
(二十三)机器人测试与评估
作者简介
作者:孟繁中
原文:https://zhuanlan.zhihu.com/p/349000987
转载者:杨夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study

Rasa开源允许您通过运行测试故事来验证和测试端到端的对话。此外,还可以分别测试对话管理和消息处理(NLU)。
验证数据和故事
数据验证功能验证您的Domain、NLU数据或故事数据中是否出现错误或重大不一致的情况。要验证数据,请让CI运行以下命令:
rasa data validate如果将max_history值传递给配置yml文件中,可以如下输入
rasa data validate --max-history 如果数据验证导致错误,那么训练模型也可能失败或产生糟糕的性能,因此在训练模型之前运行此检查总是好的。通过包含--fail on warnings标志,此步骤将在指示更多次要问题的警告时失败。
编写测试故事
运行rasa data validate不会测试规则是否与故事一致。但是,在培训期间,RulePolicy检查规则和故事之间的冲突。任何这样的冲突都会中止训练。
在测试故事中测试你的训练模型是让你的助手有更好表现的最好方法。测试故事以修改后的故事格式编写,允许您提供完整的对话,并测试在给定特定用户输入的情况下,您的模型将以预期的方式运行。当您开始从用户对话中引入更复杂的故事时,这一点尤为重要。
测试故事类似于培训数据中的故事,但也包括用户消息。例如:
stories:
- story: A basic story test
steps:
- user: |
hello
intent: greet
- action: utter_ask_howcanhelp
- user: |
show me [chinese]{"entity": "cuisine"} restaurants
intent: inform
- action: utter_ask_location
- user: |
in [Paris]{"entity": "location"}
intent: inform
- action: utter_ask_price默认情况下,该命令将对名称以test_开头的任何文件中的故事运行测试。还可以使用--stories参数提供特定的测试故事文件或目录。您可以通过运行以下命令来测试助手:
rasa test会话测试只与您包含的测试用例一样彻底和准确,因此您应该在改进助手的同时继续增加测试用例集。一个好的经验法则是,你应该把你的测试故事作为真实对话真实分布的代表。rasax使得在真实对话的基础上添加测试对话变得很容易。
评估NLU模型
除了测试故事之外,还可以单独测试自然语言理解(NLU)模型。一旦您的助手部署到现实世界中,它将处理它在训练数据中没有看到的消息。为了模拟这种情况,您应该始终留出部分数据进行测试。您可以使用以下方法将NLU数据拆分为训练集和测试集:
rasa data split nlu接下来,您可以看到经过训练的NLU模型对生成的测试集数据的预测效果如何,使用:
rasa test nlu
--nlu train_test_split/test_data.yml要更广泛地测试模型,请使用交叉验证,它会自动创建多个列/测试拆分:
rasa test nlu
--nlu data/nlu.yml
--cross-validation比较NLU性能
如果您对NLU培训数据进行了重大更改(例如,将一个意图拆分为两个意图或添加了大量培训示例),则应运行完整的NLU评估。您需要比较NLU模型的性能,而不需要对NLU模型进行更改。您可以通过在交叉验证模式下运行NLU测试来实现这一点:
