
端智能在大众点评搜索重排序的应用实践

1 引言
2 排序系统进阶:为什么需要端上重排
2.1 云端排序痛点
2.2 端智能重排流程和优势
3 端上重排序算法探索与实践
3.1 特征工程
3.2 用户反馈行为序列建模
3.3 重排模型设计
3.4 多场景应用效果
4 系统架构与部署优化
4.1 系统架构
4.2 端上大规模深度模型部署优化
4.3 端智能模型训练预估平台
5 总结与展望
1 引言
2 排序系统进阶:为什么需要端上重排
2.1 云端排序痛点
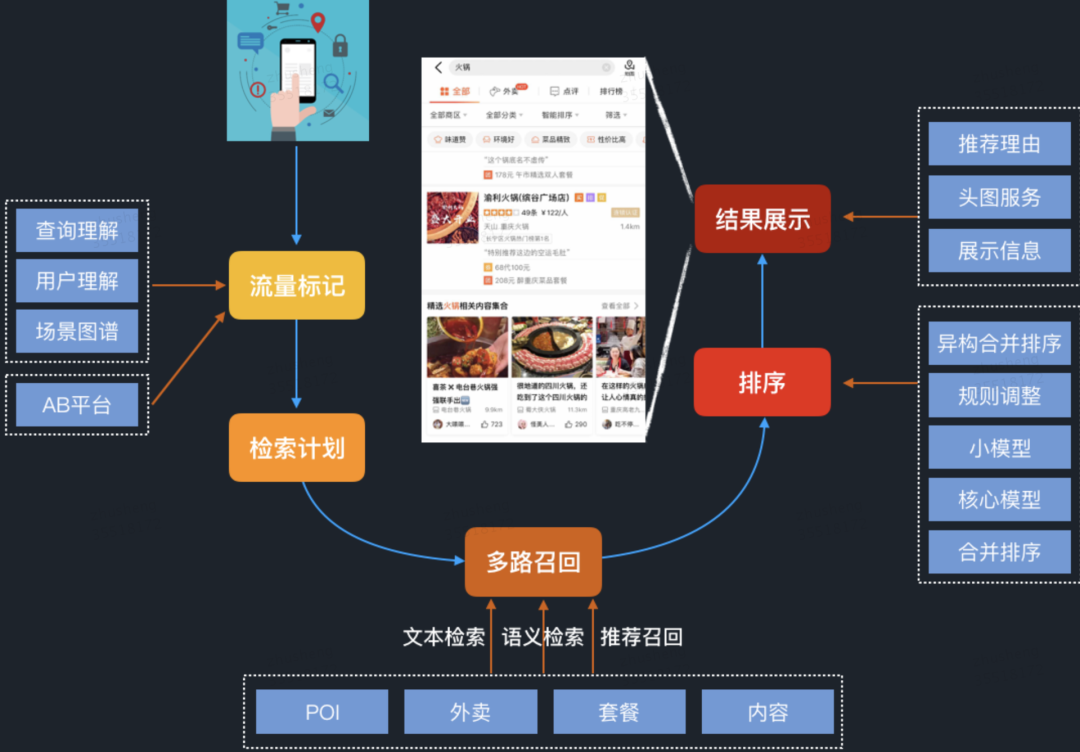
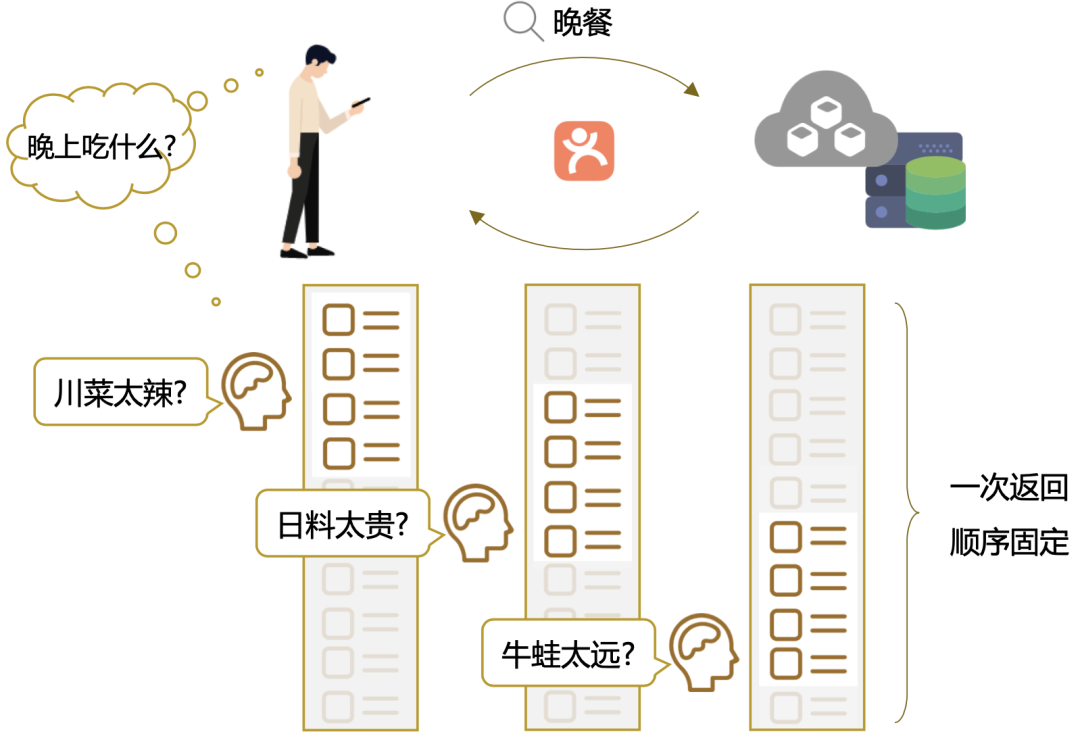
2.2 端智能重排流程和优势
