
什么是HBase?它是怎样工作的?终于有人讲明白了

导读:HBase是一个构建在HDFS之上的、分布式的、支持多版本的NoSQL数据库,它的出现补齐了大数据场景下快速查询数据能力的短板。它非常适用于对平台中的热数据进行存储并提供查询功能。

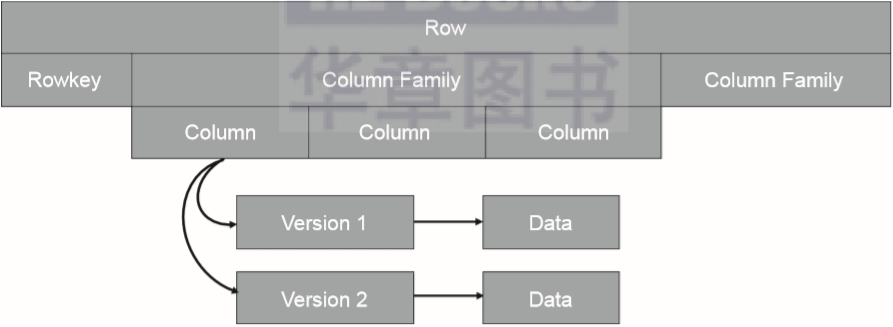
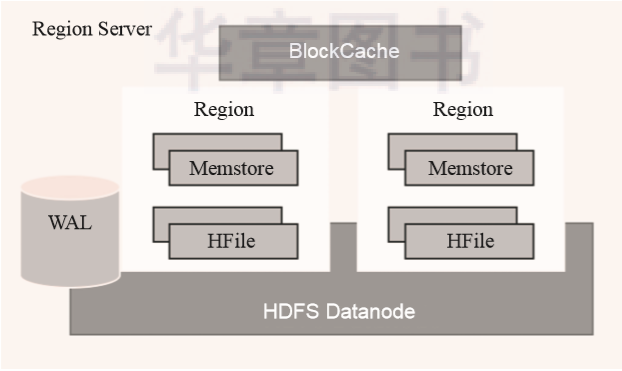
RowKey:HBase中的每行数据都必须拥有一个唯一的行键,它类似于关系型数据库中的主键。 Column Family:HBase中的每个列都归属于一个列簇,它类似于子表的概念。一个列簇对应一个MemStore对象。 Column:HBase用列来定义数据属性字段,和关系型数据库中的表字段类似。 Version:HBase中的数据是有版本概念的,每次新增或者修改数据都会产生一个新的版本。
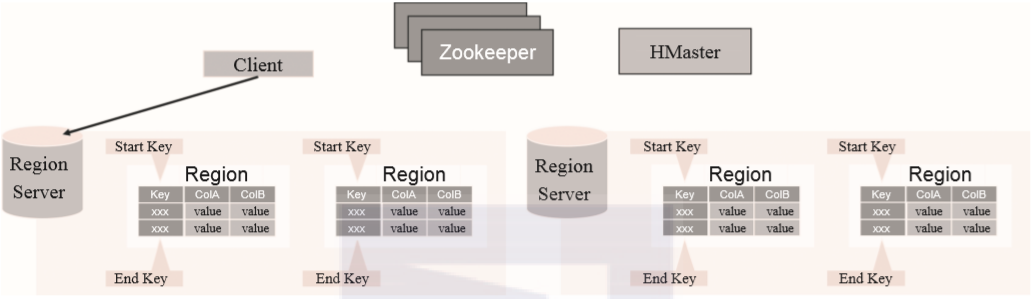
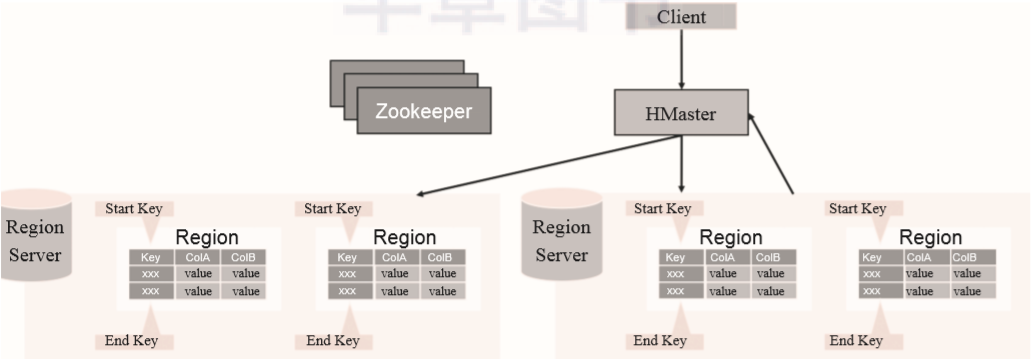
