
Rancher 生态中 K3S 集群的三种 HPA 配置试用
本文主要讲述了 K3S 集群下的 HPA 的 3 种详细类型配置,阅读本文你可以了解内容如下:
HPA 概念介绍
HPA 是英文 Horizontal Pod Autoscaler 的缩写,就是我们说的「水平 POD 自动扩缩容」,也就是横向扩缩容。它可以根据监控指标,自动扩缩 ReplicationController、Deployment、ReplicaSet 和 StatefulSet 中的 Pod 数量。HPA 可以很好的帮助服务来应对突发的流量,和普通服务中的针对 vm 的扩缩容有异曲同工之处。
当然除了 HPA,还有集群、纵向等类型的自动扩缩容,本文不做讨论,有兴趣的可参考官方仓库和文档[1]。
K3S 和 K8S 的 HPA 概念和使用基本一致,以下统称容器平台为 K8S。
HPA 工作机制
K8S 中 HPA 的工作机制大致如下:
HPA 控制器会周期性的查询 HPA 定义的监控指标,当达到触发条件时,触发扩缩容动作。这个周期时间默认是 15s,可通过 Controller 的参数 --horizontal-pod-autoscaler-sync-period 来自定义。
HPA 指标类型
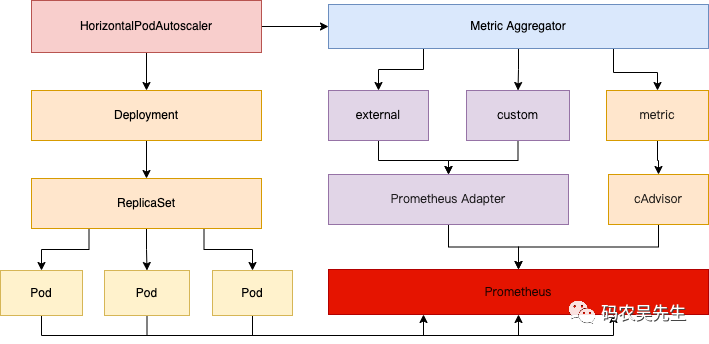
HPA 控制器查询监控指标是通过 APIServer 查询的,这些监控指标是通过 APIServer 的 聚合 (Aggregator[2] )插件机制集成到 APIServer 的,结构大致如下:

目前 HPA 支持的聚合 API 主要有以下三种:
metrics.k8s.io资源类 API,由 K8S 自带的 Metric server[3]提供,其中主要为 nodes 和 pods 的相关监控数据;custom.metrics.k8s.io自定义类 API,由第三方监控方案提供的适配器(Adapter)提供,目前常用为 Prometheus-Adapter[4]。external.metrics.k8s.io外部的 API,和 k8s 集群没有关系的外部指标,由第三方监控方案适配器提供;
更多聚合 API 信息可参考官方文档这里[5]。
指标类型可分为如下几类:
POD 资源使用率:POD 级别的性能指标,通常为一个比率值。 POD 自定义指标:POD 级别的性能指标,通常为一个数值。 容器 资源使用率:容器级别的性能指标,K8S 1.20 引入,主要针对一个 POD 中多个容器的情况,可指定核心业务容器作为资源扩缩阈值。 Object 自定义和外部指标:通常为一个数值,需要容器以某种方式提供,或外部服务提供的指标采集 URL。
HPA ApiVersion
K8S 中各种资源在定义时,使用 apiVsersion 来区分不同版本。HPA 目前主要有以下几个常用版本:
autoscaling/v1只支持针对 CPU 指标的扩缩容;autoscaling/V2beta1除了 cpu,新引入内存利用率指标来扩缩容;autoscaling/V2beta2除了 cpu 和内存利用率,新引入了自定义和外部指标来扩缩容,支持同时指定多个指标;
v2 版本相较 v1 做了不少扩展,除了增加自义定和外部指标外,还支持多指标,当定义多个指标时,HPA 会根据每个指标进行计算,其中缩放幅度最大的指标会被采纳。
在定义 HPA 时,需要合理选择版本,以免造成不必要的错误。更多 APIVersion 信息,可参考官方文档这里[6]。
HPA 实战
接下来我们配置测试下上边说的几种类型的指标 HPA,自定义指标和外部指标需要第三方的适配器(Adapter)来提供,针对 Rancher 生态可使用其集成的 Monitoring (100.1.0+up19.0.3) charts 来解决,其中组件 Prometheus Adapter 便是适配器,提供了自定义和外部类型的 API。详细安装方法可参考我之前的文章k3s 中 helm 自定义安装 traefik v2[7],Monitoring 安装方法一样。
安装好适配器之后,我们准备一个 nginx 服务用来进行自动扩缩容使用,我们使用 cnych/nginx-vts:v1.0 镜像,它集成了 nginx vts 模块,可以查看 nginx 的各种请求数据。创建 deployments 和 service 如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hpa-test
namespace: hd-ops
spec:
selector:
matchLabels:
app: nginx-server
template:
metadata:
labels:
app: nginx-server
spec:
containers:
- name: nginx-demo
image: cnych/nginx-vts:v1.0
resources:
limits:
cpu: 50m
requests:
cpu: 50m
ports:
- containerPort: 80
name: http
---
apiVersion: v1
kind: Service
metadata:
name: nginx-hpa-test
namespace: hd-ops
labels:
app: nginx-svc
spec:
ports:
- port: 80
targetPort: 80
name: http
selector:
app: nginx-server
# type: ClusterIP
type: NodePort
v1 版本 Pod 资源类
首先,我们来测试 v1 版本的 HPA,仅支持 POD 资源 CPU 的指标判断。我们可直接使用 kubectl 命令行来创建,命令如下:
# 创建
$ kubectl autoscale deployment nginx-hpa-test --cpu-percent=20 --min=1 --max=10
# 查看
$ kubectl get hpa -A
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hd-ops nginx-hpa-test Deployment/nginx-hpa-test 2%/20% 1 10 1 1m
其中关注下 TARGETS 列,前边为 CPU 当前使用,后边为触发阈值。我们给 nginx 服务增加压力,观察 hpa 情况,可使用如下命令:
# 加压 替换 node-ip 为 pod 部署的具体 node ip,node-port 为随机映射暴露的节点端口
for i in {0..30000};do echo "start-------->:${i}";curl http://:/status/format/prometheus;echo "=====================================:${i}";sleep 0.01;done
# 查看hpa情况
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa-test Deployment/nginx-hpa-test 26%/20% 1 10 2 3h48m
我们可以看到 pod 的副本数由 1 个变为了 2 个,成功触发 hpa,扩容 1 个 pod。
