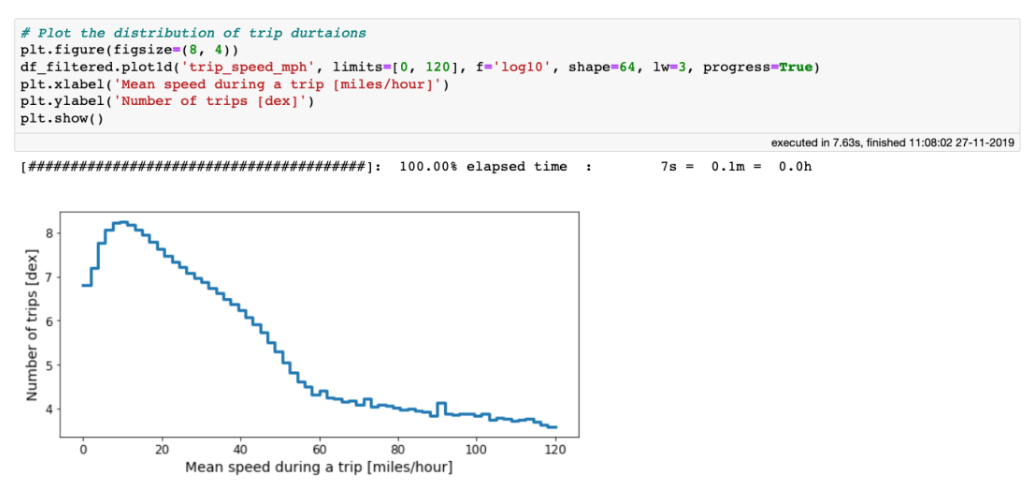
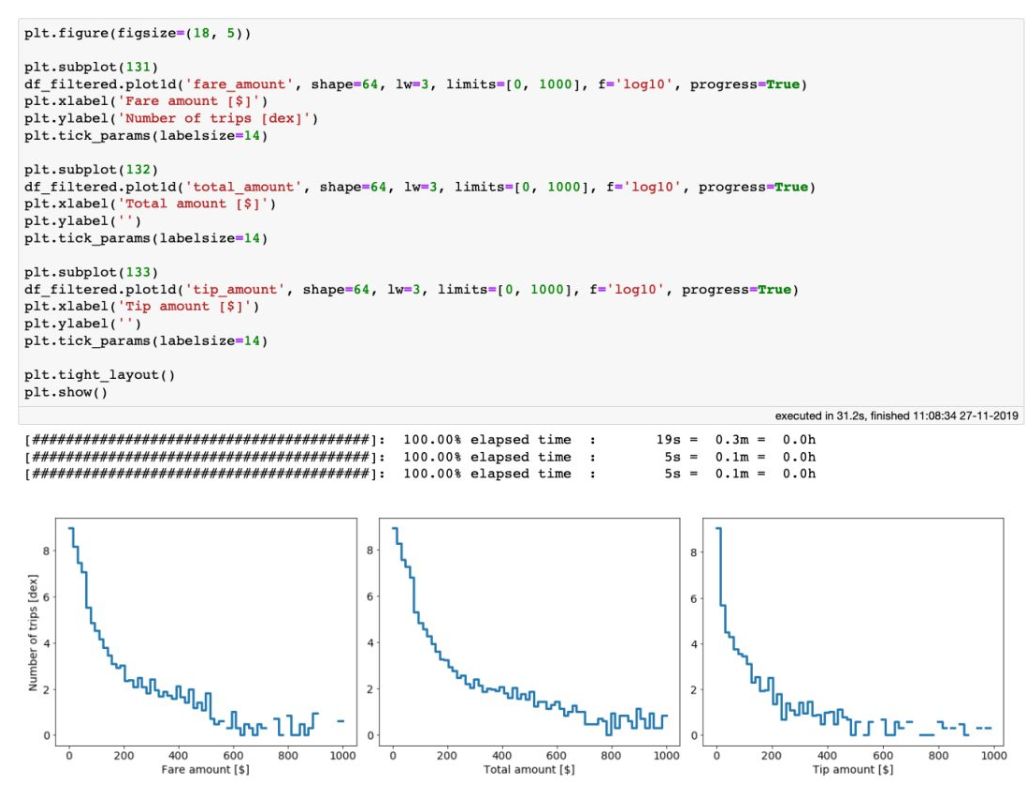
性能:处理海量表格数据,每秒处理超过十亿行 虚拟列:动态计算,不浪费内存 高效的内存在执行过滤/选择/子集时没有内存副本。 可视化:直接支持,单线通常就足够了。 用户友好的API:只需处理一个数据集对象,制表符补全和docstring可以帮助你:ds.mean ,类似于Pandas。 精益:分成多个包 Jupyter集成:vaex-jupyter将在Jupyter笔记本和Jupyter实验室中提供交互式可视化和选择。









往期推荐
下方二维码关注我

技术草根,坚持分享 编程,算法,架构
评论