
信用卡欺诈检测|用启发式搜索优化XGBoost超参数
大家好,我是云朵君!关注『数据STUDIO』,和云朵君一起学习数据分析与挖掘!
本文将展示如何使用模拟退火[1]启发式搜索[2]机器学习算法中超参数的最佳组合。这些方法比盲随机生成参数得到的模型效果好。另外,模型效果最好是分别微调每个超参数,因为它们之间通常存在交互。
👆点击关注|设为星标|干货速递👆
模拟退火简介
模拟退火是一种用于逼近给定函数的全局最优值的概率技术。具体来说,对于优化问题,在大型搜索空间中近似全局优化是一种元启发式。它通常用于搜索空间是离散的。对于在固定时间内找到近似全局最优比找到精确局部最优更重要的问题,模拟退火可能比精确算法(如梯度下降或分支定界)更可取。
该算法的名称来自冶金中的退火,这是一种涉及加热和控制材料冷却以增加其晶体尺寸并减少其缺陷的技术。两者都是取决于其热力学自由能的材料属性。加热和冷却材料会影响温度和热力学自由能或吉布斯能。模拟退火可用于精确算法失败的非常困难的计算优化问题;尽管它通常会获得全局最小值的近似解,但它对于许多实际问题来说已经足够了。
在模拟退火算法中实施的这种缓慢冷却的概念被解释为在探索解决方案空间时接受更差解决方案的概率缓慢下降。接受更差的解决方案允许更广泛地搜索全局最优解决方案。
通常,模拟退火算法的工作方式如下。温度从初始正值逐渐降低到零。在每个时间步,算法随机选择一个接近当前解的解,测量它的质量,并根据选择更好或更差解的温度相关概率移动到它,在搜索过程中分别保持在 1(或正值) ) 并趋向于零。
选用XGBoost算法来应用该方法,是一个很好的例子,因为它有许多超参数。穷举网格搜索在计算上可能是行不通的。
关于XGBoost的理论细节的讨论,请参阅这个Slideshare presentation[3] ,标题为"Kaggle Winning Solution XGBoost algorithm—Let us learn from its author",作者是陈天奇。
数据集描述
本文数据集取自Kaggle数据集,其中包含信用卡交易数据和欺诈标签。它最初是Dal Pozzolo, Andrea等人在Computational Intelligence, 2015 IEEE Symposium Series on. IEEE, 2015 Calibrating Probability with Undersampling for Unbalanced Classification[4] 发表的名为用不平衡分类的欠采样概率校准的文章内所使用的数据集。数据集中有Time变量(第一次交易的时间),Amount变量,Class变量(1=欺诈,0=非欺诈),以及其余的(V1-V28)是对原始变量进行主成分分析得到的因子变量。若有朋友需要本数据集,可直接联系原文作者云朵君(wx: Mr_cloud_data)免费获取!
对于XGBoost来说,训练及预测该数据集,并不是一个非常困难的情况。本文的主要目的是来说明启发式搜索从相当大的潜在组合集中找到合适的超参数集的方法。
从下文数据探索中发现,这是一个典型的欺诈检测数据集,且是一个高度不平衡的数据集。因此在XGBoost参数中设置观测值的权重时需要将该因素考虑进去。
本数据集相对较大,因此可以将其划分为训练集、验证集及测试集合,将在一个验证数据集上校准超参数,并在一个新的测试数据集上评估模型预测性能。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import random
random.seed(1234)
plt.style.use('ggplot')
dat = pd.read_csv('creditcard.csv')