支持页内重排,对用户反馈作出实时决策:不再受限于云端的分页请求更新机制,具备进行本地重排、智能刷新等实时决策的功能。 无延时感知用户实时偏好:无需通过云端的计算平台处理,不存在反馈信号感知延迟问题。 更好的保护用户隐私:大数据时代数据隐私问题越来越受到用户的关注,大众点评 App 也在积极响应监管部门在个人信息保护方面的执行条例,升级个人隐私保护功能,在端上排序可以做到相关数据存放在客户端,更好地保护用户的隐私。
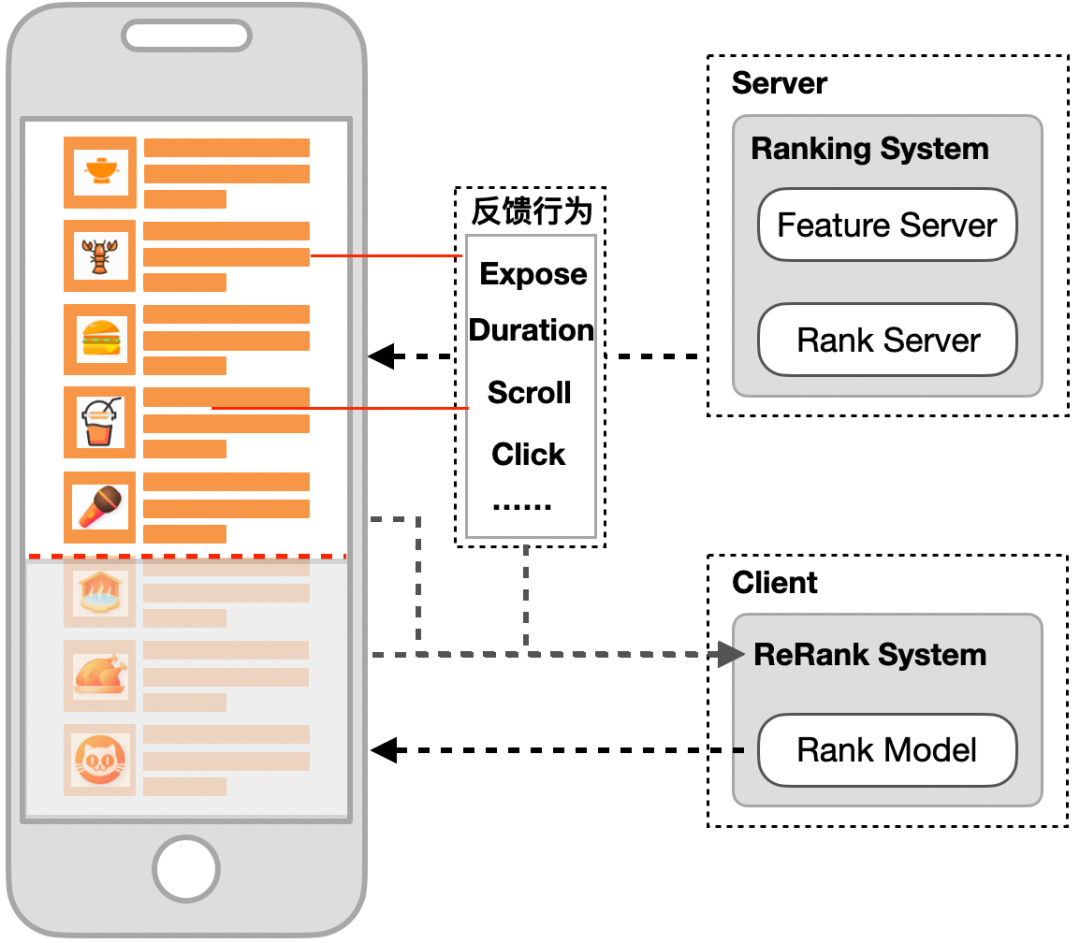
3 端上重排序算法探索与实践
3.1 特征工程
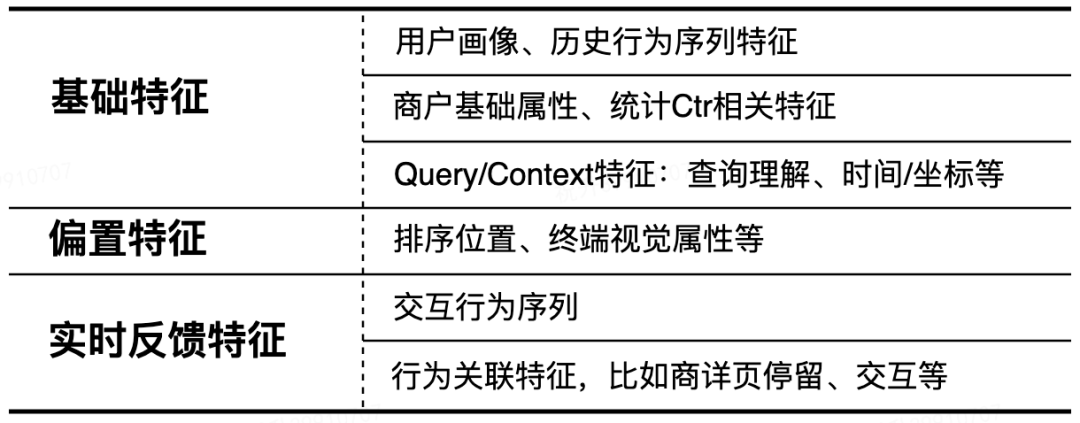
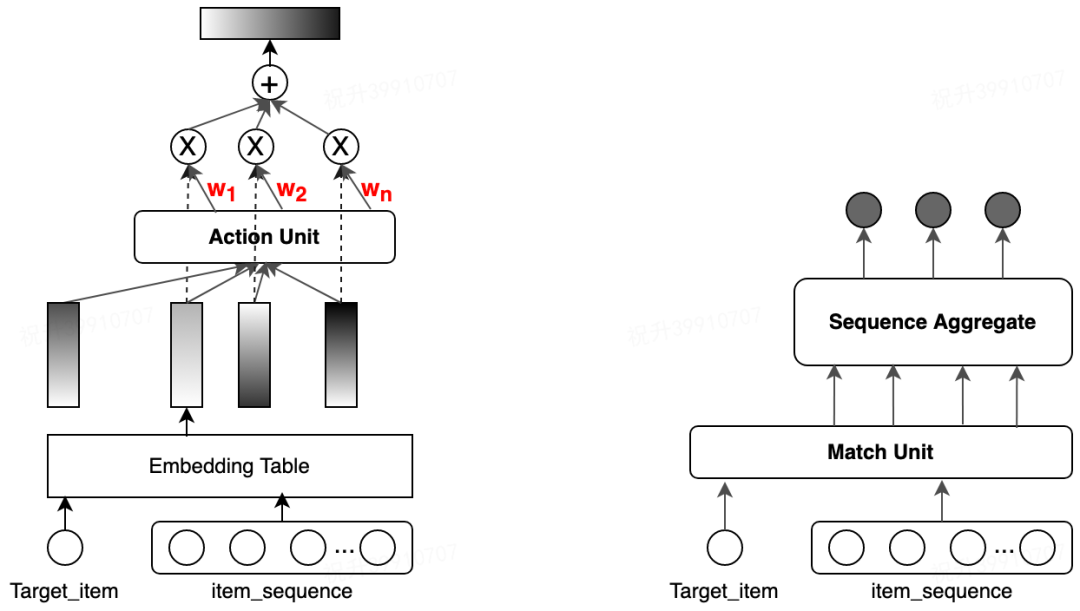
基础特征,典型的用户/商户/Query/Context 侧特征,以及双侧的交叉特征等。 偏置特征,主要包括后端返回的排序位置,终端设备上存在的一些大小等视觉上的偏置。 