
Python 神器 Celery 源码解析(6):不同启动模式的分析

Celery是一款非常简单、灵活、可靠的分布式系统,可用于处理大量消息,并且提供了一整套操作此系统的工具。Celery 也是一款消息队列工具,可用于处理实时数据以及任务调度。
本文是是celery源码解析的第六篇,在前五篇里分别介绍了:
神器 celery 源码解析- vine实现Promise功能 神器 celery 源码解析- py-amqp实现AMQP协议 神器 celery 源码解析- kombu,一个python实现的消息库 神器 celery 源码解析- kombu的企业级算法 神器 celery 源码解析- celery启动流程分析
本章我们跟着日志一起看看一次完整的任务调度流程,从另外一个角度了解启动过程中celery都做了什么。
worker模式启动流程
我们启动celery的worker, 启动大概分成3个阶段,先看第一阶段创建蓝图:
✗ celery -A myapp worker -l DEBUG
[2021-11-24 15:53:12,984: DEBUG/MainProcess] | Worker: Preparing bootsteps.
[2021-11-24 15:53:12,988: DEBUG/MainProcess] | Worker: Building graph...
[2021-11-24 15:53:12,988: DEBUG/MainProcess] | Worker: New boot order: {StateDB, Timer, Hub, Pool, Autoscaler, Beat, Consumer}
[2021-11-24 15:53:13,005: DEBUG/MainProcess] | Consumer: Preparing bootsteps.
[2021-11-24 15:53:13,005: DEBUG/MainProcess] | Consumer: Building graph...
[2021-11-24 15:53:13,038: DEBUG/MainProcess] | Consumer: New boot order: {Connection, Events, Mingle, Tasks, Control, Gossip, Agent, Heart, event loop}
这一阶段主要启动了worker和consumer2个蓝图, 下面是蓝图的创建和日志可以完整对应:
class Blueprint:
def apply(self, parent, **kwargs):
# 创建蓝图
self._debug('Preparing bootsteps.')
order = self.order = []
steps = self.steps = self.claim_steps()
self._debug('Building graph...')
for S in self._finalize_steps(steps):
step = S(parent, **kwargs)
steps[step.name] = step
order.append(step)
self._debug('New boot order: {%s}',
', '.join(s.alias for s in self.order))
for step in order:
step.include(parent)
return self
第一个Worker蓝图在WorkController中,包括了下面一些步骤:
class WorkController:
class Blueprint(bootsteps.Blueprint):
"""Worker bootstep blueprint."""
name = 'Worker'
default_steps = {
'celery.worker.components:Hub',
'celery.worker.components:Pool',
'celery.worker.components:Beat',
'celery.worker.components:Timer',
'celery.worker.components:StateDB',
'celery.worker.components:Consumer',
'celery.worker.autoscale:WorkerComponent',
}
第二个Consumer蓝图在Consumer中,包括了下面一些步骤:
class Consumer:
"""Consumer blueprint."""
class Blueprint(bootsteps.Blueprint):
"""Consumer blueprint."""
name = 'Consumer'
default_steps = [
'celery.worker.consumer.connection:Connection',
'celery.worker.consumer.mingle:Mingle',
'celery.worker.consumer.events:Events',
'celery.worker.consumer.gossip:Gossip',
'celery.worker.consumer.heart:Heart',
'celery.worker.consumer.control:Control',
'celery.worker.consumer.tasks:Tasks',
'celery.worker.consumer.consumer:Evloop',
'celery.worker.consumer.agent:Agent',
]
创建完2个蓝图后,并没有立即启动蓝图,转而进入第二阶段创建启动worker,日志输出如下:
...
celery@192.168.5.28 v5.1.2 (sun-harmonics)
macOS-10.16-x86_64-i386-64bit 2021-11-24 11:04:09
[config]
.> app: myapp:0x7fc898739ac0
.> transport: redis://localhost:6379/0
.> results: redis://localhost:6379/0
.> concurrency: 12 (prefork)
.> task events: OFF (enable -E to monitor tasks in this worker)
[queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. celery.accumulate
. celery.backend_cleanup
. celery.chain
. celery.chord
. celery.chord_unlock
. celery.chunks
. celery.group
. celery.map
. celery.starmap
. myapp.add
...