当我们停止压力之后再观察 HPA,并没有马上缩容,这是因为 k8s 的冷却延迟机制。可通过控制器参数--horizontal-pod-autoscaler-downscale-stabilization来自定义,默认为 5m。
# 五分钟后查看,pod 成功缩容。
~ ⌚ 19:16:08
$ kubectl get hpa -n hd-ops -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa-test Deployment/nginx-hpa-test 0%/20% 1 10 2 3h54m
~ ⌚ 19:16:11
$ kubectl get hpa -n hd-ops -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa-test Deployment/nginx-hpa-test 0%/20% 1 10 1 4h1m
至此,v1 版本的 HPA 行为符合预期,当 CPU 的使用率超过阈值后,会扩容目标 pod,当使用率低于阈值后,会在冷却期结束后缩容。
除了使用 kubectl 命令行来定义 hpa,也可以通过 yaml 来定义,如上 hpa,与下边的 yaml 文件等效。
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa-demo
spec:
scaleTargetRef: # 目标作用对象
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa-test
minReplicas: 1 # 最小副本数
maxReplicas: 10 # 最大副本数
metrics: # 目标指标值
- type: Resource # 资源类型指标
resource:
name: cpu
targetAverageUtilization: 20
v2 版本自定义指标
接下来,我们看下 v2 版本的自定义指标,需要你 K8S 在 1.6 以上。我们可按如下步骤来配置:
1/ 确保自定义指标数据已推送到 Prometheus
理论上来说,只要在 Prometheus 中的数据,我们都可以作为触发指标来配置 HPA。Rancher 平台中,使用 Prometheus Operator 的 CRD 来安装管理的监控组件,我们可通过自定义 ServiceMonitor 来给 Prometheus 添加 target 采集对象。针对上边我们 Nginx 的数据,我们可以编写如下的 ServiceMonitor:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nginx-hpa-svc-monitor
namespace: cattle-monitoring-system
labels:
app: nginx-hpa-svc-monitor
spec:
jobLabel: app
selector:
matchLabels:
app: nginx-svc
namespaceSelector:
matchNames:
- hd-ops
endpoints:
- port: http
interval: 30s
path: /status/format/prometheus
应用之后,我们可以在 prometheus 的 target 页面看到如下的 target 列表项:
serviceMonitor/cattle-monitoring-system/nginx-hpa-svc-monitor/0 (1/1 up)
2/ 选择指标,注册到自定义指标 API
Nginx vts 接口 /status/format/prometheus中,提供了很多 nginx 的请求数据指标,我们拿 nginx_vts_server_requests_total 指标来计算一个实时的请求数作为 HPA 的触发指标。我们需要将该指标注册到 HPA 请求的 custom.metrics.k8s.io 中。Rancher 平台中,我们可以覆盖 Monitoring (100.1.0+up19.0.3) charts 的 values 来注册指标 ,配置如下:
prometheus-adapter:
enabled: true
prometheus:
# Change this if you change the namespaceOverride or nameOverride of prometheus-operator
url: http://rancher-monitoring-prometheus.cattle-monitoring-system.svc
port: 9090
# hpa metrics
rules:
default: false # 需要设置为 false,否则与下边 custom 的指标冲突,会造成整个 custom 指标为空,不知道是不是bug;
custom:
# 具体详细的参数配置可参考官方文档:https://docs.rancher.cn/docs/rancher2/cluster-admin/tools/cluster-monitoring/cluster-metrics/custom-metrics/_index
- seriesQuery: "nginx_vts_server_requests_total" # '{__name__=~"^nginx_vts_.*_total",namespace!="",pod!=""}'
seriesFilters: []
resources:
overrides:
namespace: # 这里的namespace和pod是prometheus里面指标的标签,会作为分组
resource: namespace
service:
resource: services
pod:
resource: pod
name:
matches: ^(.*)_total
as: "${1}_per_second"
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
运行如下命令,更新组件。
helm upgrade --install rancher-monitoring ./ -f k3s-values.yaml -n cattle-monitoring-system
可我们通过 API 查看是否注册成功:
# 查看 api 列表
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/" |python3 -m json.tool
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "namespaces/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "services/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "pods/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
# 查看具体某个指标的数值
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/hd-ops/pods/*/nginx_vts_server_requests_per_second" |python3 -m json.tool
