
为什么Spark能成为最火的大数据计算引擎?它是怎样工作的?
导读:零基础入门Spark必读。

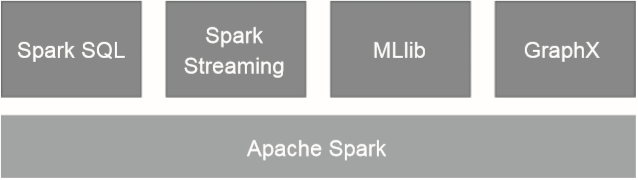
重复工作:不同的系统之间都需要解决一些相同的共性问题,比如分布式执行和容错性。例如MapReduce、SQL查询引擎和机器学习系统都会涉及聚合操作。 组合:不同系统之间的组合使用非常“昂贵”,因为不同系统之间无法有效的功效数。为了组合使用我们需要将数据在不同的系统之间频繁的导出导入,数据用来移动的时间可能都会超过计算的时间。 维护成本:虽然这些系统从每个个体的角度来看都十分优秀,但是它们都是在不同时期由不同的团队设计实现的,其设计思路和实现方式也各不相同。这导致平台在部署运维这些系统的时候十分痛苦,因为它们差异太大了。 学习成本:系统之间巨大的差异性对于开发人员来讲更是如此,这些技术框架拥有不同的逻辑对象、专业术语、API和编程模型,每种框架都需要重新学习一遍才能使用。
相关阅读:
评论