谷歌大脑新论文:一种新并行训练方法,可提高训练速度
共 2742字,需浏览 6分钟
· 2020-12-16

大数据文摘授权转载自安迪的写作间
Google Brain 的 Peter Abbeel 发了一篇新论文,Parallel Training of Deep Networks with Local Updates,主要是对并行训练中一种新的并行方式:Local Parallesim, 进行大量实验和对比。
论文地址:
论文发现 Local Parallesim 可在大规模并行运算时,如果对性能要求弱的情况下,加快训练速度。
并行方法回顾
首先,简单回顾一下,目前大概有哪些并行训练方法。
了解并行训练,或用做过一些并行训练的话也都知道,比如什么是模型并行(Model Parallesim),什么是数据并行(Data Parallesim)。再深一点,用过 Gpipe 之类工具的,也会知道管道并行(Pipeline Parallesim)。
数据并行:简单说就是,将一大块数据切成小份,分发给几个完全相同模型,分别训练,之后聚合梯度。再细点,可分同步和异步。

模型并行:简单来说,模型太大,一张卡放不下,要放到多张卡上去。所以也导致模型并行一些问题,比如很大的通讯开支,计算利用率不高。看下面这张图就明白了。

可以看到,对于每个计算单元,都会有大量空闲时间。导致这个的原因是,前项和反向都会有个 Locking(锁) 现象,前向时不能反向,反向时不能做前向,因此就要等,结果等的时候就空闲下来了。
**管道并行:**还没明确定义,感觉主要是通过资源估算,然后调度,来更大效率的利用处理器空闲时间,达到更高计算利用率。大致可认为,通过管道并行可给模型并行里的空洞填起来。

当然这个也有问题,虽然避开了 Locking 的问题,但也就导致了参数的 Staleness 和连贯性问题,会造成训练不稳定。
Local Parallesim:本地并行?
Local Parallesim 的概念很简单,也不是很新,早有人提出类似的方法了,只是没仔细做实验对比。这篇论文就主要是做了多项对比分析,还在多个任务(CV,NLP)上进行测试。
介绍 Local Parallesim 之前,先来说说一般的反向传播训练过程,都很熟悉了
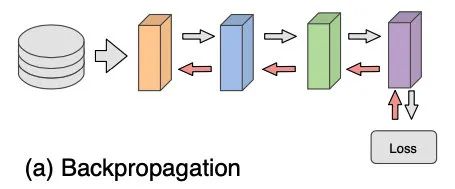
发现因为前项反向是连贯的,才会导致 Locking 现象。
可看到反向传播是在全局做的优化,从最后一层一直传播到开头。而 Local Parallesim 则想通过给反向传播全局过程变成每层本地的过程,来提高并行性。最极端的就是每一层都有个 Loss,而层与层间的反向传播交互完全没了。

