
Python副业400元,爬取阿里巴巴商城数据
1、任务简介
首先感谢蚂蚁学python群获取到这个单子,客户要求是获取阿里巴巴的列表页商品信息包含,商品title,商品主图片并且需要存入xls文件保存
2、解决方案
首先给出的方案是:
2.1、通过wxPython框架写出一个可视化界面,
2.2、因为阿里巴巴防爬比较严重,所以我直接通过selenium进行用户超过来跳过反扒机制
2.3、编写浏览器池方便实现多线程爬取数据
2.4、编写爬数据业务逻辑
3、现在开始上代码实现
3.1 首先初始先一个浏览器池子
from multiprocessing import Manager
from time import sleep
from tool.open_browser import open_browser
class DriverPool:
def __init__(self, max_nums,driver_path,ui,open_headless=0):
self.ui = ui
self.drivers = {}
self.manager = Manager()
self.queue = self.manager.Queue()
self.max_nums = max_nums
self.open_headless = open_headless
self.CreateDriver(driver_path)
def CreateDriver(self,driver_path):
'''
初始化浏览器池
:return
'''
for name in range(1, self.max_nums + 1):
name = f'driver_{name}'
d = open_browser(excute_path=driver_path,open_headless=self.open_headless)
d.ui = self.ui
self.drivers[name] = d
self.queue.put(name)
def getDriver(self):
'''
获取一个浏览器
:return driver
'''
if self.queue.empty():
sleep(1)
return self.getDriver()
name = self.queue.get()
driver = self.drivers[name]
driver.pool_name_driver = name
return driver
def putDriver(self, name):
'''
归还一个浏览器
:param name:
:return:
'''
self.queue.put(name)
def quit(self):
'''
关闭浏览器,执行结束操作
:return:
'''
if self.drivers:
for driver in self.drivers.values():
try:
driver.quit()
except:
pass
3.2 编写UI操作界面
def intUIRun(self):
'''
初始化UI主界面
:return:
'''
pannel = wx.Panel(self.panel_run)
pannel.Sizer = wx.BoxSizer(wx.VERTICAL)
self.text = wx.StaticText(pannel, -1, '状态栏目:', size=(100, 40), pos=(0, 10))
self.text_input = wx.StaticText(pannel, -1, '', size=(900, 40), pos=(100, 0))
wx.StaticText(pannel, -1, '当前执行ID:', size=(100, 30), pos=(0, 65)).SetFont(self.font)
self.text_time = wx.TextCtrl(pannel, id=self.choices_id_ref, value=self.time_str, size=(300, 30), pos=(150, 60),
style=wx.TE_AUTO_URL | wx.TE_MULTILINE)
self.reflush_text_time = wx.Button(pannel, -1, '刷新ID', size=(100, 50), pos=(480, 50))
self.text_time.SetFont(self.font)
self.reflush_text_time.SetForegroundColour(wx.RED)
self.reflush_text_time.SetFont(self.font)
# self.text_time.SetForegroundColour(wx.RED)
self.text_input.SetBackgroundColour(wx.WHITE)
self.text_input.SetLabel(self.in_text)
self.text_input.SetFont(self.font)
self.text.SetFont(self.font)
wx.Button(pannel, self.get_product, '获取商品保存本地', size=(200, 100), pos=(0, 100)).SetFont(self.font)
wx.Button(pannel, self.save_mysql, '保存数据库和OSS', size=(200, 100), pos=(200, 100)).SetFont(self.font)
wx.Button(pannel, self.end_process, '结束执行', size=(200, 100), pos=(400, 100)).SetFont(self.font)
self.log_text = wx.TextCtrl(pannel, size=(1000, 500), pos=(0, 210), style=wx.TE_MULTILINE | wx.TE_READONLY)
wx.LogTextCtrl(self.log_text)
self.Bind(wx.EVT_BUTTON, self.get_product_p, id=self.get_product)
self.Bind(wx.EVT_BUTTON, self.save_mysql_p, id=self.save_mysql)
self.Bind(wx.EVT_BUTTON, self.end_process_p, id=self.end_process)
self.text_time.Bind(wx.EVT_COMMAND_LEFT_CLICK, self.choices_id, id=self.choices_id_ref)