用户的实时反馈特征,这部分是整个端上重排特征体系的重要组成部分,包括: 用户直接的交互行为序列(曝光、点击等)。 行为关联特征,比如点击进入商户详情页内的停留、交互等相关行为。
3.2 用户反馈行为序列建模
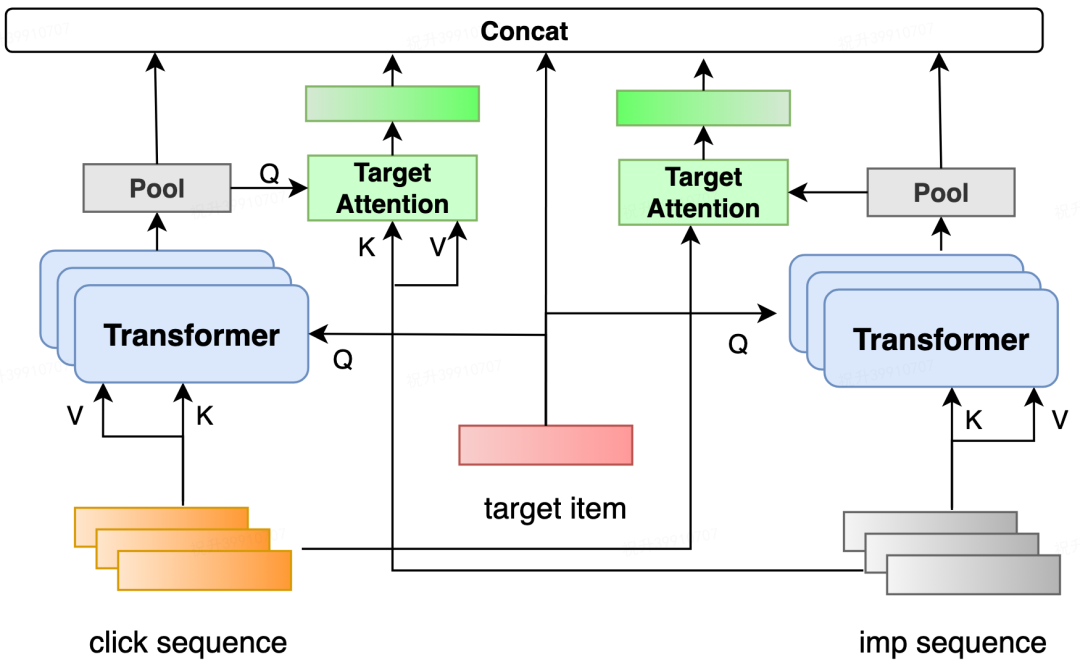
使用待排商户 ID 作为 Q,对实时反馈行为进行激活,表达用户隐形的多样性兴趣。 使用商户更多表现粒度的属性信息作为 Q,激活得到注意力权重,提升用户在这些更显式感知的商户表征上的兴趣表达。 使用当前搜索上下文相关的信号作为 Q,激活得到注意力权重,增强实时反馈行为对于不同上下文环境的自适应地表达。
通过消融对比实验发现,相比于随机初始化的 Multi-Head Attention,这种显式使用多种商户上下文特征的 Transformer 激活方式效果更显著。