这个过程app创建完成,把当前的配置信息,task列表都展示出来。展示信息的模版:
BANNER = """\
{hostname} v{version}
{platform} {timestamp}
[config]
.> app: {app}
.> transport: {conninfo}
.> results: {results}
.> concurrency: {concurrency}
.> task events: {events}
[queues]
{queues}
"""
EXTRA_INFO_FMT = """
[tasks]
{tasks}
"""
task信息来自app的tasks,在上篇我们介绍过,其实就是TaskRegistry;并发模式默认使用的prefork,多进程模式;然后是AMQP的消费者,queue,exchange等信息:
def extra_info(self):
if self.loglevel <= logging.INFO:
include_builtins = self.loglevel <= logging.DEBUG
tasklist = sep.join(
f' . {task}' for task in sorted(self.app.tasks)
if (not task.startswith(int_) if not include_builtins else task)
)
return EXTRA_INFO_FMT.format(tasks=tasklist)
def startup_info(self, artlines=True):
app = self.app
concurrency = str(self.concurrency)
appr = '{}:{:#x}'.format(app.main or '__main__', id(app))
...
banner = BANNER.format(
app=appr,
hostname=safe_str(self.hostname),
timestamp=datetime.now().replace(microsecond=0),
version=VERSION_BANNER,
conninfo=self.app.connection().as_uri(),
results=self.app.backend.as_uri(),
concurrency=concurrency,
platform=safe_str(_platform.platform()),
events=events,
queues=app.amqp.queues.format(indent=0, indent_first=False),
).splitlines()
...
我们可以查看celery的进程数,确认总共创建了12个进程(进程数是通过cpu核数计算出来):
➜ ~ ps -ef | grep celery
501 72465 68316 0 3:53下午 ttys003 0:10.17 /Library/Frameworks/Python.framework/Versions/3.8/Resources/Python.app/Contents/MacOS/Python /Users/yoo/work/yuanmahui/python/.venv/bin/celery -A myapp worker -l DEBUG
...
501 72479 72465 0 3:53下午 ttys003 0:00.01 /Library/Frameworks/Python.framework/Versions/3.8/Resources/Python.app/Contents/MacOS/Python /Users/yoo/work/yuanmahui/python/.venv/bin/celery -A myapp worker -l DEBUG
501 80540 71485 0 5:33下午 ttys005 0:00.00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn celery
除了默认的多进程方式,celery还支持下面这些并发模式:
ALIASES = {
'prefork': 'celery.concurrency.prefork:TaskPool',
'eventlet': 'celery.concurrency.eventlet:TaskPool',
'gevent': 'celery.concurrency.gevent:TaskPool',
'solo': 'celery.concurrency.solo:TaskPool',
'processes': 'celery.concurrency.prefork:TaskPool', # XXX compat alias
'threads': 'celery.concurrency.thread:TaskPool'
}
def get_implementation(cls):
"""Return pool implementation by name."""
return symbol_by_name(cls, ALIASES)
threads 需要concurrent.futures支持,也就是python3.2版本以上
worker启动的第3阶段就是启动蓝图,日志如下:
[2021-11-24 15:53:13,062: DEBUG/MainProcess] | Worker: Starting Hub
[2021-11-24 15:53:13,062: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:13,062: DEBUG/MainProcess] | Worker: Starting Pool
[2021-11-24 15:53:13,410: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:13,411: DEBUG/MainProcess] | Worker: Starting Consumer
[2021-11-24 15:53:13,411: DEBUG/MainProcess] | Consumer: Starting Connection
[2021-11-24 15:53:15,902: INFO/MainProcess] Connected to redis://localhost:6379/0
[2021-11-24 15:53:15,902: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:15,902: DEBUG/MainProcess] | Consumer: Starting Events
[2021-11-24 15:53:15,918: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:15,918: DEBUG/MainProcess] | Consumer: Starting Mingle
[2021-11-24 15:53:15,918: INFO/MainProcess] mingle: searching for neighbors
[2021-11-24 15:53:16,966: INFO/MainProcess] mingle: all alone
[2021-11-24 15:53:16,966: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:16,967: DEBUG/MainProcess] | Consumer: Starting Tasks
[2021-11-24 15:53:16,975: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:16,975: DEBUG/MainProcess] | Consumer: Starting Control
[2021-11-24 15:53:16,988: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:16,988: DEBUG/MainProcess] | Consumer: Starting Gossip
[2021-11-24 15:53:17,001: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:17,002: DEBUG/MainProcess] | Consumer: Starting Heart
[2021-11-24 15:53:17,008: DEBUG/MainProcess] ^-- substep ok
[2021-11-24 15:53:17,008: DEBUG/MainProcess] | Consumer: Starting event loop
[2021-11-24 15:53:17,008: DEBUG/MainProcess] | Worker: Hub.register Pool...