dat.head()
df['Class'].value_counts()/len(df)
0 0.998273
1 0.001727
Name: Class, dtype: float64
数据探索
缺失值分析
total = dat.isnull().sum().sort_values(ascending = False)
percent = (dat.isnull().sum()/dat.isnull().count()*100
).sort_values(ascending = False)
pd.concat([total, percent], axis=1,
keys=['Total', 'Percent']).transpose()
数据集分布
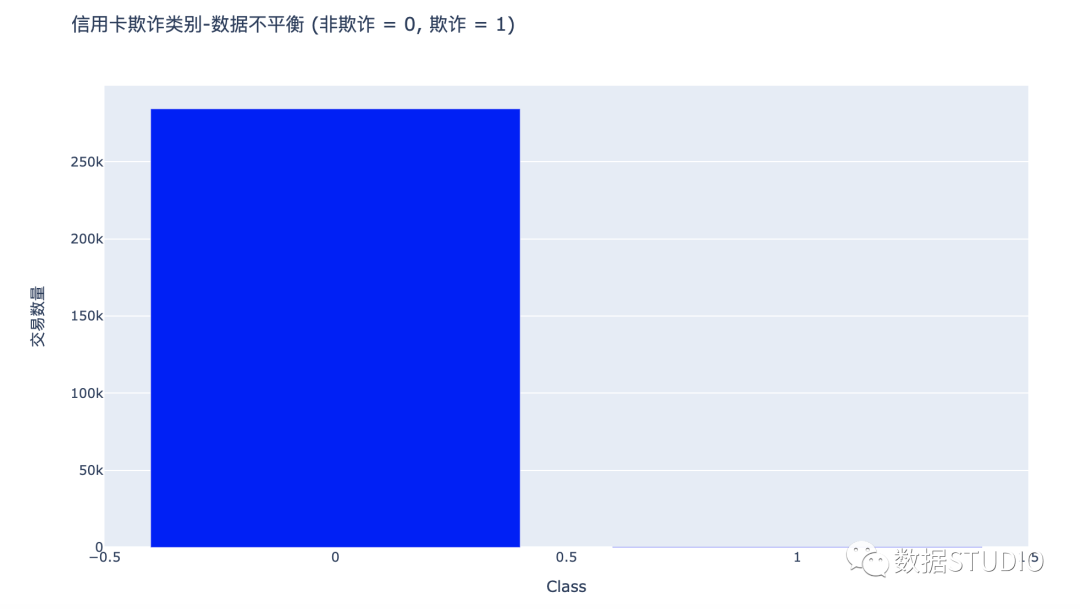
数据不平衡
利用plotly可视化信用卡欺诈类别,得到类别Class数据不平衡。
import plotly.graph_objs as go
from plotly.offline import iplot
temp = dat["Class"].value_counts()
df = pd.DataFrame({'Class': temp.index,'values': temp.values})
trace = go.Bar(
x = df['Class'],y = df['values'],
name="信用卡欺诈类别-数据不平衡 \n(非欺诈 = 0, 欺诈 = 1)",
marker=dict(color="Blue"),
text=df['values'])
temp_data = [trace]
layout = dict(title = '信用卡欺诈类别-数据不平衡 (非欺诈 = 0, 欺诈 = 1)',
xaxis = dict(title = 'Class', showticklabels=True),
yaxis = dict(title = '交易数量'),
hovermode = 'closest',width=1000, height=600)
fig = dict(data=temp_data, layout=layout)
iplot(fig, filename='class')
类别Class随时间Time的分布
amt99 = 1018
# 99%的交易
dat99 = dat.iloc[ list(dat['Amount']<=amt99) ]
# 1%的交易
dat01 = dat.iloc[ list(dat['Amount']>amt99) ]
class_0 = dat99.loc[dat['Class'] == 0]["Time"]
class_1 = dat99.loc[dat['Class'] == 1]["Time"]
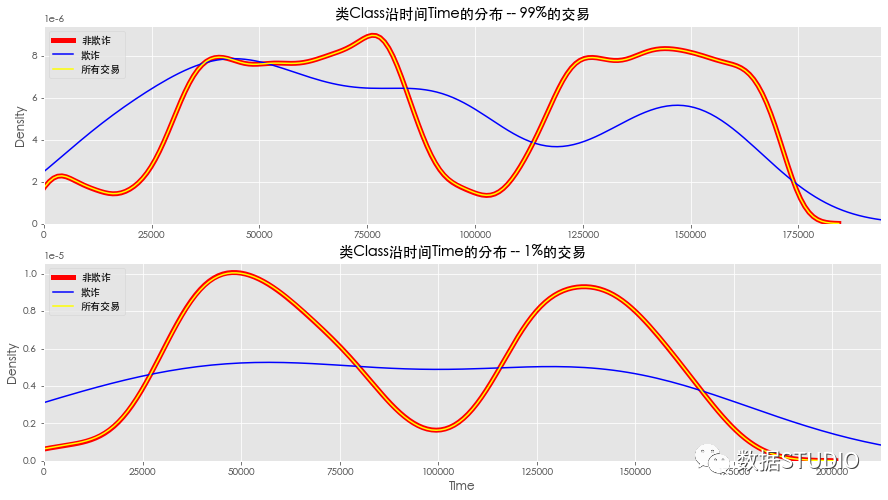
上图可以得到如下结果
- 欺诈交易和非欺诈交易的数据分布是不同的。
- 非欺诈交易分布和所有交易的总和分布使相同的,因为诈骗的案例很少,影响不了总体交易分布。
- 该数据集有两天的数据,所以它显示了正常交易的两个高峰。
- 但无法从两天的数据中识别出任何显著的欺诈交易模式。
类别Class随数量Amount的分布
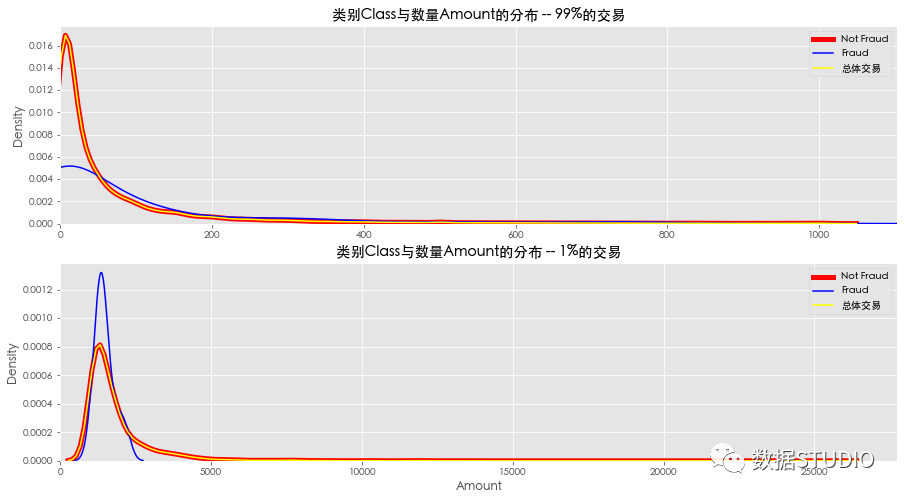
上图可以得到如下结果
- 欺诈交易和非欺诈交易的数据分布是不同的。
- 非欺诈交易分布和所有交易的总和分布使相同的,因为诈骗的案例很少,影响不了总体交易分布。
- 在99%的情况下,看到大多数交易都低于200美元,在1%的情况下,看到一个右尾钟形曲线,平均在3000美元左右。