self.reflush_text_time.Bind(wx.EVT_BUTTON, self.reflush_time_evt)
self.panel_run.Sizer.Add(pannel, flag=wx.ALL | wx.EXPAND, proportion=1)
效果图
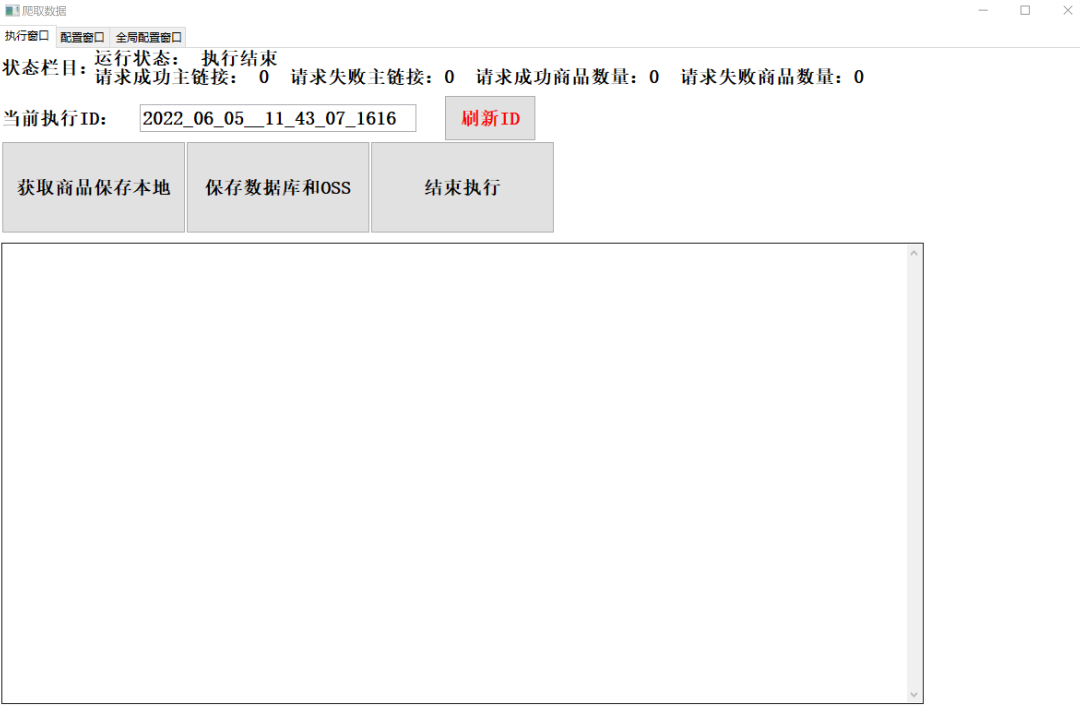
3.3编写业务逻辑
获取商品列表页数据
global _getMainProduct, goods_info
def _getMainProduct(data_url):
'''
多线程获取每一页链接
:param data_url:
:return:
'''
self, url, driver_pool = data_url
c = Common(driver_pool.getDriver())
goods_urls = []
try:
self.ui.print(f'当前获取第{url}页数据')
c.d.get(url)
c.wait_page_loaded(url)
if self.is_load_cache_cookies:
self.load_cookies(c.d)
c.d.get(url)
c.wait_page_loaded(url)
ele = c.find_element(By.CSS_SELECTOR, '[class="component-product-list"]')
goods_urls = ele.find_elements(By.CSS_SELECTOR, 'a[class="product-image"]')
goods_urls = [goods_url.get_attribute('href') for goods_url in goods_urls]
except SystemExit:
sys.exit(1)
except:
self.print(f'请求页面超出范围: {url} ERROR: {traceback.format_exc()}')
if c.find_element_true(By.CSS_SELECTOR, '[class="no-data common"]'):
return goods_urls
finally:
name = c.d.pool_name_driver
driver_pool.putDriver(name)
self.queue_print.put(f'请求完成:{url}')
return goods_urls
def getMainProduct_(self):
g_dict = globals()
urls = []
sum_l = self.pageNums[1] + 1
complate = 0
products = []
for i in range(self.pageNums[0], sum_l):
if self.ui.is_exit_process:
exit()
url = self.url.format(i)
urls.append([self, url, self.drive_pool])
if urls:
p = self.pool.map_async(_getMainProduct, urls)
while not p.ready():
if not self.queue_print.empty():
complate += 1
self.print(self.queue_print.get(), f'完成:{complate}/{sum_l - 1}')
products = p.get()
goods_info = set()
for xx in products:
for x in xx:
if x:
goods_info.add(x)
self.goods_info = goods_info
return goods_info
goods_info = getMainProduct_(self)
获取详情页数据
global goods,Common,driver_pool,goods_url,sleep,re,By
def get_info_(self, data_info):
'''
多线程获取详情页数据
:param self:
:param data_info:
:return:
'''
if self.ui.is_exit_process:
exit()
goods_url, driver_pool = data_info
c = Common(driver_pool.getDriver())
try:
c.d.get(goods_url)
sleep(3)
if self.is_load_cache_cookies:
self.load_cookies(c.d)
c.d.get(goods_url)
c.wait_page_loaded(goods_url)
for x in range(400, 18000, 200):
sleep(0.1)
c.d.execute_script(f'document.documentElement.scrollTop={x};')
is_all = c.find_element_true(By.CSS_SELECTOR, '[id="J-rich-text-description"]') # 'J-rich-text-description'
if not is_all:
self.print(f'没有发现: {is_all}')
is_video = c.find_elements_true(By.CSS_SELECTOR, '[class="bc-video-player"]>video')
is_title = c.find_element_true(By.CSS_SELECTOR, '[class="module-pdp-title"]')
is_description = c.find_element_true(By.CSS_SELECTOR, '[name="description"]')
is_keywords = c.find_element_true(By.CSS_SELECTOR, '[name="keywords"]')
is_overview = c.find_element_true(By.CSS_SELECTOR, '[class="do-overview"]')
is_wz_goods_cat_id = c.find_element_true(By.CSS_SELECTOR, '[class="detail-subscribe"]')
wz_goods_cat_id = self.wz_goods_cat_id