[2021-11-24 15:53:17,009: INFO/MainProcess] celery@192.168.5.28 ready.
[2021-11-24 15:53:17,010: DEBUG/MainProcess] basic.qos: prefetch_count->48
在worker启动中,我们需要关注worker蓝图的hub,pool二步(step),consumer蓝图的connection,events,mingle,task,control,gossip,heart和Evloop七步(step)。
beat模式启动流程
beat模式的启动和worker模式不一样。beat模式主要是定时处理,并且beat模式不执行具体的任务,只是负责触发定时任务。其启动日志如下:
✗ celery -A myapp beat -l DEBUG
celery beat v5.0.5 (singularity) is starting.
__ - ... __ - _
LocalTime -> 2021-12-05 15:40:39
Configuration ->
. broker -> redis://localhost:6379/0
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%DEBUG
. maxinterval -> 5.00 minutes (300s)
[2021-12-05 15:40:39,639: DEBUG/MainProcess] Setting default socket timeout to 30
[2021-12-05 15:40:39,639: INFO/MainProcess] beat: Starting...
[2021-12-05 15:40:39,667: DEBUG/MainProcess] Current schedule:
[2021-12-05 15:40:39,668: DEBUG/MainProcess] beat: Ticking with max interval->5.00 minutes
[2021-12-05 15:40:39,668: DEBUG/MainProcess] beat: Waking up in 5.00 minutes.
[2021-12-05 15:45:39,608: DEBUG/MainProcess] beat: Synchronizing schedule...
[2021-12-05 15:45:39,609: DEBUG/MainProcess] beat: Waking up in 5.00 minutes.
从日志可以看到beat模式启动也大概可以分成2个阶段。第一个阶段就是创建和启动任务调度器,由beat命令提供:
class Beat:
"""Beat as a service."""
def run(self):
print(str(self.colored.cyan(
f'celery beat v{VERSION_BANNER} is starting.')))
self.init_loader()
self.set_process_title()
self.start_scheduler()
第二个阶段,任务调度器开始时间循环:
# celery/beat.py
class Service:
"""Celery periodic task service."""
scheduler_cls = PersistentScheduler
def start(self, embedded_process=False):
info('beat: Starting...')
debug('beat: Ticking with max interval->%s',
humanize_seconds(self.scheduler.max_interval))
signals.beat_init.send(sender=self)
if embedded_process:
signals.beat_embedded_init.send(sender=self)
platforms.set_process_title('celery beat')
try:
while not self._is_shutdown.is_set():
interval = self.scheduler.tick()
if interval and interval > 0.0:
debug('beat: Waking up %s.',
humanize_seconds(interval, prefix='in '))
time.sleep(interval)
if self.scheduler.should_sync():
self.scheduler._do_sync()
except (KeyboardInterrupt, SystemExit):
self._is_shutdown.set()
finally:
self.sync()
这里的时间循环使用一个while循环去完成,每次tick都会检查是否有需要执行的任务,默认5分钟检查一次。
如果到达任务执行的时刻,则是通过下面的apply_async发送到worker(远程)去执行:
def apply_async(self, entry, producer=None, advance=True, **kwargs):
# Update time-stamps and run counts before we actually execute,
# so we have that done if an exception is raised (doesn't schedule
# forever.)
entry = self.reserve(entry) if advance else entry
task = self.app.tasks.get(entry.task)
try:
entry_args = [v() if isinstance(v, BeatLazyFunc) else v for v in (entry.args or [])]
entry_kwargs = {k: v() if isinstance(v, BeatLazyFunc) else v for k, v in entry.kwargs.items()}
return task.apply_async(entry_args, entry_kwargs,
producer=producer,
**entry.options)
multi模式启动流程
使用multi模式启动celery,可以让celery以服务的形式在background执行任务,并且可以启动更多的celery的执行进程。使用下面命令启动2个node ,w1和w2。
✗ celery multi start w1 w2 -A myapp -l DEBUG
celery multi v5.0.5 (singularity)
> Starting nodes...
> w1@bogon: OK
> w2@bogon: OK
注意这个命令需要sudo权限
使用下面命令监测celery服务的状态。
✗ celery -A myapp status
-> w1@bogon: OK
-> w2@bogon: OK
2 nodes online.
w1的启动流程会写入到日志,日志内容如下:
✗ cat /var/log/celery/w1.log
[2021-12-05 15:59:11,161: DEBUG/MainProcess] | Worker: Preparing bootsteps.
[2021-12-05 15:59:11,162: DEBUG/MainProcess] | Worker: Building graph...