- 在这1%的数据中,看到了欺诈交易的激增。
交易价值欺诈分析
max_amount=int(round(max(dat.Amount) *1.04,-3))
bins=list(range(0,1601,100))
bins.append(max_amount)
dat['Amt']=pd.cut(dat.Amount,bins)
all_trans = dat.pivot_table(index="Amt",columns="Class",values="V1",aggfunc=len)
all_trans['All'] = all_trans[0] +all_trans[1]
all_trans = all_trans.drop( 0, axis=1)
all_trans.columns=['欺诈','总体']
all_trans['欺诈 %'] = all_trans['欺诈'] / len( dat[dat.Class==1])*100
all_trans['总体 %'] = all_trans['总体'] / len( dat.Class)*100
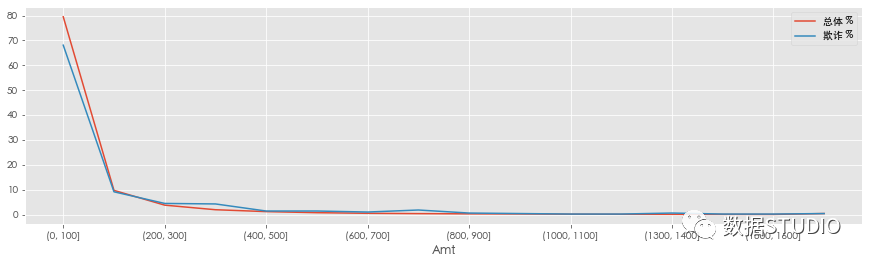
上图可以得到如下结果
- 79.5%的交易低于100美元,但这类欺诈占68%。
- 在200美元到1600美元之间的交易占9.57%,欺诈占16.86%
热图看变量间相关性
sns.heatmap(dat.corr(), cmap="YlGnBu")
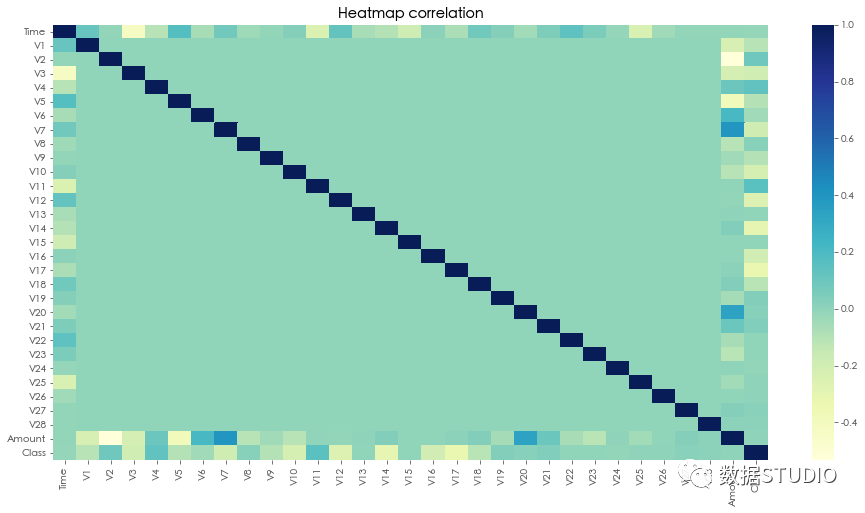
从结果看没有发现变量之间有任何显著的相关性,因此这是PCA降维后的数据,所以给定变量之间没有关系。除了时间和数量与其他字段有某种关系。
指定变量与两个Class的数据点箱图分布
通过多子图,循环绘制每个变量与类之间的箱图,sns.boxplot()可以直接绘制该图形。
color = sns.color_palette("Set3", 6)
plt.figure(figsize=(20,20))
i=1
for col in dat.columns:
plt.subplot(8,4,i)
ax=sns.boxplot(x=dat['Class'],y=dat[col], palette=color)
for p in ax.patches:
ax.annotate(format(p.get_height(), '.2f'),
(p.get_x() + p.get_width() / 2.,
p.get_height()), ha = 'center', va = 'center',
fontsize=8,
xytext = (0, 10), textcoords = '离群点')
i+=1
plt.tight_layout()
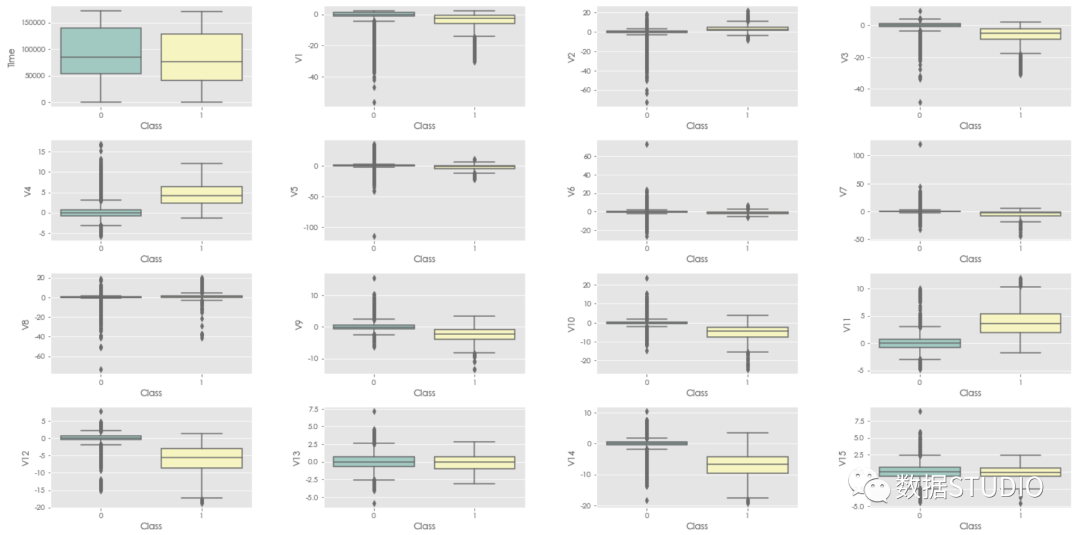 ▲ 部分截图
▲ 部分截图上图可以得到如下结果
- 几乎所有字段都有离群值。
- 对于所有变量,这两个类的数据中值几乎是相同的。
- 对于一些变量,如v1, v4, v5, v12, v14,v16, v17, v18, IQR范围有显著不同。
散点图观察两个Calss的数量与其他变量之间的关系
这主要用sns.regplot()函数
plt.figure(figsize=(20,80))
i=1
for col in dat.columns:
plt.subplot(16,2,i)
sns.regplot(y=dat[dat.Class==0].Amount,
x=dat[dat.Class==0][col], color="g")