# if is_wz_goods_cat_id:
# wz_goods_cat_id = is_wz_goods_cat_id.find_elements(By.CSS_SELECTOR, '[class="breadcrumb-item"]>a')[
# -1].get_attribute('href')
# wz_goods_cat_id = re.search(r'(\d+)', wz_goods_cat_id).group(1)
# goods_id = re.search(r'(\d+)\.html$', goods_url)
goods_id = re.search(r'(ssssss\d+)\.html$', goods_url)
goods = {
"商品分类ID": int(wz_goods_cat_id) if wz_goods_cat_id else 0,
"商品ID": goods_id.group(1) if goods_id else self.getMd5(f'{time.time()}')+'其他',
"商品链接": goods_url,
"描述": c.find_element(By.CSS_SELECTOR, '[name="description"]').get_attribute(
'content') if is_description else '',
"标题": is_title.get_attribute('title') if is_title else '',
"关键字": c.find_element(By.CSS_SELECTOR, '[name="keywords"]').get_attribute(
'content') if is_keywords else is_keywords,
"视频连接": c.find_element(By.CSS_SELECTOR, '[class="bc-video-player"]>video').get_attribute(
'src') if is_video else '',
"主图片": [],
"商品详情": c.d.execute_script(
'''return document.querySelectorAll('[class="do-overview"]')[0].outerHTML;''') if is_overview else is_overview,
"商品描述": '',
"商品描述图片": []
}
# 获取商品描述图片
goods_desc = getDescriptionFactory1(self, c, goods_url)
goods.update(goods_desc)
# 获取主图片
m_imgs = c.find_elements(By.CSS_SELECTOR, '[class="main-image-thumb-ul"]>li')
for m_img in m_imgs:
try:
img = m_img.find_element(By.CSS_SELECTOR, '[class="J-slider-cover-item"]').get_attribute('src')
s = re.search('(\d+x\d+)', img)
img2 = None
if s:
img2 = str(img).replace(s.group(1), '')
goods['主图片'].append(img)
if img2:
goods['主图片'].append(img2)
except:
pass
self.ui.status['请求成功商品数量'] += 1
return goods
except:
traceback.print_exc()
self.print(f'=========================\n链接请求错误: {goods_url} \n {traceback.format_exc()}\n=========================')
self.error_page.append([goods_url, traceback.format_exc()])
self.ui.status['请求失败商品数量'] += 1
finally:
name = c.d.pool_name_driver
driver_pool.putDriver(name)
self.queue_print.put(f'请求完成:{goods_url}')
goods = get_info_(self,data_info)
写入excel
def export_excel(self, results):
'''
写入excel方法
:param results:
:return:
'''
now_dir_str = self.now
now_file_str = time.strftime('%Y_%m_%d__%H_%M_%S', time.localtime())
img_path = os.path.join('data', 'xls', now_dir_str)
if not os.path.exists(img_path):
os.mkdir(img_path)
img_path = os.path.join('data', 'xls', now_dir_str, self.url_id)
if not os.path.exists(img_path):
os.mkdir(img_path)
if not os.path.exists(img_path):
os.mkdir(img_path)
img_path = os.path.join(img_path, f"{now_file_str}.xlsx")
workbook = xlsxwriter.Workbook(img_path)
sheet = workbook.add_worksheet(name='阿里巴巴信息')
titles = list(results[0].keys())
for i, title in enumerate(titles):
sheet.write_string(0, i, title)
for row, result in enumerate(results):
row = row + 1
col = 0
for value in result.values():
sheet.write_string(row, col, str(value))
col += 1
workbook.close()
4、最后总结:
通过上述代码最终实现了客户的需求,由于通用selenium执行浏览器操作没有接口请求效率高,所以在最后使用了多线程在执行效率上也做了一些提升。
关注蚂蚁老师的抖音账号:Python导师-蚂蚁
每晚21点直播,给你讲解副业、Python学习路线;
评论