[2021-12-05 15:59:11,163: DEBUG/MainProcess] | Worker: New boot order: {Beat, StateDB, Timer, Hub, Pool, Autoscaler, Consumer}
[2021-12-05 15:59:11,175: DEBUG/MainProcess] | Consumer: Preparing bootsteps.
[2021-12-05 15:59:11,175: DEBUG/MainProcess] | Consumer: Building graph...
[2021-12-05 15:59:11,206: DEBUG/MainProcess] | Consumer: New boot order: {Connection, Events, Mingle, Tasks, Control, Agent, Gossip, Heart, event loop}
[2021-12-05 15:59:11,219: DEBUG/MainProcess] | Worker: Starting Hub
[2021-12-05 15:59:11,219: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:11,220: DEBUG/MainProcess] | Worker: Starting Pool
[2021-12-05 15:59:11,517: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:11,518: DEBUG/MainProcess] | Worker: Starting Consumer
[2021-12-05 15:59:11,518: DEBUG/MainProcess] | Consumer: Starting Connection
[2021-12-05 15:59:11,549: INFO/MainProcess] Connected to redis://localhost:6379/0
[2021-12-05 15:59:11,549: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:11,549: DEBUG/MainProcess] | Consumer: Starting Events
[2021-12-05 15:59:11,561: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:11,561: DEBUG/MainProcess] | Consumer: Starting Mingle
[2021-12-05 15:59:11,562: INFO/MainProcess] mingle: searching for neighbors
[2021-12-05 15:59:12,602: INFO/MainProcess] mingle: all alone
[2021-12-05 15:59:12,602: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:12,603: DEBUG/MainProcess] | Consumer: Starting Tasks
[2021-12-05 15:59:12,609: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:12,609: DEBUG/MainProcess] | Consumer: Starting Control
[2021-12-05 15:59:12,621: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:12,622: DEBUG/MainProcess] | Consumer: Starting Gossip
[2021-12-05 15:59:12,632: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:12,633: DEBUG/MainProcess] | Consumer: Starting Heart
[2021-12-05 15:59:12,638: DEBUG/MainProcess] ^-- substep ok
[2021-12-05 15:59:12,638: DEBUG/MainProcess] | Consumer: Starting event loop
[2021-12-05 15:59:12,638: DEBUG/MainProcess] | Worker: Hub.register Pool...
[2021-12-05 15:59:12,639: INFO/MainProcess] w1@bogon ready.
[2021-12-05 15:59:12,639: DEBUG/MainProcess] basic.qos: prefetch_count->48
[2021-12-05 15:59:18,039: DEBUG/MainProcess] pidbox received method hello(from_node='w2@bogon', revoked={}) [reply_to:{'exchange': 'reply.celery.pidbox', 'routing_key': '196c0b68-a329-3e09-a1cf-54abb5e057db'} ticket:e640e757-9514-436c-8548-0ddcbe15f9a4]
[2021-12-05 15:59:18,040: INFO/MainProcess] sync with w2@bogon
[2021-12-05 15:59:19,088: DEBUG/MainProcess] w2@bogon joined the party
w1的启动方式和worker模式基本一致,特别的地方在日志的最后部分显示w2启动完成后,w1和w2进行了互联。对应可以在w2的日志中看到w1的连接信息:
✗ cat /var/log/celery/w2.log
...
[2021-12-05 15:59:19,089: INFO/MainProcess] w2@bogon ready.
[2021-12-05 15:59:19,089: DEBUG/MainProcess] basic.qos: prefetch_count->48
[2021-12-05 15:59:20,663: DEBUG/MainProcess] w1@bogon joined the party
所以multi模式的特点就是新增加了Cluster和Node的概念,用来管理所有的worker,主要代码如下:
@splash
@using_cluster
def start(self, cluster):
self.note('> Starting nodes...')
return int(any(cluster.start()))
def start(self):
return [self.start_node(node) for node in self]
def start_node(self, node):
maybe_call(self.on_node_start, node)
retcode = node.start(
self.env,
on_spawn=self.on_child_spawn,
on_signalled=self.on_child_signalled,
on_failure=self.on_child_failure,
)
maybe_call(self.on_node_status, node, retcode)
return retcode
Node直接同步是在Gossip的step中:
class Gossip(bootsteps.ConsumerStep):
...