ax = sns.regplot(y=dat[dat.Class==1].Amount,
x=dat[dat.Class==1][col], color="r")
ax.tick_params(labelsize=15)
ax.set_xlabel(col,fontsize=15)
i+=1
plt.tight_layout()
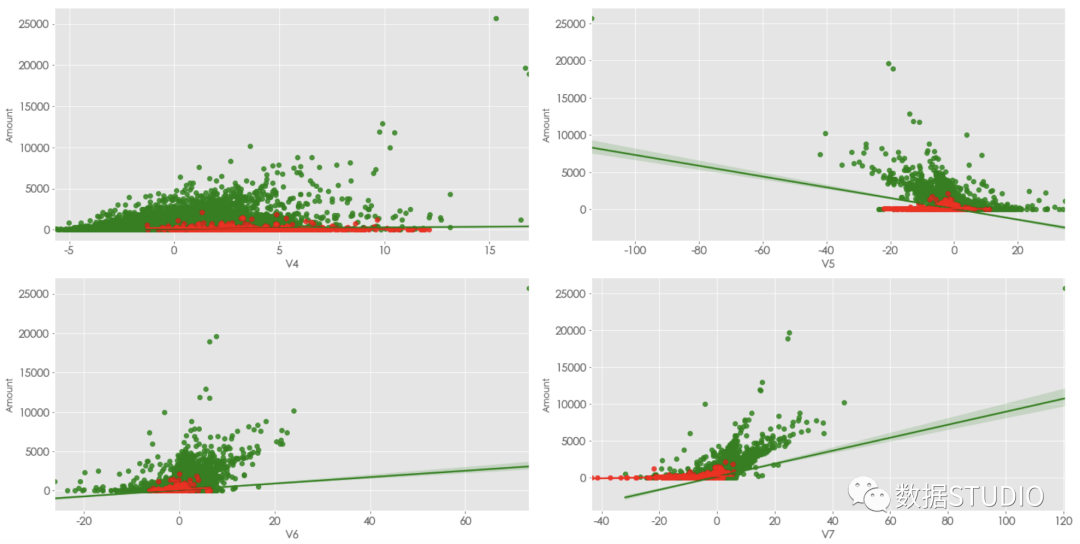 ▲ 部分截图
▲ 部分截图统计检验探索数据特征
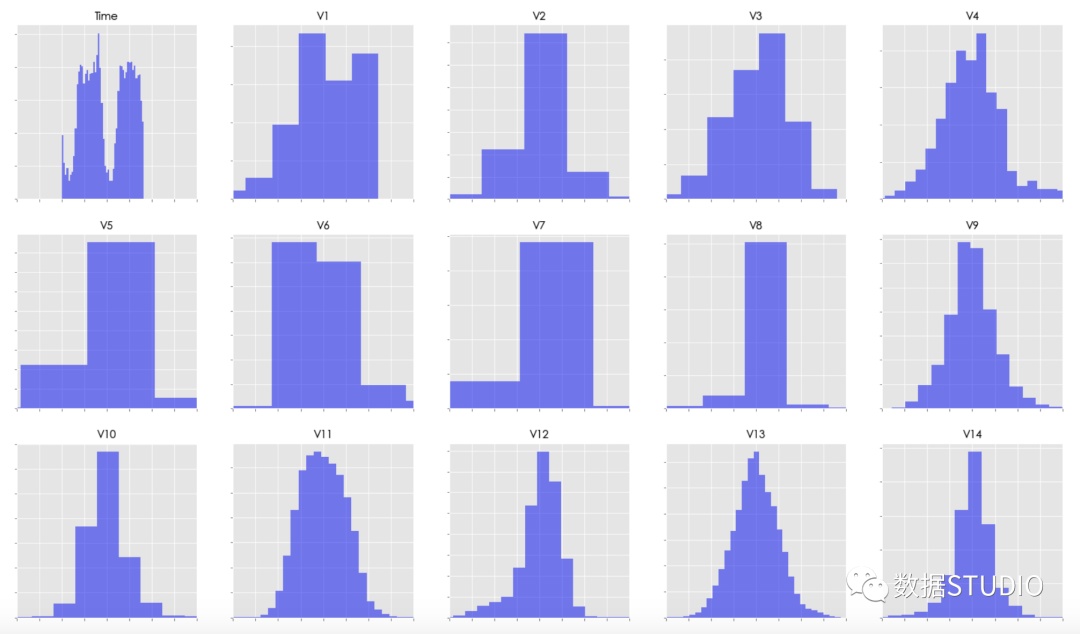
尽管大多数变量的含义是未知的(V1-V28汇总交易数据的因子),但我们知道V1-V28是通过标准化(均值为0,标准差为1)处理过后的数据。当然时间和数量变量同样也是经过标准化处理后的。
经数据探索,特别是采用韦尔奇t检验检验,结果显示几乎所有的特征都与Class变量显著相关。这些变量的均值在Class 0 中几乎为零,而在Class 1 中显然是非零的。
另外时间和数量变量也很重要。似乎还没有任何理由需要进行变量选择。
另外发现一些变量分布不均(如Amount),在XGBoost对这种偏离常态的偏差并不敏感,但如果需要应用一些其他方法(如逻辑回归),这里需用一些特征转换的技巧,如分箱等。
from scipy import stats
from sklearn import preprocessing
dat['Time'] = preprocessing.scale(dat['Time'])
dat['Amount'] = preprocessing.scale(dat['Amount'])
pt = pd.pivot_table(dat, values=dat.columns, columns = 'Class', aggfunc='mean')
print('\n韦尔奇t检验和形状统计的p值:\n')
for i in range(30):
col_name = dat.columns[i]
t, p_val = stats.ttest_ind(dat.loc[ dat['Class']==0, col_name],
dat.loc[ dat['Class']==1, col_name],equal_var=False)
skewness = dat.loc[:,col_name].skew()
kurtosis = stats.kurtosis(dat.loc[:,col_name])
print('Variable: {:7s}'.format(col_name),end='')
print('p-value: {:6.3f} skewness: {:6.3f} kurtosis: {:6.3f}'.format(p_val, skewness, kurtosis))
for i in range(30):
axes[i].hist(dat[dat.columns[i]], bins=50,facecolor='b',alpha=0.5)
韦尔奇t检验和形状统计的p值:
Variable: Time p-value: 0.000 skewness: -0.036 kurtosis: -1.294
Variable: V1 p-value: 0.000 skewness: -3.281 kurtosis: 32.486
Variable: V2 p-value: 0.000 skewness: -4.625 kurtosis: 95.771
Variable: V3 p-value: 0.000 skewness: -2.240 kurtosis: 26.619
...