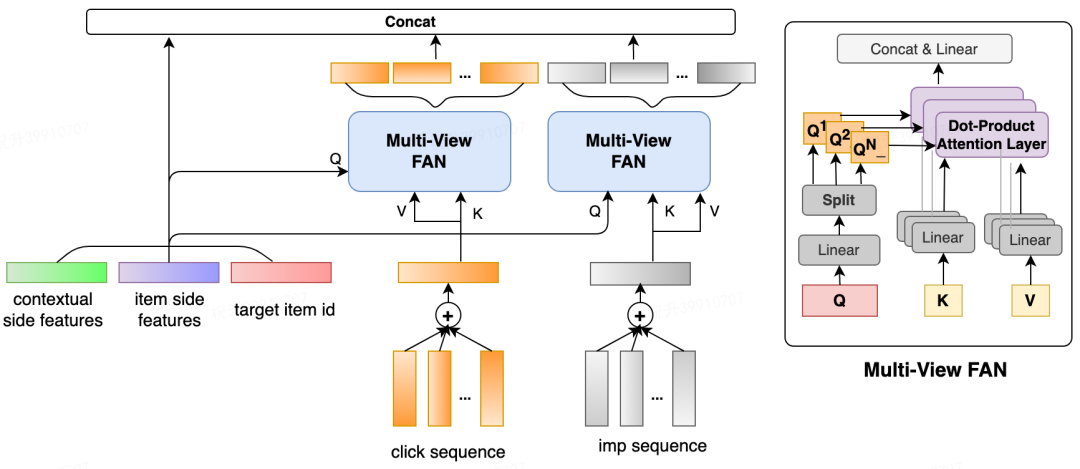
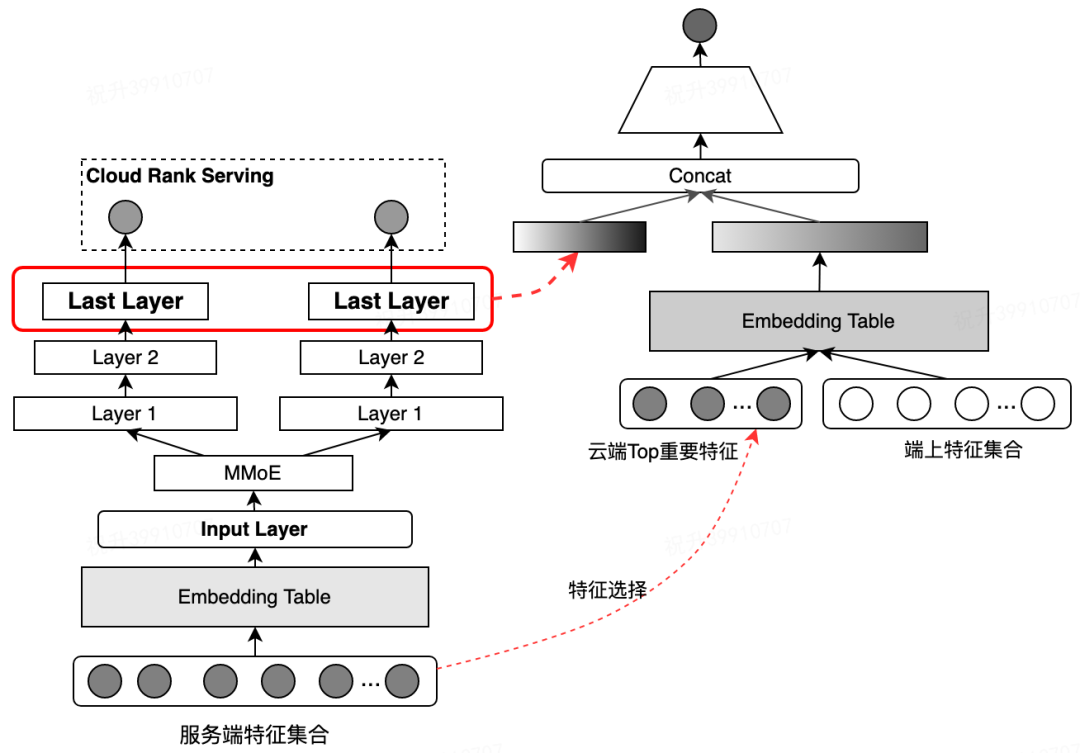
3.3 重排模型设计
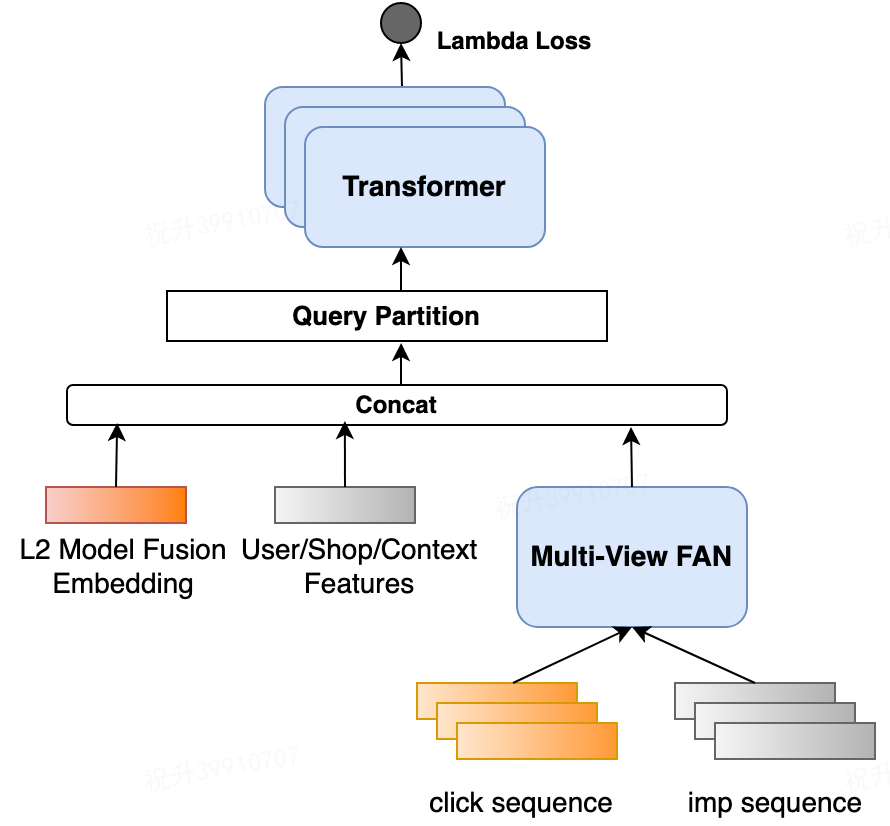
因为搜索精排层使用的是 ListWise 的 LambdaLoss,模型输出的预估分仅有相对的大小意思,不能表示商户的点击率预估范围,无法进行全局的绝对值使用。故仅采用网络的最后一层输出接入。 仅接入最后一层的 Dense 输出,大大损失了云端特征与端上特征的交叉能力,因此,需要通过特征选择方式,选取头部特征加入到云端进行使用。
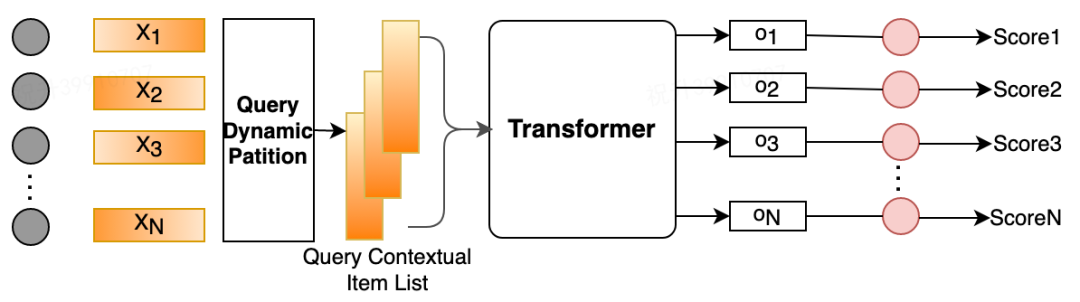