rasa test nlu --cross-validation比较NLU管道
为了最大限度地利用训练数据,应该在不同的管道和不同数量的训练数据上训练和评估模型。
为此,请将多个配置文件传递给rasa test命令:
rasa test nlu --nlu data/nlu.yml
--config config_1.yml config_2.yml这将执行几个步骤:
从数据中创建一个全局数据集,80%训练数据、20%测试数据,从data/nlu.yml中分割的.
从全局列拆分中排除一定百分比的数据。
在剩余的训练数据上训练每个配置的模型。
在全局测试分割中评估每个模型。
在步骤2中,使用不同百分比的训练数据重复上述过程,以便了解如果增加训练数据量,每个管道将如何工作。由于训练不是完全确定的,所以对于指定的每个配置,整个过程重复三次。
绘制了一张图,图中显示了所有跑步中f1成绩的平均值和标准差。f1成绩图以及所有训练/测试集、训练模型、分类和错误报告将保存到名为nlu_comparison_results的文件夹中。
检查f1分数图可以帮助您了解是否有足够的数据用于NLU模型。如果图表显示,当使用所有的训练数据时,f1成绩仍在提高,则随着数据的增加,f1成绩可能会进一步提高。但是如果f1的分数在所有的训练数据都被使用的情况下趋于稳定,增加更多的数据可能没有帮助。
如果要更改运行次数或排除百分比,可以:
rasa test nlu --nlu data/nlu.yml
--config config_1.yml config_2.yml
--runs 4 --percentages 0 25 50 70 90解释输出
意图分类器
rasa test脚本将根据你的意图分类模型生成一个报告(intent_report.json),混淆矩阵(intent_confusion_matrix.png)和置信度直方图(intent_histogram.png)。
该报告记录了每个意图的准确度、召回率和f1分数,并提供了总体平均值。您可以使用--report参数将这些报告保存为JSON文件。
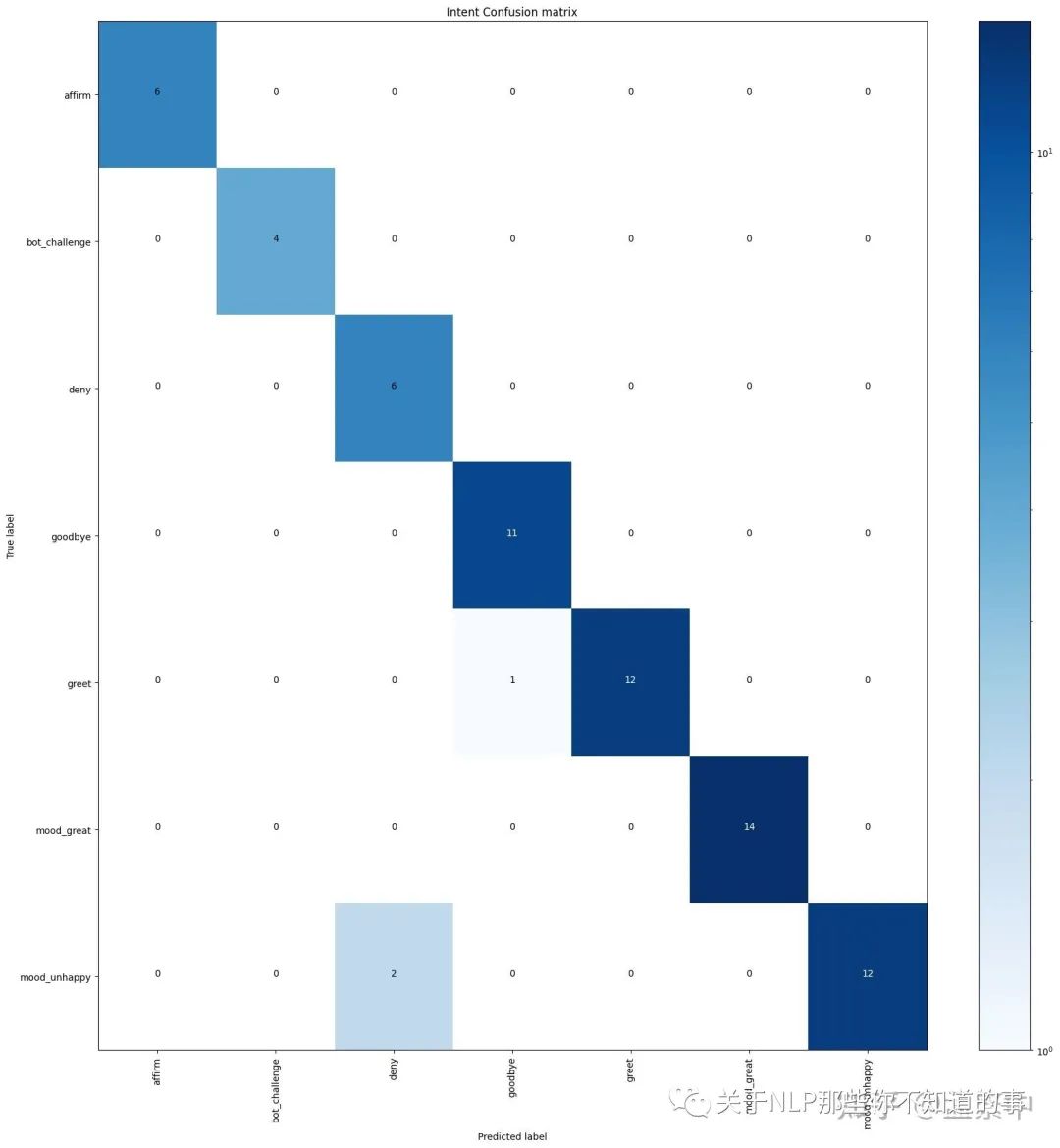
混淆矩阵显示哪些意图被误认为其他意图。任何被错误预测的样本都会被记录并保存到一个名为errors.json以便于调试。
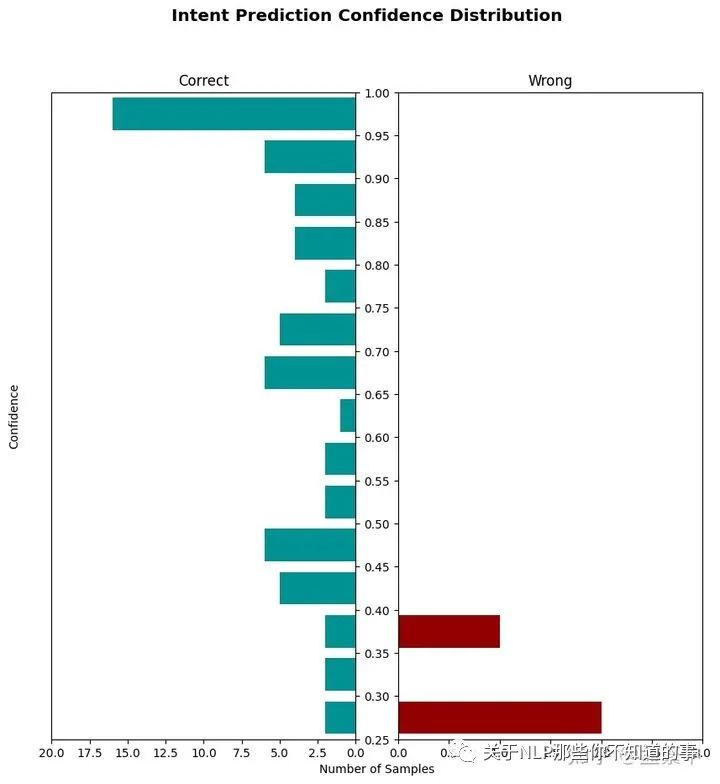
直方图允许您可视化所有预测的置信度,正确和不正确的预测分别以蓝色和红色条显示。提高训练数据的质量将使蓝色直方图条向上移动,红色直方图条向下移动。它还应该有助于减少红色直方图条本身的数量。
响应选择器
rasa test评估响应选择器的方式与评估意图分类器的方式相同,生成一个报告(response_selection_report.json),混淆矩阵(response_selection_confusion_matrix.png),置信度直方图(response_selection_histogram.png)和错误(response_selection_errors.json). 如果管道包含多个响应选择器,则它们将在单个报告中进行评估。
该报告记录了检索意图的每个子意图的精度、召回率和f1度量,并提供了总体平均值。您可以使用--report参数将这些报告保存为JSON文件。
实体提取
rasa测试报告每个实体类型的召回率、精确度和f1分数,您的可培训实体提取器经过培训可以识别这些类型。
只有可训练的实体提取器,如DIETClassifier和CRFEntityExtractor,才能通过rasa测试进行评估。像DucklingHTTPExtractor这样的预训练提取器不进行评估。
