
Spark 凭什么成为,最火的大数据计算引擎?
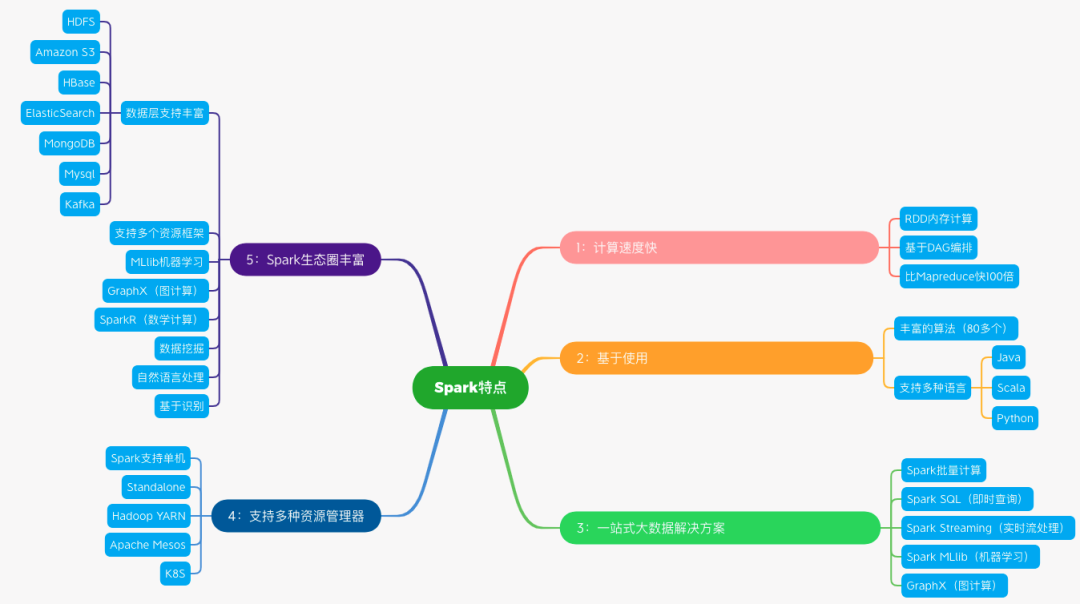
要学好 Spark 首先需要了解其背后的原理,为我们后续基于不同场景选择不同的算子和进行算子优化打下坚实的基础。但对于很多初学者来说,要充分理解原理,尤其当代码在分布式环境下运行时,是有一定难度的。
大数据计算首先需要有大量的数据才能有更好的分析结果,因此基于真实数据的实战是掌握Spark 的关键。因此学习者必须拥有良好的数据模型设计能力,为 Spark 的高效运行创造条件。
如何进行海量数据的任务调优?同样的数据和任务,因为不同时间可调度的物理资源的不同,上一次成功的经验,也许到这一次就导致任务失败了。只有良好的自动化调度和重试机制有利于保障系统任务长期稳定的运行。
王磊是谁?
他是如何讲解 Spark 分布式计算引擎的?

评论