这是 Greedy 方案。但这种方案虽然可以带来高并行性,但因为每层都分开计算的,层与层之间没有交流,从而会导致对全局目标的测试集表现差,泛化性也差。
于是就开始取折衷方案,有两种折衷方案。
第一个叫做 Overlapping,如其名,将网络的多个层分成几个块,每个块可能包含多层,而块之间有一些层是重叠的。如下图中表示,模型有四层,但分了三块,块与块之间都会共享一层(相同颜色)。
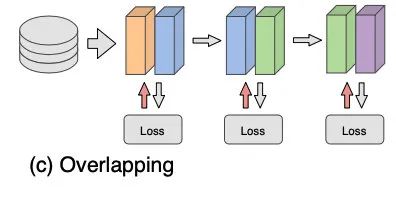
这个方法虽然强行加强了(很不优美)层与层之间的联系,但也因为重叠层需要更新两次,增加了训练的复杂性。
第二个折衷的方法是,文中提出的主要方法 Chunked,如其名,也是给层分块。
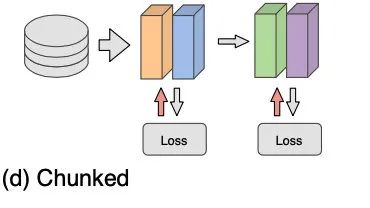
跟 Greedy 的区别是,每个并行训练单位可能是多层,和 Overlapping 的区别是,块与块之间没有 Overlap.
上面方法提到的 Loss,都是相同的,不管是最后一层还是 local 的中间层,比如说之后的 CIFAR 分类任务,都是用一个线性分类器。
实验 and 分析
于是作者们对上面提到的四种训练模式都进行了实验。
为表示通用性,在三个数据集上做了实验,图片分类的 CIFAR-10 和 ImageNet,分别用八层 4096 维的 MLP 模型和 ResNet50,此外在语言模型上做了实验,通过在 LM1B 数据集上训练 Transformer 模型。
实验展现形式是通过在一定训练约束条件下,比如到某个loss或到某个准确度,横轴用训练总时间,然后纵轴用算力花费,来画出 Pareto Frontier 图。Pareto Frontier 就是界限上都是 Pareto 最优。具体概念谷歌。
其实觉得这篇论文的图片展示做的不是很好,看了好几遍才搞明白说的啥,可以感受一下。
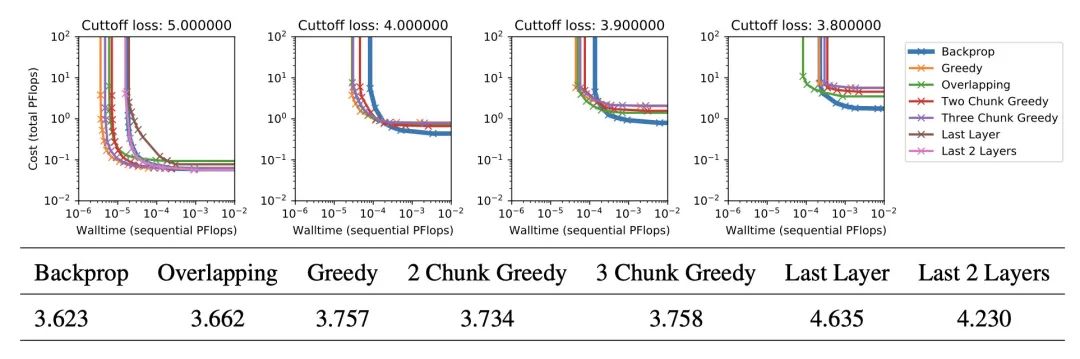
大致结论是,在几个任务上,大算力情况下同时对性能要求不是很高的时候,一般 Local Parallesim 都能取得比一般反向传播快得多的速度。但如果不考虑时间的话,单看训练性能的话,往往最后还是直接反向传播能够获得最好的性能。
实验中效果比较好的 Local Parallesim 的方案是两层放在一起作为一个 Block 的最好(2 Chunk Greedy)
实验结果中感觉还有可以关注的是,Overlapping 在 Transformer 语言模型的表现要比 2 Chunk Greedy 的方案要好,而在 ImageNet 里没这个现象。论文里没有这个进行分析。
之后作者对 Local Parallesim 训练的模型的一些性质还进行了分析。
首先是对每层的梯度和真实梯度的向量角度进行了计算,发现越到下面的层相似性越小。
还有 Block 里层数越多,也就是 Block 越大,泛化性越强,也就是越靠向纯反向传播泛化性越强。
最后将视觉分类任务模型的第一层特征可视化出来,发现 Local Parallesim 的训练越是 Greedy 也就是 Block 大小越小,特征就越和反向传播不同,有更少的边缘检测器。
结论
论文最后给出结论
在速度和性能之间权衡的话,越注重速度就可以越向 Greedy 的 Local Parallesim 靠,注重性能的话还是尽量向反向传播靠 Local Parallesim 可在数据并行饱和的时候,继续进一步增大计算规模 可用于多个任务和架构