商户特征向量 X :由前文所述的各方面特征(User/Shop 单、双侧统计交叉特征、反馈序列编码特征,以及云端融合输出的特征)经过全连接映射后的输出进行表示。该输出已包含位置信息,所以后续的 Transformer 输入不需要再增加位置编码。 输入层需要进过 Query Dynamic Partition 处理,切分为每个 Query 单元的上下文商户序列,再输入到 Transformer 层进行编码。 Transformer 编码层:通过 Multi-Head Self-Attention 编码商户上下文关系。
在搜索场景下,我们关注的还是用户搜索的成功率(有没有发生点击行为),不同于推荐、广告场景往往基于全局性损失预估 item 的点击率,搜索业务更关心排在页面头部结果的好坏,靠前位置排序需要优先考虑。因此,在重排提升用户搜索点击率目标的建模中,我们采用了 ListWise 的 LambdaLoss,梯度更新中引入 DeltaNDCG 值来强化头部位置的影响。详细推论和计算实现过程参见大众点评搜索基于知识图谱的深度学习排序实践。
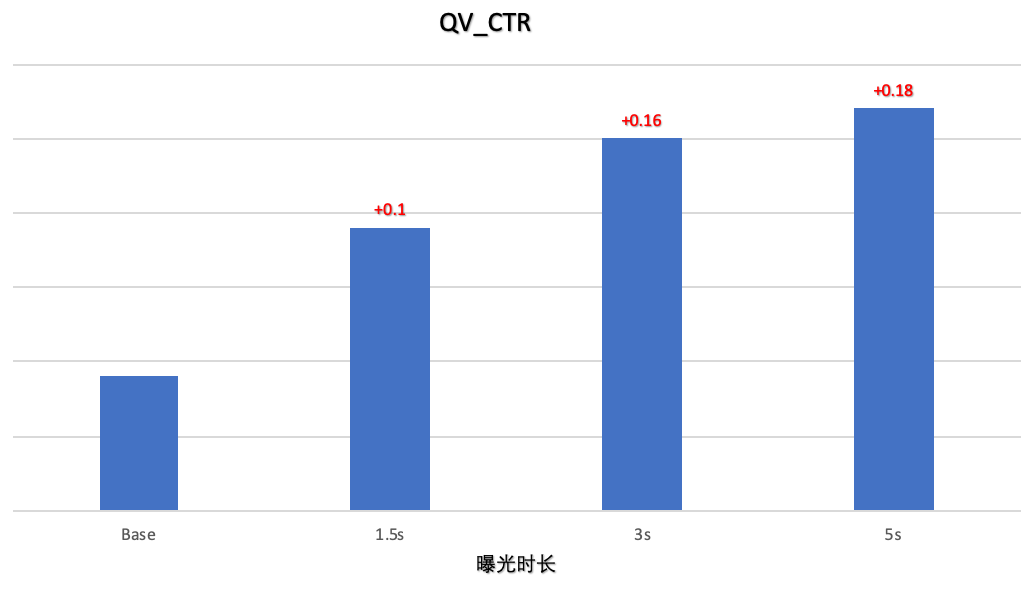
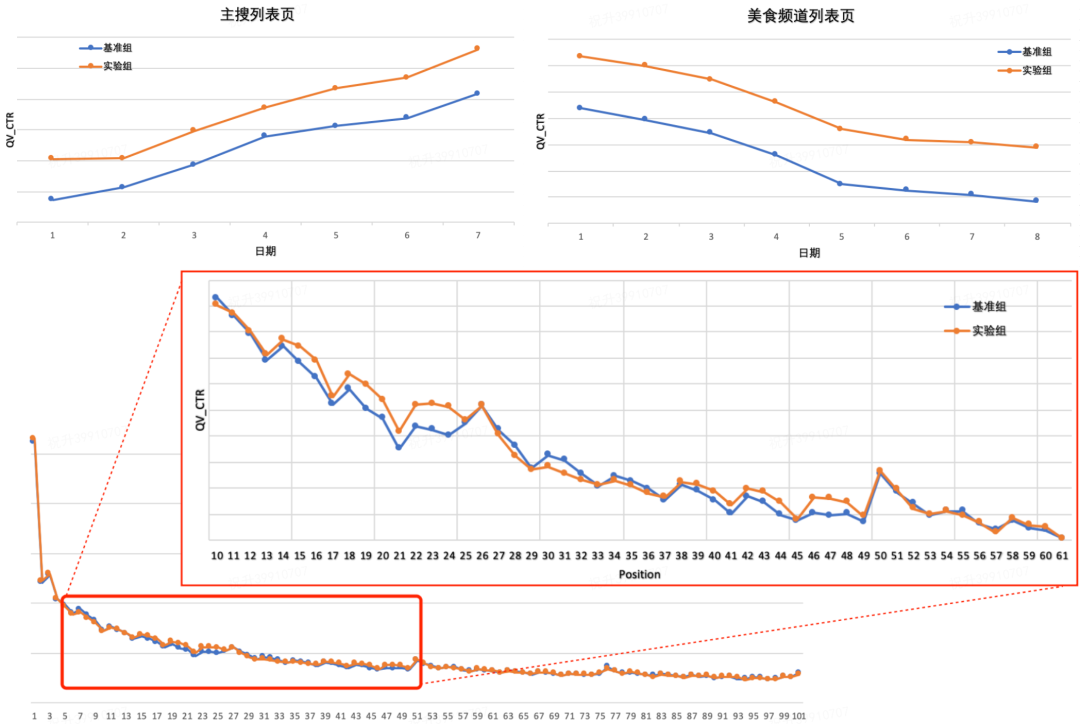
3.4 多场景应用效果

4 系统架构与部署优化
4.1 系统架构
智能触发方案模块,针对业务设计的各类触发事件,执行端上智能模块的调度。例如,用户点击商户行为触发执行本地重排。 端上重排服务模块,执行构建特征数据,并调用端侧推理引擎运行重排模型,进行打分输出。其中: 特征处理部分,是搜索技术中心针对搜/推/广算法场景,专项设计的一套方便算法使用的通用特征算子处理服务。支持对客户端、云端的各种类型数据,使用轻量、简便的表达式构建特征。 端侧推理引擎部分,是终端研发中心输出的统一模型管理框架,支持各类端上轻量级推理引擎部署,以及模型的动态下发控制等。 Native 重排处理逻辑部分,主要进行重排输出后的结果回插,刷新控制处理。