Variable: Amount p-value: 0.004 skewness: 16.978 kurtosis: 845.078
 ▲ 部分截图
▲ 部分截图划分数据集
这里将数据集划分为40%的训练、30%的验证和30%的测试。注意使用了numpy中的random.shuffle()函数。还使相应的矩阵train, valid和test分别包含只有标签为trainY, validity 和testY的预测器。
Class = dat['Class'].values
allIndices = np.arange(len(Class))
np.random.shuffle(allIndices) # 打乱观察的索引
numTrain = int(round(0.40*len(Class)))
numValid = int(round(0.30*len(Class)))
numTest = len(Class)-numTrain-numValid
inTrain = allIndices[:numTrain]
inValid = allIndices[numTrain:(numTrain+numValid)]
inTest = allIndices[(numTrain+numValid):]
train = dat.iloc[inTrain,:30]
valid= dat.iloc[inValid,:30]
test = dat.iloc[inTest,:30]
trainY = Class[inTrain]
validY = Class[inValid]
testY = Class[inTest]
设置搜索参数
Booster准备:固定参数
首先,我们使用xgb.DMatrix()函数以XGBoost所需的格式创建矩阵,为每个数据集传递预测器数据和标签。然后我们设置一些固定的参数。
其中增强迭代的次数(num_rounds)设置为20。通常情况下,该参数会使用更大的数字以使用更多的迭代次数,但在该实验中,为了节约时间,将其设置为20。
用silent=1(无信息)初始化参数字典。因为数据是高度不平衡的,因此设置参数min_child_weight为默认值1。该参数用于进一步分区的子节点中观察值的最小加权数。目标是二元分类,默认评价指标是曲线下面积(AUC),可以定制一个评估函数以实现更高级的模型评价。
另外设置内部随机数种子为一个常量,这样可以获得可重复的结果(但这并不能保证,因为XGBoost是在线程中运行的。
将使用启发式搜索中的参数来扩展参数字典。
import xgboost as xgb
# 将数据转换为xgboost所需的矩阵
dtrain = xgb.DMatrix(train, label=trainY)
dvalid = xgb.DMatrix(valid, label=validY)
dtest = xgb.DMatrix(test, label=testY)
# 固定一些参数
# boosting迭代数
num_rounds=20
param = {'silent':1,
'min_child_weight':1,
'objective':'binary:logistic',
'eval_metric':'auc',
'seed' : 1234}
Booster准备:可变参数
在接下来的内容中,参考了下面几个文章的建议:
- The official XGBoost documentation[5] 和 Notes on Parameter Tuning[6]
- The article "Complete Guide to Parameter Tuning in XGBoost" from Analytics Vidhya[7]
- Another Slideshare presentation with title "Open Source Tools & Data Science Competitions"[8]
以下为启发式搜索选择几个重要参数:
- max_depth
树的最大深度,范围在[1,∞]中,默认值为6。这是高度依赖数据的。[2]中选用3-10作为典型值。[3]中建议从6开始。而我们选择探索更大的max_depth值,并从5-25,设置步长为5,共5步。 - subsample
参数范围 (0,1] ,默认值为1。这是在树中使用的训练实例的比例,使用较小的值可以防止过拟合。[2]中建议的值为0.5-1。[3]中建议这个值保持为1。我们决定以0.1为步长,测试0.5-1.0中的值。 - colsample_bytree
参数范围 (0,1] ,默认值为1。 这是用于构建树的列(特征)的子样本比率。[2]中建议的值为0.5-1。[3]中建议是0.3-0.5。我们将尝试与参数subsample相似的值。 - eta (or learning_rate)
参数范围[0,1]中,默认值为0.3。特征权重的缩小率和较大的学习率值(但不是太高)可以用来防止过拟合。[2]中建议使用0.01-0.2中的值。我们可以在[0.01,0.4]中选择一些值。 - gamma
范围 [0, ∞], 默认值为0。这是树分裂所需的最小损失函数减少值。[3]中建议这个保持使用默认值0。我们可以在0.05的步长中测试0-2的值。 - scale_pos_weight
默认值1,控制正样本和负样本权重的平衡。[1]中建议是使用正负样本的比率是595,也就是说,给阳性的一个较大的权重。[2]中同样表示在高阶级不平衡的情况下,改参数值需要设置很大。我们可以既尝试一些较小值也尝试一些较大值。
上面所有参数的所有可能组合的总数可高达43200,我们只测试其中的一小部分,约100个,即与启发式搜索迭代的次数相同。
我们还初始化一个DataFrame并将其结果保存以供以后检查。
from collections import OrderedDict
ratio_neg_to_pos = sum(trainY==0)/sum(trainY==1)
print('负与正实例的比率: {:6.1f}'.format(ratio_neg_to_pos))
# 需要调节的参数
tune_dic = OrderedDict()
tune_dic['max_depth']= [5,10,15,20,25] # 树的最大深度
tune_dic['subsample']=[0.5,0.6,0.7,0.8,0.9,1.0] # 在树中使用的训练实例的比例
tune_dic['colsample_bytree']= [0.5,0.6,0.7,0.8,0.9,1.0] # 列(特征)的子样本比率
tune_dic['eta']= [0.01,0.05,0.10,0.20,0.30,0.40] # 学习率
tune_dic['gamma']= [0.00,0.05,0.10,0.15,0.20] # 分裂所需的最小损失函数减少值
tune_dic['scale_pos_weight']=[30,40,50,300,400,500,600,700] # 正面/负面实例的相对权重
lengths = [len(lst) for lst in tune_dic.values()]
combs=1
for i in range(len(lengths)):
combs *= lengths[i]
print('所有组合总数: {:16d}'.format(combs))
maxiter=100
columns=[*tune_dic.keys()]+['F-Score','Best F-Score']
results = pd.DataFrame(index=range(maxiter), columns=columns) # dataframe保存训练结果
负与正实例的比率: 580.2
所有组合总数: 43200
自定义函数
构建训练和评价模型的函数
接下来定义两个函数:
函数 perf_measures() 接受必须参数preds和labels,及可选参数print_conf_matrix,并返回F-Score(精确度和召回率的调和平均值),将用于启发式搜索。
函数 do_train() 接受如下参数:
- 当前选择的变量参数的字典 (cur_choice),
- 要传递给XGBoost训练主程序的完整参数字典 (param),
- 一个XGBoost格式的训练数据集 (train),
- 一个字符串标识符 (train_s),
- 样本标签 (trainY),
- 验证数据集的相应参数 (valid, valid_s, validY),
- 以及是否打印混淆矩阵的选项 (print_conf_matrix).