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/hd-ops/pods/%2A/nginx_vts_server_requests_per_second"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "hd-ops",
"name": "nginx-hpa-test-7695f97455-mmpxz",
"apiVersion": "/v1"
},
"metricName": "nginx_vts_server_requests_per_second",
"timestamp": "2022-04-01T07:21:28Z",
"value": "133m", # 此处单位m 为千分之的意思
"selector": null
}
]
}
看到如上返回,说明注册成功了,之后我们就可以使用其中的指标名称来配置 HPA 了。
3/ 配置 HPA
编写 HPA yaml 如下:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa-custom
namespace: hd-ops
spec:
scaleTargetRef: # 应用目标服务 Deployment
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa-test
minReplicas: 1 # 保留最小副本数
maxReplicas: 10 # 扩容最大副本数
metrics:
- type: Pods # 指标类型
pods:
metric:
name: nginx_vts_server_requests_per_second # 指标名称
target:
type: AverageValue
averageValue: 5
应用之后,我们可以看到数据已经采集到:
$ kubectl get hpa -A
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hd-ops nginx-hpa-custom Deployment/nginx-hpa-test 133m/5 1 10 1 1m
4/ 测试 HPA
运行如下命令加压测试:
# 加压
for i in {0..30000};do echo "start-------->:${i}";curl http://:/status/format/prometheus;echo "=====================================:${i}";sleep 0.01;done
# 查看hpa情况
$ kubectl get hpa -A
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hd-ops nginx-hpa-custom Deployment/nginx-hpa-test 11333m/5 1 10 3 72m
请求数超过了阈值 5,可以看到 REPLICAS 副本数变成了 3。停止压测后,5 分钟后查看 hpa,又缩容回去,符合预期。
v2 版本的 HPA 还可以使用其他类型,且支持多个指标,如下示例:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa-custom
namespace: hd-ops
spec:
scaleTargetRef: # 应用目标服务 Deployment
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa-test
minReplicas: 1 # 保留最小副本数
maxReplicas: 10 # 扩容最大副本数
metrics:
- type: Pods # 指标类型
pods:
metric:
name: nginx_vts_server_requests_per_second # 指标名称
target:
type: AverageValue
averageValue: 5
- type: Resource # 资源类型和v1版本写法略有区别,需要注意
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Object # 除pod外的其他资源对象类型
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
kind: Value
value: 10k # 数值,直接与获取到的指标值比较
指标类型 type 有下边 4 种取值:
Resource: 指当前伸缩对象 pod 的 cpu 和 内存 支持 utiliztion 和 averagevalue 类型的目标值。一般情况下,计算 CPU 使用率使用 averageUtilization 定义平均使用率。计算内存资源,使用 AverageValue 定义平均使用值。Pods: 指的是伸缩对象 Pod 的指标,数据有第三方的 Adapter 提供,只支持 AverageValue 类型的目标值。Object: K8S 内部除 pod 之外的其他对象的指标,数据有第三方的 Adapter 提供,支持 Value 和 AverageValue 类型的目标值。External: K8S 外部的指标,数据有第三方 Adapter 提供,支持 Value 和 AverageValue 类型的目标值。
更多 type 类型信息,可参考官方文档这里[8]。
v2 版本外部指标
最后我们来测试下外部指标,要求 K8S 版本在 1.10 以上,配置步骤和自定义表一致,在注册指标到 /apis/external.metrics.k8s.io/v1beta1/ 时配置略有区别,
我们这里随便拿一个与 K8S 无关的外部主机的 cpu 使用率做下测试,注册配置如下:
prometheus-adapter:
enabled: true
prometheus:
# Change this if you change the namespaceOverride or nameOverride of prometheus-operator
#url: http://rancher-monitoring-prometheus.cattle-monitoring-system:9090/
url: http://rancher-monitoring-prometheus.cattle-monitoring-system.svc
port: 9090
# hpa metrics
rules:
default: false
# 如下为外部配置
external:
- seriesQuery: 'cpu_usage_idle{cpu="cpu-total"}' # '{__name__=~"^nginx_vts_.*_total",namespace!="",pod!=""}'
seriesFilters: []
resources:
template: <<.Resource>>
name:
matches: "^(.*)"
as: "cpu_usage"
metricsQuery: (100-cpu_usage_idle{cpu="cpu-total",ip="192.168.10.10"})/100 #<<.Series>>{<<.LabelMatchers>>}
