
5招学会Pandas数据类型转化
今天我们就整理一下常见的数据类型转化操作,然后收藏起来以备不时之需吧!
目录:
1. 加载数据时指定数据类型
2. astype转换数据类型
3. pd.to_xx转化数据类型
3.1. pd.to_datetime转化为时间类型
3.2. pd.to_numeric转化为数字类型
3.3. pd.to_timedelta转化为时间差类型
4. 智能判断数据类型
5. 数据类型筛选

1. 加载数据时指定数据类型
一般来说,为了省事我都是直接pd.DataFrame(data)或pd.read_xx(filename)就完事了。
比如:(下面数据大家直接拷贝后读取剪切板即可)
import pandas as pd
df = pd.read_excel('数据类型转换案例数据.xlsx')
df
| 国家 | 受欢迎度 | 评分 | 向往度 | |
|---|---|---|---|---|
| 0 | 中国 | 10 | 10 | 10.0 |
| 1 | 美国 | 6 | 5.8 | 7.0 |
| 2 | 日本 | 2 | 1.2 | 7.0 |
| 3 | 德国 | 8 | 6.8 | 6.0 |
| 4 | 英国 | 7 | 6.6 | nan |
我们查看dtypes属性
df.dtypes
国家 object
受欢迎度 int64
评分 float64
向往度 float64
dtype: object
可以看到国家字段是object类型,受欢迎度是int整数类型,评分与向往度都是float浮点数类型。而实际上,对于向往度我们可能需要的是int整数类型,国家字段是string字符串类型。
那么,我们可以在加载数据的时候通过参数dtype指定各字段数据类型。
import pandas as pd
df = pd.read_excel('数据类型转换案例数据.xlsx',
dtype={
'国家':'string',
'向往度':'Int64'
}
)
df
| 国家 | 受欢迎度 | 评分 | 向往度 | |
|---|---|---|---|---|
| 0 | 中国 | 10 | 10 | 10 |
| 1 | 美国 | 6 | 5.8 | 7 |
| 2 | 日本 | 2 | 1.2 | 7 |
| 3 | 德国 | 8 | 6.8 | 6 |
| 4 | 英国 | 7 | 6.6 | <nan> |
再查看dtypes属性
df.dtypes
国家 string
受欢迎度 int64
评分 float64
向往度 Int64
dtype: object
同样,在创建DataFrame类型数据时也可以通过dtype参数进行数据类型设定(案例是对全部字段进行设置)。
df = pd.DataFrame({'A':[1,2,3,4.],
'B':[1,3,5,7]
},
dtype='float32'
)
df.dtypes
A float32
B float32
dtype: object
2. astype转换数据类型
对于已经存在的数据,我们常用astype来转换数据类型,可以对某列(Series)也可以同时指定多列。
In [1]: df.受欢迎度.astype('float')
Out[1]:
0 10.0
1 6.0
2 2.0
3 8.0
4 7.0
Name: 受欢迎度, dtype: float64
In [2]: df.astype({'国家':'string',
'向往度':'Int64'})
Out[2]:
国家 受欢迎度 评分 向往度
0 中国 10 10.0 10
1 美国 6 5.8 7
2 日本 2 1.2 7
3 德国 8 6.8 6
4 英国 7 6.6 <NA>3. pd.to_xx转化数据类型
3.1. pd.to_datetime转化为时间类型
日期like的字符串转换为日期 时间戳转换为日期等 数字字符串按照format转换为日期
如果遇到无法转换的情况,默认情况下会报错,可以通过参数设置errors='coerce'将无法转换的设置为NaT。
# 将字符串转化为日期
In [3]: s = pd.Series(['3/11/2000', '3/12/2000', '3/13/2000'])
In [4]: s
Out[4]:
0 3/11/2000
1 3/12/2000
2 3/13/2000
dtype: object
In [5]: pd.to_datetime(s, infer_datetime_format=True)
Out[5]:
0 2000-03-11
1 2000-03-12
2 2000-03-13
dtype: datetime64[ns]
# 还可以将时间戳转化为日期
In [6]: s = pd.Series([1490195805, 1590195805, 1690195805])
In [7]: pd.to_datetime(s, unit='s')
Out[7]:
0 2017-03-22 15:16:45
1 2020-05-23 01:03:25
2 2023-07-24 10:50:05
dtype: datetime64[ns]
In [8]: s = pd.Series([1490195805433502912, 1590195805433502912, 1690195805433502912])
In [9]: pd.to_datetime(s, unit='ns')
Out[9]:
0 2017-03-22 15:16:45.433502912
1 2020-05-23 01:03:25.433502912
2 2023-07-24 10:50:05.433502912
dtype: datetime64[ns]
# 数字字符串按照format转换为日期
In [10]: s = pd.Series(['20200101', '20200202', '202003'])
In [11]: pd.to_datetime(s, format='%Y%m%d', errors='ignore')
Out[11]:
0 20200101
1 20200202
2 202003
dtype: object
In [12]: pd.to_datetime(s, format='%Y%m%d', errors='coerce')
Out[12]:
0 2020-01-01
1 2020-02-02
2 NaT
dtype: datetime64[ns]