然后训练模型,并将验证数据集上预测得到的F-Score与模型一起返回。对主训练程序xgb.train()的调用有以下参数:
- 完整参数字典 (param),
- 一个XGBoost格式的训练数据集 (train),
- boosting迭代次数 (num_boost),
def perf_measures(preds, labels, print_conf_matrix=False):
act_pos=sum(labels==1) # 实际正样本数
act_neg=len(labels) - act_pos # 实际负样本数
pred_pos=sum(1 for i in range(len(preds)) if (preds[i]>=0.5)) # 预测真样本数
true_pos=sum(1 for i in range(len(preds)) if (preds[i]>=0.5) & (labels[i]==1)) ## 预测负样本数
false_pos=pred_pos - true_pos # 假正数
false_neg=act_pos-true_pos # 假负数
true_neg=act_neg-false_pos # 正负数
precision = true_pos/pred_pos ## tp/(tp+fp) 预测为正样本数中正确分类的百分比
recall = true_pos/act_pos ## tp/(tp+fn) 正确分类的正样本百分比
f_score = 2*precision*recall/(precision+recall)
if print_conf_matrix:
print('\n混淆矩阵')
print('----------------')
print( 'tn:{:6d} fp:{:6d}'.format(true_neg,false_pos))
print( 'fn:{:6d} tp:{:6d}'.format(false_neg,true_pos))
return(f_score)
def do_train(cur_choice, param, train,train_s,trainY,valid,valid_s,validY,print_conf_matrix=False):
"""
使用给定的固定和可变参数进行训练,并报告验证数据集上的F-score
"""
print('参数:')
for (key,value) in cur_choice.items():
print(key,': ',value,' ',end='')
param[key]=value
print('\n')
# 下面注释掉的部分使用一个观察列表来监控推进迭代的进程
# evallist = [(train,train_s), (valid,valid_s)]
# model = xgb.train( param, train, num_boost_round=num_rounds,
# evals=evallist,verbose_eval=False)
model = xgb.train( param, train, num_boost_round=num_rounds)
preds = model.predict(valid)
labels = valid.get_label()
f_score = perf_measures(preds, labels,print_conf_matrix)
return(f_score, model)
产生参数随机相邻组合
接下来定义一个函数next_choice(),如果当前参数没有通过cur_params传递时,它可以生成变量参数的随机组合,或者生成通过cur_params传递的参数的相邻组合。
在第二种情况下,首先随机选择一个要更改的参数。然后:
- 如果该参数是当前最小的值,则选择下一个(更大)的值。
- 如果该参数是当前最大的值,则选择前一个(较小)的值。
- 否则,随机选择左(小)或右(大)值。
这使得在执行启发式搜索的函数中避免了重复。
def next_choice(cur_params=None):
"""
返回变量参数的随机组合(如果cur_params=None)或cur_params的随机相邻组合
"""
if cur_params:
# 选择要更改的参数
# 参数名称和当前值
choose_param_name, cur_value = random.choice(list(cur_choice.items())) # 参数名称
all_values = list(tune_dic[choose_param_name]) # 所选参数的所有值
cur_index = all_values.index(cur_value) # 选定参数的当前索引
if cur_index==0:
# 如果它是范围中的第一个,则选择第二个
next_index=1
elif cur_index==len(all_values)-1:
# 如果它是范围中的最后一个,则选择前一个
next_index=len(all_values)-2
else:
# 否则随机选择左或右值
direction=np.random.choice([-1,1])
next_index=cur_index + direction
next_params = dict((k,v) for k,v in cur_params.items())
next_params[choose_param_name] = all_values[next_index]
# 更改所选参数的值
print('参数的选择移动到: {:10s}: from {:6.2f} to {:6.2f}'.