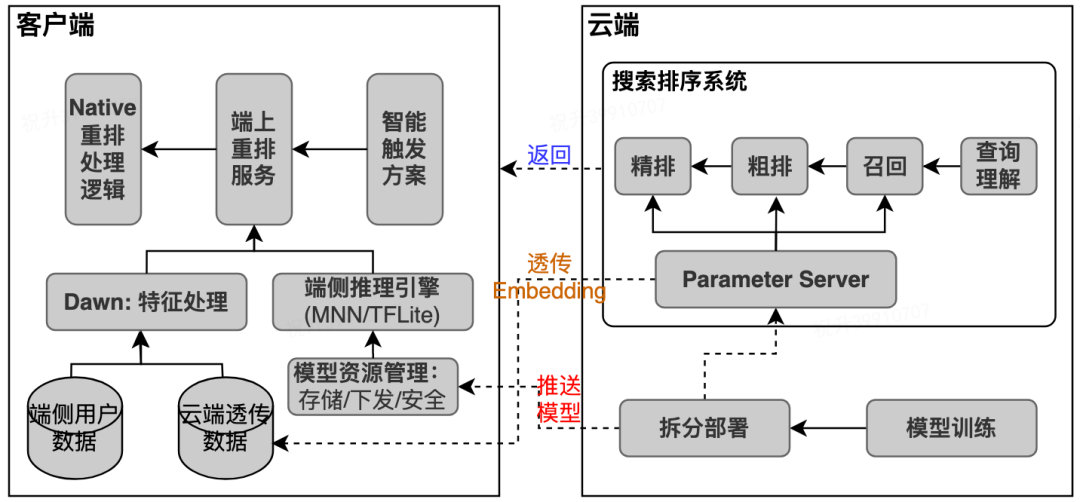
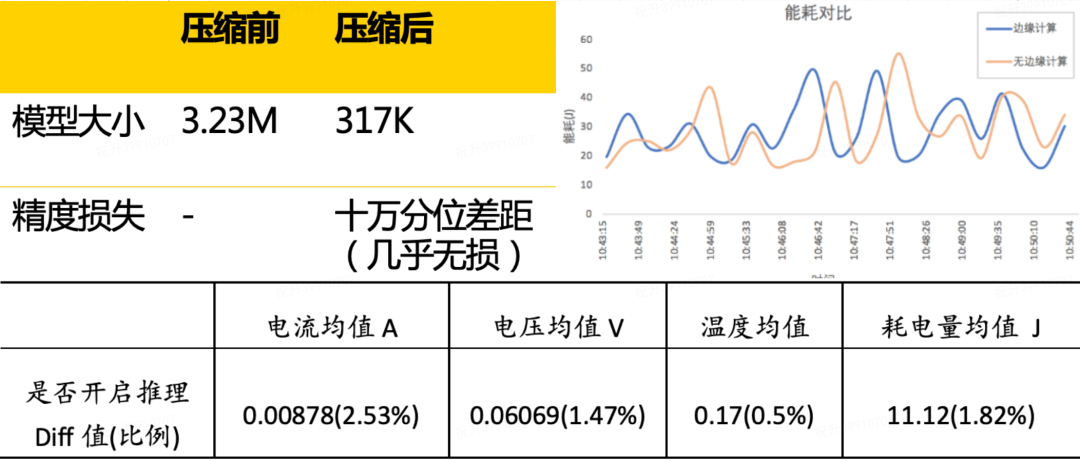
4.2 端上大规模深度模型部署优化
主 Dense 网络以及一些较小的 Query/Contextual 特征、Shop 基础属性特征等输入层结构,转化成 MNN 格式,存储在美团资源管理平台上,供客户端启动时一次性拉取,存储在客户端本地。 大规模的 ID 特征 Embedding Table 部分(占整体网络参数量的 80%),存储在云端的 TF-Servering 服务中,在客户端发起搜索请求时,会从 Serving 服务中获取当前页商户结果所对应的 Embedding 特征,与商户结果列表一同下返回到客户端,与客户端构建的其余特征一起 Concat 后,输入到推理引擎进行打分重排。