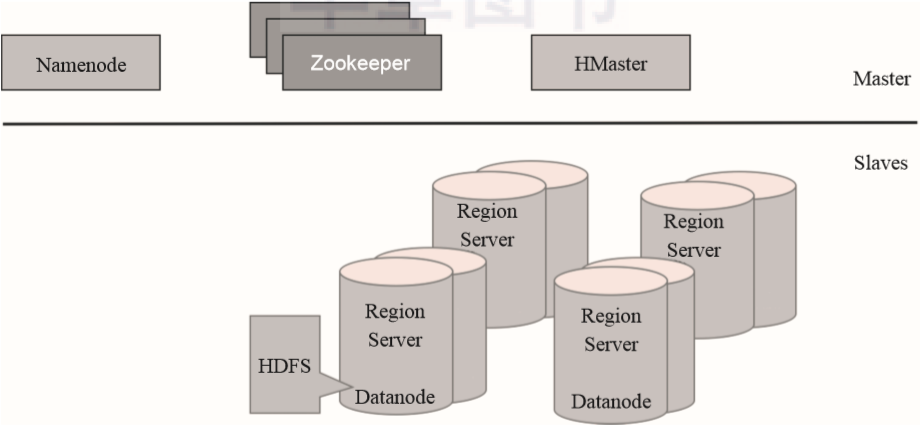
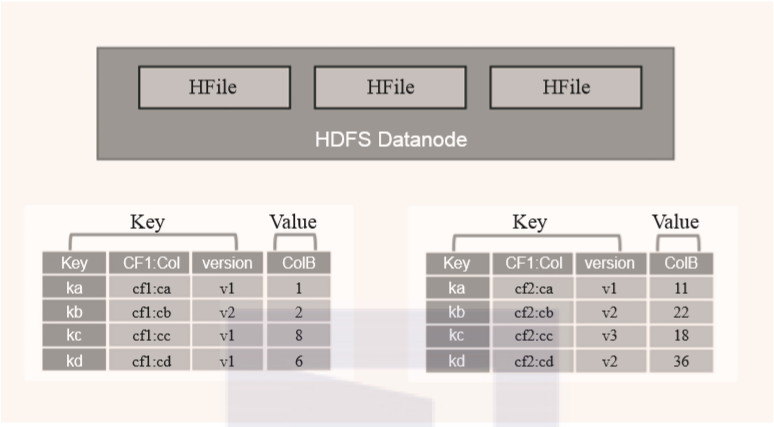
WAL:预写日志是HDFS上的一个文件,它是一种容灾策略。HBase为了提高写入性能,在写入数据的时候并不急于将数据保存到磁盘,而是将数据直接保留在内存中。但是内存中的数据并不是一直可靠的,所以HBase采用了预写日志的方案。当有新数据写入的时候,RegionServer先通过预写日志的方式记录数据,同时将数据放入内存对象MemStore中。当日志写完之后就立刻返回客户端告知写入成功。 BlockCache:数据块缓存是一种读缓存,客户端读取数据的时候会先从这个缓存中查找有没相应的数据。块数据缓存采用LRU失效策略。 MemStore:MemStore是一种写缓存,HBase为了提升写入性能不会直接将数据刷入磁盘而是先使用MemStore内存对象存储数据。再通过一个守护线程定期将MemStore刷入磁盘。在一个region中每个列簇都拥有一个MemStore。 Hfile:Hfile是HBase最终数据存储的载体,它本质上是HDFS上的一个文件。

评论