format(choose_param_name, cur_value, all_values[next_index] ))
else:
# 生成参数的随机组合
next_params=dict()
for i in range(len(tune_dic)):
key = [*tune_dic.keys()][i]
values = [*tune_dic.values()][i]
next_params[key] = np.random.choice(values)
return(next_params)
模拟退火算法的应用
在模拟退火算法的每一次迭代中,选择一个超参数组合。利用这些参数对XGBoost算法进行训练,得到验证集上的F-score 。
- 如果这个 F-score比前一次迭代的 F-score更好(更大),即是“局部”改进,则该组合被接受,并设置为当前组合,通过调用next_choice()函数为下一次迭代选择相邻的组合。
- 否则,如果这个F-score 比上一个迭代的更差(更小),并且梯度下降为 ,则接受该组合作为具有 概率的当前组合,其中 是一个常数, 是当前的"温度"。 该方法开始时是高温,一开始"坏的"解决方案很容易被接受,此时是希望探索广阔的搜索空间。但随着温度下降,不好的解决方案被接受的可能性降低,此时搜索变得更加集中。
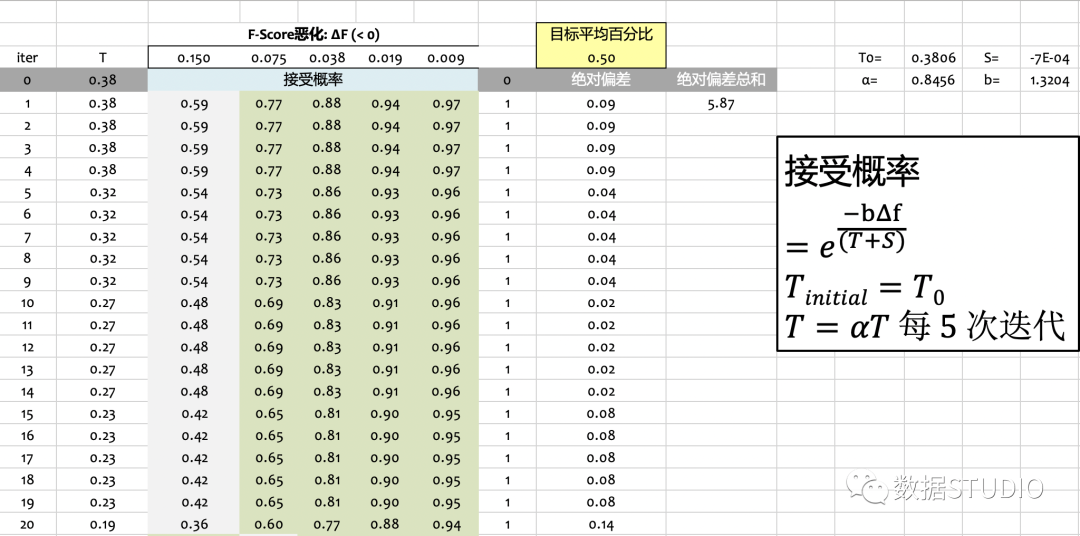
温度从一个固定的值T0开始,每n次迭代就减少一个因子 alpha < 1。这里T0 = 0.40, n=5, alpha = 0.85。常数beta=1.3。
这个"冷却计划"的参数选择可以很容易地在Excel中完成。在这个例子中,我们选择F-Score恶化的平均接受概率为 0.150,0.075,0.038,0.019,0.009,即初始值是0.150,公比1/2。我们将这些平均概率设置为50%左右在第1,第2,…,第5次的20次迭代,并使用Excel求解器寻找合适的参数。
 ▲ 部分截图
▲ 部分截图这里可以使用简单的哈希方案可以避免重复。
一个警示:如果迭代的次数不足够,即小于组合的总数,此时可能出现太多的重复和延迟。这里实现的生成组合的简单方法并没有解决这种情况。
import time
t0 = time.clock()
T=0.40
best_params = dict() # 初始化字典用以保存最佳参数
best_f_score = -1. # 初始化最佳F-score
prev_f_score = -1. # 初始化先前的F-score
prev_choice = None # 初始化先前选择的参数
weights = list(map(lambda x: 10**x, [0,1,2,3,4])) # 哈希函数的权值
hash_values=set()
for iter in range(maxiter):
print('\nIteration = {:5d} T = {:12.6f}'.format(iter,T))
# 找到以前没有访问过的参数的下一个选择
while True:
# 第一个选择或选择prev_choice的邻居
cur_choice=next_choice(prev_choice)
# 按参数的字母顺序排列的选择索引
indices=[tune_dic[name].index(cur_choice[name]) for name in sorted([*tune_dic.keys()])]
# 检查选择是否已经被访问
hash_val = sum([i*j for (i, j) in zip(weights, indices)])
if hash_val in hash_values:
print('\n再次访问组合 -- 再次搜索')
# tmp=abs(results.loc[:,[*cur_choice.keys()]] - list(cur_choice.values()))
# tmp=tmp.sum(axis=1)
# if any(tmp==0): ## selection has already been visited
# print('\n再次访问组合 -- 再次搜索')
else:
hash_values.add(hash_val)
break # 跳出while循环
# 训练模型并在验证数据集上获得F-score
f_score,model=do_train(cur_choice, param, dtrain,'train',trainY,dvalid,'valid',validY)
# 存储参数
results.loc[iter,[*cur_choice.keys()]]=list(cur_choice.values())
print('F-Score: {:6.2f} 先前值: {:6.2f} 目前最佳值: {:6.2f}'.format(f_score, prev_f_score, best_f_score))
if f_score > prev_f_score:
print('局部改进')
# 接受这个组合作为新的起点
prev_f_score = f_score
prev_choice = cur_choice
# 如果F-score全局较好,则更新最佳参数
if f_score > best_f_score:
best_f_score = f_score
print('全局改进 - 最佳F-score已更新')
for (key,value) in prev_choice.items():
best_params[key]=value
else: ## F-score比先前值小
## 接受这个组合作为新的概率起点 exp(-(1.6 x f-score 下降)/温度)
rnd = random.random()
diff = f_score-prev_f_score
thres=np.exp(1.3*diff/T)
if rnd <= thres:
print('更糟糕的结果。 F-Score 变化: {:8.4f} 阈值: {:6.4f} 随机数: {:6.4f} -> 已接受'.
format(diff, thres, rnd))
prev_f_score = f_score
prev_choice = cur_choice
else:
# 不更新以前的F-score和以前选择的参数
print('更糟糕的结果。 F-Score 变化: {:8.4f} 阈值: {:6.4f} 随机数: {:6.4f} -> 已拒绝'.
format(diff, thres, rnd))
# 存储结果
results.loc[iter,'F-Score']=f_score
results.loc[iter,'最佳F-Score']=best_f_score
if iter % 5 == 0: T=0.85*T # 每5次迭代降低温度并继续
print('\n{:6.1f} 分钟处理时间\n'.format((time.clock() - t0)/60))
print('找到最佳变量参数:\n')
print(best_params)
Iteration = 0 T = 0.400000
参数:
eta : 0.05 colsample_bytree : 0.9
scale_pos_weight : 300 gamma : 0.2
max_depth : 20 subsample : 0.5
F-Score: 0.80 先前值: -1.00 目前最佳值: -1.00
局部改进
全局改进 - 最佳F-score已更新
...