需要注意的是,对于上述时间戳的日期转化,起始时间默认是1970-01-01,对于国内时间来说会相差8小时,我们有以下几种方式处理。
In [13]: s
Out[13]:
0 1490195805
1 1590195805
2 1690195805
dtype: int64
# 默认情况下 格林威治时间
In [14]: pd.to_datetime(s, unit='s')
Out[14]:
0 2017-03-22 15:16:45
1 2020-05-23 01:03:25
2 2023-07-24 10:50:05
dtype: datetime64[ns]
# 将起始时间加上 8小时
In [15]: pd.to_datetime(s, unit='s', origin=pd.Timestamp('1970-01-01 08:00:00'))
Out[15]:
0 2017-03-22 23:16:45
1 2020-05-23 09:03:25
2 2023-07-24 18:50:05
dtype: datetime64[ns]
# 手动 加上 8小时
In [16]: pd.to_datetime(s, unit='s') + pd.Timedelta(days=8/24)
Out[16]:
0 2017-03-22 23:16:45
1 2020-05-23 09:03:25
2 2023-07-24 18:50:05
dtype: datetime64[ns]
3.2. pd.to_numeric转化为数字类型
In [17]: s = pd.Series(['1.0', '2', -3])
In [18]: pd.to_numeric(s)
Out[18]:
0 1.0
1 2.0
2 -3.0
dtype: float64
In [19]: pd.to_numeric(s, downcast='signed')
Out[19]:
0 1
1 2
2 -3
dtype: int8
In [20]: s = pd.Series(['apple', '1.0', '2', -3])
In [21]: pd.to_numeric(s, errors='ignore')
Out[21]:
0 apple
1 1.0
2 2
3 -3
dtype: object
In [22]: pd.to_numeric(s, errors='coerce')
Out[22]:
0 NaN
1 1.0
2 2.0
3 -3.0
dtype: float64
3.3. pd.to_timedelta转化为时间差类型
将数字、时间差字符串like等转化为时间差数据类型
In [23]: import numpy as np
In [24]: pd.to_timedelta(np.arange(5), unit='d')
Out[24]: TimedeltaIndex(['0 days', '1 days', '2 days', '3 days', '4 days'], dtype='timedelta64[ns]', freq=None)
In [25]: pd.to_timedelta('1 days 06:05:01.00003')
Out[25]: Timedelta('1 days 06:05:01.000030')
In [26]: pd.to_timedelta(['1 days 06:05:01.00003', '15.5us', 'nan'])
Out[26]: TimedeltaIndex(['1 days 06:05:01.000030', '0 days 00:00:00.000015500', NaT], dtype='timedelta64[ns]', freq=None)4. 智能判断数据类型
convert_dtypes方法可以用来进行比较智能的数据类型转化,请看
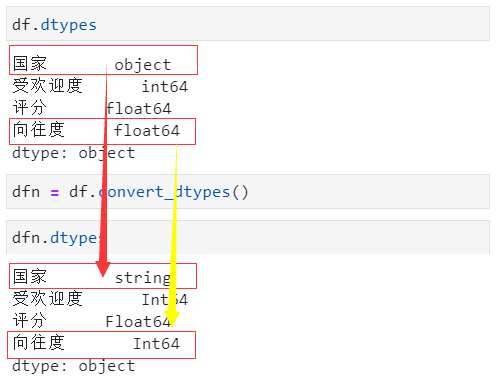
5. 数据类型筛选
看到在一些学习群经常有朋友问怎么筛选指定数据类型的字段,今天我们也来介绍一下。
Pandas提供了一个按照字段数据类型筛选的函数select_dtypes(),通过参数可以选定需要的数据类型字段和排除的数据类型字段。
Signature:
df.select_dtypes(include=None, exclude=None) -> 'DataFrame'
Docstring:
Return a subset of the DataFrame's columns based on the column dtypes.
数据类型有以下几种:
数字:
number或int、float布尔:
bool时间:
datetime64时间差:
timedelta64类别:
category字符串:
string对象:
object
In [27]: df
Out[27]:
国家 受欢迎度 评分 向往度
0 中国 10 10.0 10.0
1 美国 6 5.8 7.0
2 日本 2 1.2 7.0
3 德国 8 6.8 6.0
4 英国 7 6.6 NaN
In [28]: df.dtypes
Out[28]:
国家 object
受欢迎度 int64
评分 float64
向往度 float64
dtype: object
In [29]: df.select_dtypes(include='int')
Out[29]:
受欢迎度
0 10
1 6
2 2
3 8
4 7
In [30]: df.select_dtypes(include='number')
Out[30]:
受欢迎度 评分 向往度
0 10 10.0 10.0
1 6 5.8 7.0
2 2 1.2 7.0
3 8 6.8 6.0
4 7 6.6 NaN
In [31]: df.select_dtypes(include=['int','object'])
Out[31]:
国家 受欢迎度
0 中国 10
1 美国 6
2 日本 2
3 德国 8
4 英国 7
In [32]: df.select_dtypes(exclude=['object'])
Out[32]:
受欢迎度 评分 向往度
0 10 10.0 10.0
1 6 5.8 7.0
2 2 1.2 7.0
3 8 6.8 6.0
4 7 6.6 NaN
以上就是本次全部内容,希望对你有帮助,喜欢的话记得点个赞,刷个在看哦!
其实,还有更多参数方法大家可以通过help或者?来看一看演示一下!