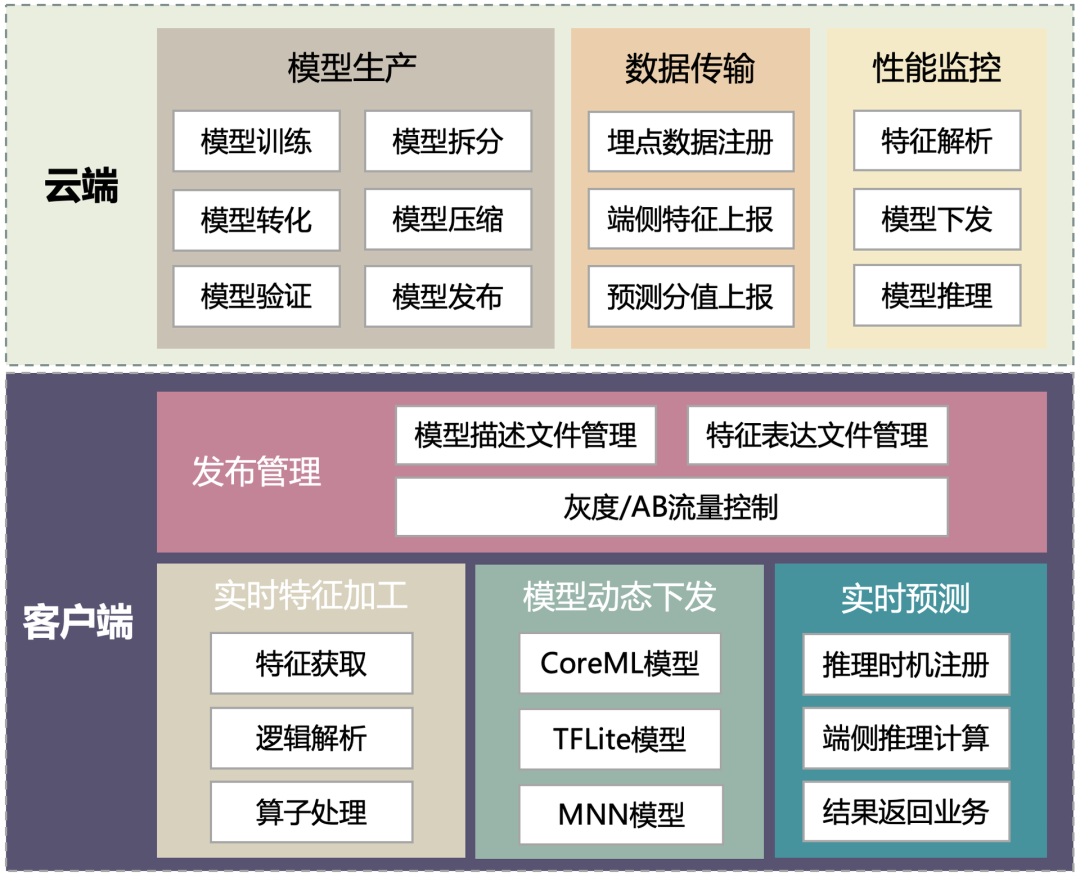
4.3 端智能模型训练预估平台
5 总结与展望
基于联邦学习模式,进一步在保证数据隐私安全及合法合规的基础上,迭代端云联合的智能搜索排序模型。 建模更精确、多样的触发控制策略,对于端上实时用户意图感知的决策模块,当前的控制策略还比较简单。后续我们会考虑结合 Query 上下文,用户反馈信号等特征输出更灵活的预判信号,同时请求云端,获取更多符合用户当前意图的候选结果。 继续优化重排序模型,包括实时反馈序列建模算法,探索对于隐式负反馈信号更鲁棒的编码表达方式等。 思考端上更丰富、灵活的应用场景,比如模型的个性化定制,做到“千人千模”的极致个性化体验。
参考资料
本文作者
推荐阅读:
评论