19.2 分钟处理时间
找到最佳变量参数:
{'eta': 0.4, 'colsample_bytree': 1.0,
'scale_pos_weight': 50, 'gamma': 0.1,
'max_depth': 15, 'subsample': 0.5}
对测试数据集的评估
对测试数据集的评估结果为F-Score=0.86该结果还可以,因为需要考虑到Class的高度不平衡性。
最好的超参数是在预期良好的范围内。后期可以继续优化:
- 缩小超参数的范围。
- 或许可以添加其他这里没有使用的参数(例如,正则化参数)。
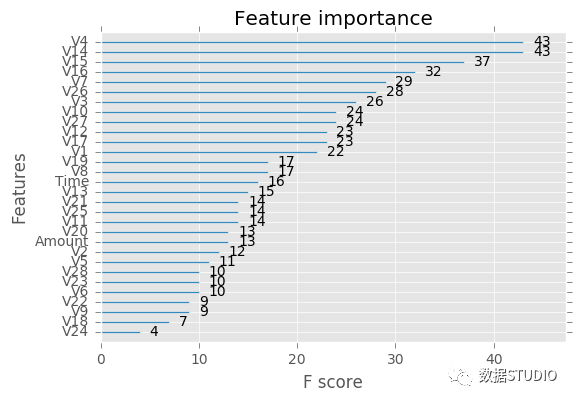
- 获取可以在变量重要性信息的基础上进行变量选择。
- 重要的是,与集成类似,可以将不同的模型组合起来。
print('\n找到的最佳参数:\n')
print(best_params)
print('\n对测试数据集的评估\n')
best_f_score,best_model=do_train(best_params, param, dtrain,'train',trainY,dtest,'test',testY,print_conf_matrix=True)
print('\n测试数据集上的F-score: {:6.2f}'.format(best_f_score))
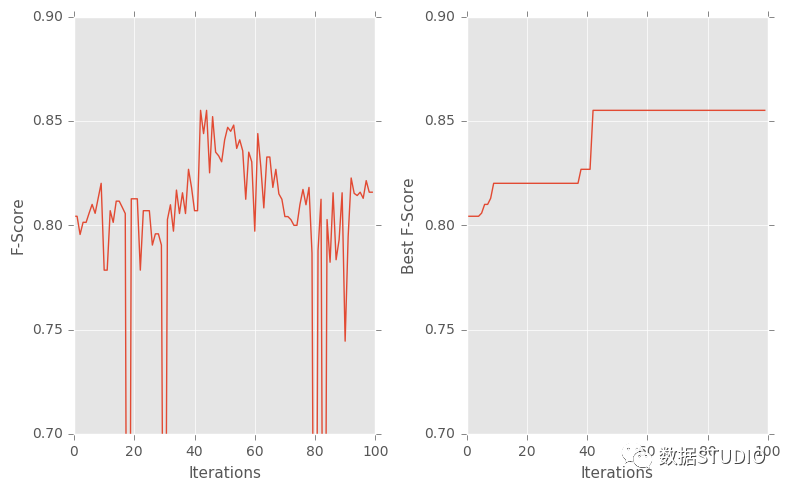
f, (ax1,ax2) = plt.subplots(nrows=1, ncols=2, sharey=False, figsize=(8,5))
ax1.plot(results['F-Score'])
ax2.plot(results['Best F-Score'])
ax1.set_xlabel('Iterations',fontsize=11)
ax2.set_xlabel('Iterations',fontsize=11)
ax1.set_ylabel('F-Score',fontsize=11)
ax2.set_ylabel('Best F-Score',fontsize=11)
ax1.set_ylim([0.7,0.9])
ax2.set_ylim([0.7,0.9])
plt.tight_layout()
plt.show()
print('\n特征重要性:\n')
p = xgb.plot_importance(best_model)
plt.show()
找到的最佳参数:
{'eta': 0.4, 'colsample_bytree': 1.0,
'scale_pos_weight': 50, 'gamma': 0.1,
'max_depth': 15, 'subsample': 0.5}
对测试数据集的评估
Parameters:
eta : 0.4 colsample_bytree : 1.0
scale_pos_weight : 50 gamma : 0.1
max_depth : 15 subsample : 0.5
混淆矩阵
----------------
tn: 85265 fp: 18
fn: 25 tp: 134
测试数据集上的F-score:0.86
特征重要性
参考资料
[1]模拟退火: https://en.wikipedia.org/wiki/Simulated_annealing
[2]启发式搜索: https://github.com/KSpiliop/Fraud_Detection
[3]Slideshare presentation: https://www.slideshare.net/ShangxuanZhang/kaggle-winning-solution-xgboost-algorithm-let-us-learn-from-its-author
[4]不平衡分类的欠采样概率校准: http://www.oliviercaelen.be/doc/SSCI_calib_final.pdf
[5]Official XGBoost Guide: http://xgboost.readthedocs.io/en/latest/parameter.html
[6]Notes on Parameter Tuning: http://xgboost.readthedocs.io/en/latest/how_to/param_tuning.html
[7]Analytics Vidhya: https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
[8]Second Slideshare presentation: https://www.slideshare.net/odsc/owen-zhangopen-sourcetoolsanddscompetitions1
相关阅读: