
LinkedIn开源Dagli,发布Java机器学习函数库

新智元报道
新智元报道
编辑:QJP
【新智元导读】LinkedIn 最近开源了 Dagli,一个面向 Java (和其他 JVM 语言)的机器学习库,让编写代码减少bug、可读、可修改、可维护和可部署的模型管道变得更加容易,而不会导致技术难题。
近年来,越来越多的优秀的机器学习工具不断涌现,如 TensorFlow、 PyTorch、 Caffee 和 CNTK、用于大规模数据的 Spark 和 Kubeflow,以及用于各种通用模型的 scikit-learn、 ML.NET 和最近的 Tripo 等。

根据Algorithmia 2019年的一项调查,虽然企业使用机器学习算法的成熟度普遍在提高,但大多数公司(超过50%) 仍需要花费8至90天时间部署单一机器学习模型(18% 的公司花费的时间超过90天)。
大多数人将责任归咎于模型规模和复现模型面临的挑战、缺乏管理人员的支持,以及可用的工具缺失等原因。
对于 Dagli 来说,模型的 pipeline 被定义为一个有向无环图,一个由顶点和边组成的图,每条边从一个顶点定向到另一个顶点,用于训练和推理。
Dagli 的环境提供了流水线定义、静态类型、近乎无处不在的不变性以及其他特性,以防止大多数潜在的逻辑错误。
LinkedIn 自然语言处理研究科学家杰夫 · 帕斯特纳克在一篇博客中写道: 「模型通常是集成的管道的一部分, 建造、训练和将这些管道部署到生产环节仍然非常繁琐」, 通常需要进行重复的或无关的工作,以适应训练和推理,从而产生脆弱的「粘合」代码,使模型未来的演化和维护变得复杂。
Dagli 可以在服务器、 Hadoop、命令行接口、 IDE 和其他典型的 JVM 中工作。许多pipeline组件也已经可以使用,包括神经网络、 逻辑回归、GBDT、 FastText、交叉验证、交叉训练、特征选择、数据读取器、评估和特征转换等。
通过发布 Dagli,领英希望为机器学习社区做出三个主要贡献:
1. 一个易于使用、抗bug、基于 JVM 的机器学习框架
2. 一个综合了各种统计模型和 transformer 的 可以 “开箱即用” 的库
3. 一个简单但功能强大的机器学习 pipeline 作为有向无环图的新抽象,它支持优化的同时仍然保持每个组件易于实现,可与传统的“黑盒”相媲美。
对于有经验的数据科学家来说,Dagli 提供了一条通往可维护和可扩展的高性能、可生产的人工智能模型的道路,这些模型可以利用现有的 JVM 技术堆栈。
对于经验较少的软件工程师来说,Dagli 提供了一个 API,可以与 JVM 语言和工具一起使用,这些语言和工具被设计用来避免典型的逻辑错误。
帕斯特纳克还指出: 「我们希望 Dagli 能够使高效、可投入生产的模型更容易编写、修改和部署,避免经常伴随而来的技术问题和长期维护的挑战」。
Dagli 充分利用了先进的多核理器和强大的图形卡,对模型进行有效的单机训练。
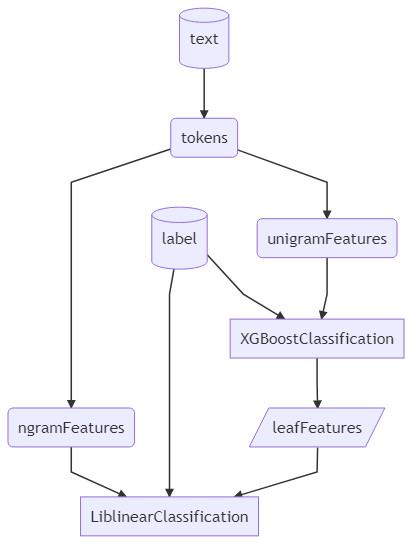
为了具体了解 Dagli 是如何工作的,让我们从一个文本分类器开始,这个文本分类器使用梯度增强决策树模型(XGBoost)的活动叶片,以及一组高维的 N-gram 作为 LR 模型分类器的特征:

通过使用 Dagli,领英希望使高效的、可投入生产的模型更容易编写、修改和部署,避免经常伴随它们的技术挑战和长期维护。
最后,附上Dagli的GitHub地址链接:
https://github.com/linkedin/dagli