这里 resources 我们直接使用 template 来模糊定义让系统自动处理,因为外部指标和 K8S API 资源并不一定有关系,我们 metricsQery 这块也使用明确写出的方式来处理。
应用之后,我们同样可以使用 API 来查看:
# 查看指标列表
$ kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/"|python3 -m json.tool
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "external.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "cpu_usage",
"singularName": "",
"namespaced": true,
"kind": "ExternalMetricValueList",
"verbs": [
"get"
]
}
]
}
# 查看具体的指标数据
$ kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/hd-ops/cpu_usage"|python3 -m json.tool
{
"kind": "ExternalMetricValueList",
"apiVersion": "external.metrics.k8s.io/v1beta1",
"metadata": {},
"items": [
{
"metricName": "cpu_usage",
"metricLabels": {
"__name__": "cpu_usage",
"bg": "ops",
"cpu": "cpu-total",
"idc": "ali",
"ident": "xxxx-host",
"ip": "192.168.10.10",
"region": "BJ",
"svc": "demo-test"
},
"timestamp": "2022-04-02T03:28:50Z",
"value": "11m"
},
......
]
}
有时候 API 会返回为空,大概率是我们注册的 API rule 配置有问题,可修改配置明确查询 PromQL 测试。
定义 HPA 和 custom 类型也一样,如下:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa-custom
namespace: hd-ops
spec:
scaleTargetRef: # 应用目标服务 Deployment
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa-test
minReplicas: 1 # 保留最小副本数
maxReplicas: 10 # 扩容最大副本数
metrics:
- type: External
external:
metric:
name: cpu_usage
selector:
matchLabels:
ip: "192.168.10.10"
target:
type: AverageValue
averageValue: 10m # 该数值为使用率 1% ,测试无实际意义
应用后查看 hpa 情况:
$ kubectl get hpa -A
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hd-ops nginx-hpa-custom-external Deployment/nginx-hpa-test 18m/10m (avg) 1 10 2 11m
可以看到目标值 18m 超过了 阈值 10m,目标服务副本有 1 个变为 2 个,符合预期。
总结及问题回顾
至此,HPA 的三种大类型我们都测试完成。Rancher K3S 生态中,总体上来说和 K8S 并没有什么不同。在 Rancher 平台中有下边几个问题需要需要注意下:
1、Rancher Charts 商店中 Monitor集成的 Prometheus Adapter 中,当定义 custom 和 external rule 规则时,需要关闭 default 默认的规则,否则会认证失败,造成整个 API 请求为空。错误信息如下:
client.go:233: [debug] error updating the resource "rancher-monitoring-alertmanager.rules":
cannot patch "rancher-monitoring-alertmanager.rules" with kind PrometheusRule: Internal error occurred: failed calling webhook "prometheusrulemutate.monitoring.coreos.com": Post "https://rancher-monitoring-operator.cattle-monitoring-system.svc:443/admission-prometheusrules/validate?timeout=10s": context deadline exceeded
扩展阅读
https://www.jetstack.io/blog/resource-and-custom-metrics-hpa-v2/ https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-metrics-apis https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/
参考资料
官方仓库和文档: https://github.com/kubernetes/autoscaler
[2]Aggregator: https://kubernetes.io/zh/docs/tasks/extend-kubernetes/configure-aggregation-layer/
[3]Metric server: https://github.com/kubernetes-sigs/metrics-server
[4]Prometheus-Adapter: https://github.com/kubernetes-sigs/prometheus-adapter/blob/master/docs/walkthrough.md
[5]这里: https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-metrics-apis
[6]这里: https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.23/#horizontalpodautoscaler-v1-autoscaling
[7]k3s 中 helm 自定义安装 traefik v2: https://pylixm.top/posts/2022-02-21-k3s-traefik-v2.html
[8]这里: https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/#autoscaling-on-multiple-metrics-and-custom-metrics