def on_node_join(self, worker):
debug('%s joined the party', worker.hostname)
self._call_handlers(self.on.node_join, worker)
完成测试后,可以使用命令
celery multi stop w1 w2关闭node
worker接收任务流程
worker接收任务并执行的日志如下:
[2021-11-24 21:33:50,535: INFO/MainProcess] Received task: myapp.add[e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2]
[2021-11-24 21:33:50,535: DEBUG/MainProcess] TaskPool: Apply <function _trace_task_ret at 0x7fe6086ac280> (args:('myapp.add', 'e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2', {'lang': 'py', 'task': 'myapp.add', 'id': 'e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2', 'shadow': None, 'eta': None, 'expires': None, 'group': None, 'group_index': None, 'retries': 0, 'timelimit': [None, None], 'root_id': 'e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2', 'parent_id': None, 'argsrepr': '(16, 16)', 'kwargsrepr': '{}', 'origin': 'gen83110@192.168.5.28', 'reply_to': '63862dbb-9d82-3bdd-b7fb-03580941362a', 'correlation_id': 'e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2', 'hostname': 'celery@192.168.5.28', 'delivery_info': {'exchange': '', 'routing_key': 'celery', 'priority': 0, 'redelivered': None}, 'args': [16, 16], 'kwargs': {}}, b'[[16, 16], {}, {"callbacks": null, "errbacks": null, "chain": null, "chord": null}]', 'application/json', 'utf-8') kwargs:{})
[2021-11-24 21:33:50,536: DEBUG/MainProcess] Task accepted: myapp.add[e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2] pid:83086
[2021-11-24 21:33:50,537: INFO/ForkPoolWorker-8] Task myapp.add[e9bb4aa0-8280-443f-a5ed-3deb0a0b99c2] succeeded in 0.000271957000000711s: 32
从日志信息可以看到,主进程MainProcess收到task执行的请求,然后从任务池中获取到任务,然后调度任务到一个子进程ForkPoolWorker-9中执行。
任务的接收是在默认的策略函数中开始:
# celery/worker/strategy.py
def default(task, app, consumer,
info=logger.info, error=logger.error, task_reserved=task_reserved,
to_system_tz=timezone.to_system, bytes=bytes,
proto1_to_proto2=proto1_to_proto2):
"""Default task execution strategy.
Note:
Strategies are here as an optimization, so sadly
it's not very easy to override.
"""
...
info('Received task: %s', req)
...
任务池是由并发模型提供:
# celery/concurrency/base.py
def apply_async(self, target, args=None, kwargs=None, **options):
"""Equivalent of the :func:`apply` built-in function.
Callbacks should optimally return as soon as possible since
otherwise the thread which handles the result will get blocked.
"""
kwargs = {} if not kwargs else kwargs
args = [] if not args else args
if self._does_debug:
logger.debug('TaskPool: Apply %s (args:%s kwargs:%s)',
target, truncate(safe_repr(args), 1024),
truncate(safe_repr(kwargs), 1024))
return self.on_apply(target, args, kwargs,
waitforslot=self.putlocks,
callbacks_propagate=self.callbacks_propagate,
**options)
小结
我们通过对worker,beat和multi三种启动模式的日志跟踪分析,对celery的启动流程和模块功能有更进一步的了解。
三个模式都需要创建app,所以启动时候通过参数-A myapp参数,由app创建/查找各种task。不同的地方首先是beat和worker/multi不同,beat实际上就是一个生产者,通过配置定时的产生任务,然后发送给worker/multi具体执行。
其次不同的是worker和multi的运作方式,multi以服务方式运行,并且可以跨机器。在worker模式下,本机创建多个工作进程,是一个多进程模型。multi则是多个机器Node形成一个Cluster集群,任务在集群内部进行调度。
celery的分布式模型大概可以如下图:
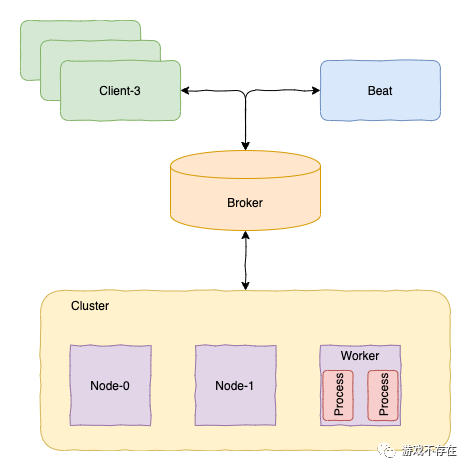
同时通过运行日志分析,我们可以知道celery的启动过程通过不同的Blueprint的不同Step过程实现;定时功能主要在beat和schedule模块实现;而分布式功能主要在concurrency模块,这样对各个模块的主体功能分工会有更清晰的认知。

还不过瘾?试试它们