
叫板DALL·E 2,预训练大模型做编码器,谷歌把文字转图像模型卷上天

来源:机器之心 本文约3400字,建议阅读8分钟
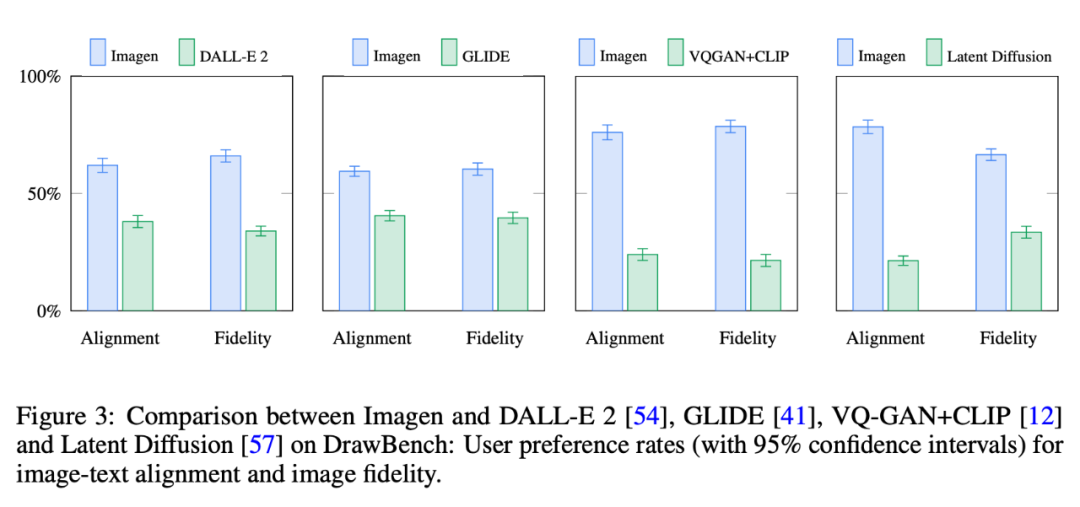
本文介绍了来自谷歌的研究者也在OpenAI做出了探索,提出了一种文本到图像的扩散模型 Imagen。
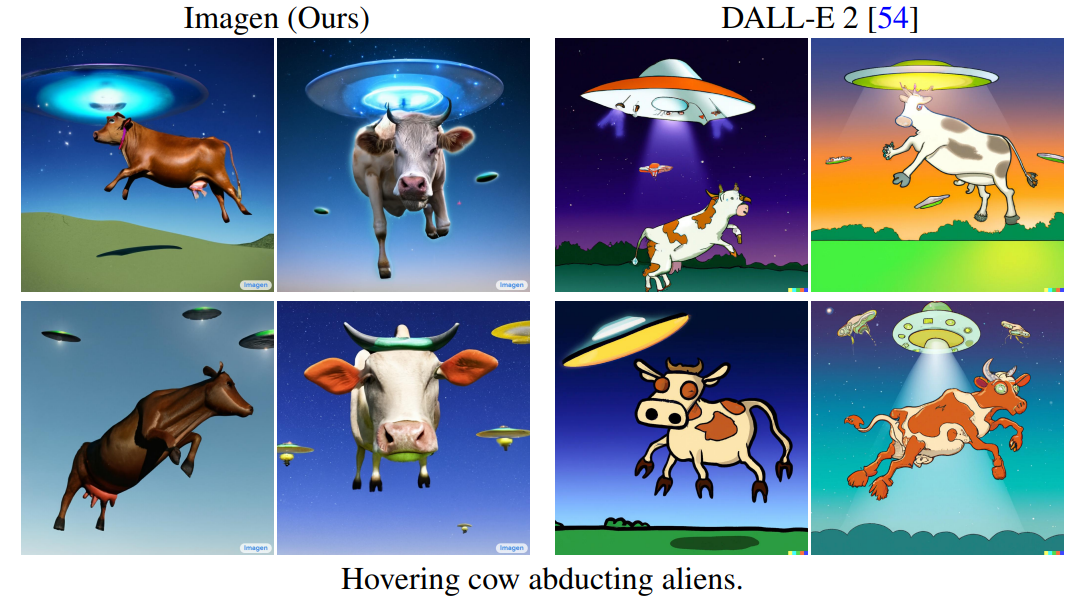
OpenAI:DALL・E 2 就是最好的。谷歌:看下我们 Imagen 生成的柴犬?









论文地址:
https://gweb-research-imagen.appspot.com/paper.pdf
项目地址:
https://github.com/lucidrains/DALLE2-pytorch
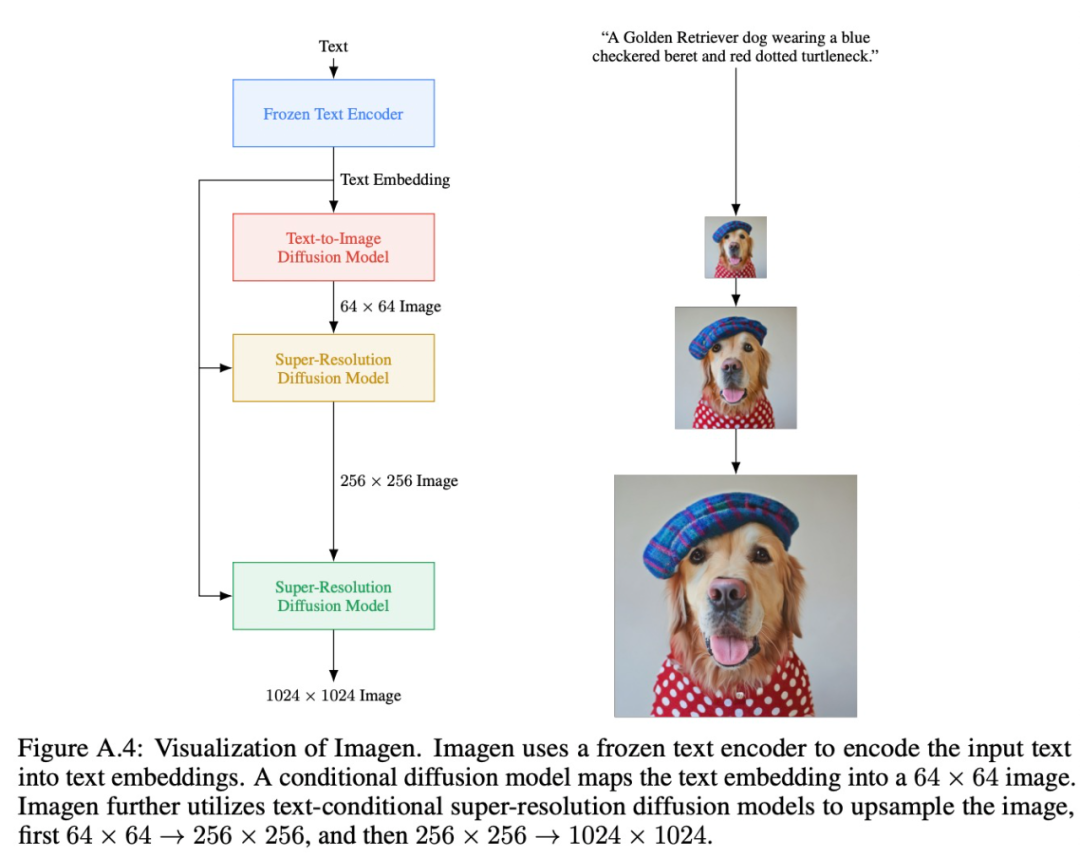
基本模型
超分辨率模型

编辑:王菁 校对:林亦霖
评论