实体评分
为了评估实体提取,我们采用了一种简单的基于标记的方法。我们不完全考虑BILOU标记,只考虑每个标记的实体类型标记。对于“靠近亚历山大广场”这样的位置实体,我们希望标签是LOC LOC,而不是基于BILOU的B-LOC L-LOC。
当涉及到评估时,我们的方法更为宽松,因为它奖励部分提取,而不惩罚实体的拆分。例如,考虑到前面提到的实体“near-Alexanderplatz”和提取“Alexanderplatz”的系统,我们的方法奖励提取“Alexanderplatz”并惩罚漏掉的单词“near”。
然而,基于BILOU的方法将此标记为完全失败,因为它期望Alexanderplatz被标记为实体(L-LOC)中的最后一个令牌,而不是单个令牌实体(U-LOC)。还要注意的是,“near”和“Alexanderplatz”的分离提取在我们的方法中会得到满分,在基于BILOU的方法中会得到零分。
下面比较一下“今晚在亚历山大广场附近”这句话的两种得分机制:

评估对话模式
通过使用测试脚本,您可以在一组测试故事上评估经过培训的对话模型:
rasa test core --stories test_stories.yml --out results这将把所有失败的故事打印到results/failed_test_stories.yml. 如果至少有一个动作被错误预测,故事就会失败。
测试脚本还将把混淆矩阵保存到名为results/story_confmat.pdf. 对于域中的每个操作,混淆矩阵显示了正确预测操作的频率以及预测错误操作的频率。
比较策略配置#
要为对话模型选择配置,或为特定策略选择超参数,您需要衡量对话模型对以前从未见过的对话的泛化程度。尤其是在项目的开始阶段,当您没有很多实际的对话来训练您的bot时,您可能不想排除一些作为测试集使用的对话。
Rasa开源有一些脚本可以帮助您选择和微调策略配置。一旦您对它满意,就可以在完整的数据集上训练您的最终配置。
要做到这一点,您首先必须为不同的配置训练模型。创建两个(或更多)配置文件,包括要比较的策略,然后将它们提供给训练脚本以训练模型:
rasa train core -c config_1.yml config_2.yml \
--out comparison_models --runs 3 --percentages 0 5 25 50 70 95与NLU模型的评估方式类似,上面的命令在多种配置和不同数量的训练数据上训练对话模型。对于提供的每个配置文件,Rasa开源将训练对话模型,其中0、5、25、50、70和95%的训练故事将从训练数据中排除。重复三次以确保结果一致。
此脚本完成后,可以将多个模型传递给测试脚本,以比较刚刚训练的模型:
rasa test core -m comparison_models --stories stories_folder
--out comparison_results --evaluate-model-directory这将评估stories\文件夹中的stories(可以是training或test set)中的每个模型,并绘制一些图表来显示哪个策略性能最好。由于上一个train命令排除了一些训练数据来训练每个模型,因此上面的test命令可以测量模型预测出的故事有多好。要比较单个策略,请创建每个策略只包含一个策略的配置文件。
测试动作代码
用于测试动作代码的方法将取决于它的实现方式。例如,如果您连接到外部api,则应该编写集成测试,以确保这些api按照预期响应公共输入。无论如何测试操作代码,都应该在CI管道中包含这些测试,以便在每次进行更改时运行这些测试。