不知道MYSQL怎么控制并发数据的读取,怎么办?

点击上方「蓝字」关注我们
数据隔离是怎么实现的
❝注意:本次数据隔离是建立在可重复读的场景下
❞
在可重复读的场景下,我们了解每次启动事务的时候,会在当前启动一个视图,而这个视图是整个数据库的视图快照。
嘿嘿,是不是想数据库那么大,为啥我们没有感觉到创建快照时间的消耗呢?
这是因为数据库创建的视图快照利用了「所有数据都有多个版本的特性,来实现快速创建视图快照的能力」。
那数据多个版本是怎么回事呢?
准备下数据
先别急,我们准备下数据。
现在创建一个表,并且插入三条数据。
create table scores
(
id int not null
primary key,
score float null
);
INSERT INTO scores (id, score) VALUES (1, 3.5);
INSERT INTO scores (id, score) VALUES (2, 3.65);
INSERT INTO scores (id, Score) VALUES (3, 4);
在开始使用前我们要了解两个小知识点。begin/start transaction 与 start transaction with consistent snapshot。
begin/start transaction 视图的创建是建立在begin/ start transaction 之后SQL语句才会创建视图, 比如 下面案例
begin
select source from scores; //视图是在这里开始创建 而不是在begin那里创建
commitstart transaction with consistent snapshot:则是该语句执行后,就创建视图。
了解上面两个创建事务的区别后,我们来看下视图是怎么创建出来多个数据版本的. 以下SQL在两个窗口打开。
| 事务A | 事务B | 结果 |
|---|---|---|
| start transaction with consistent snapshot | 开启事务,并创建视图 | |
| -- | start transaction with consistent snapshot | 开启事务,并创建视图 |
| select score from scors where id =2 | -- | 事务A中的值为3.65 |
| -- | update scores set scores = 10 where id =2 | 事务B修改为10 |
| -- | select score from scores where id =2 | 事务B显示为10 |
| select score from scores where id =2 | -- | 事务A显示为3.65 |
| select score from scores where id =2 for update | -- | 会被锁住,等待事务B释放锁(间隙锁) |
| -- | commit | 提交事务B |
| select score from scores where id =2 for update | -- | 这个语句可以看到变成了10(利用了当前读) |
| select score from scores where id =2 | -- | 不加 for update 那么结果还是3.65 |
| commit | --- | --- |
上述流程就是两个不同的请求过来,对数据库同一个表的不同操作。
当事务A执行start transaction with consistent snapshot之后,A的视图就开始被创建了,这时候是看不到事务B对其中的修改,就算事务Bcommit之后,只要事务A不结束,它看到的结果就是它启动时刻的值。
「这就与不重复提交,执行过程中看到的结果与启动的时候看到的结果是一致的这句话对应上了」。
快照多版本
前面说了,快照是事务的启动的时候是基于整个数据库的,而整个数据库是很大,那MYSQL是怎么让我们无感并快速创建一个快照呢。
快照多版本你可以认为是由以下两部分构成。
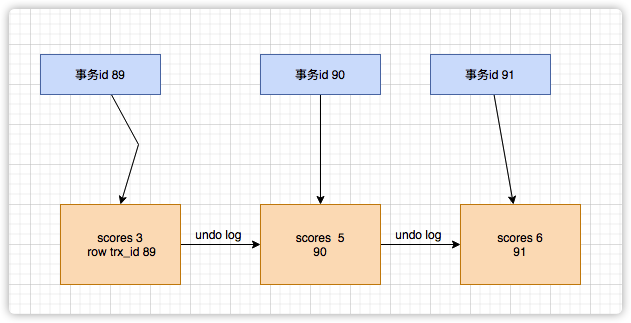
事务id(transaction id):这个是由事务启动的时候向InnoDB启动时申请的。并且一定注意哦它是递增的。 row trx_id:这个id其实就是事务ID,每次事务更新数据的时候回将事务ID赋值给这个数据版本的事务ID上,将这个数据版本的事务ID称为 row trx_id.
当一行记录存在多个数据版本的时候,那么就有多个row trx_id 。举个例子
| 版本 | 值 | 事务ID | 对应的语句操作 |
|---|---|---|---|
| v1 | score =3 | 89 | -- |
| v2 | score =5 | 90 | update scores set score = 5 where id =3; select score from scores where id =3; |
| v3 | score = 6 | 91 | update scores set score = 6 where id =3; |
v1->v2->v3 这里面涉及了三个版本的迭代。中间是通过undo log 日志来保存更新的记录的。
注意启动快照之后,可重复读隔离情况下,获取到v1的值,不是说MYSQL直接存储的该值,而是利用现在这条记录的最新版本与undo log日志计算出来的,比如通过v3 ->v2—>v1 计算出v1中score值。
版本计算
上面简单说了下版本的计算规则,但是在MYSQL中,版本并不是那么简单的计算的,我们现在来看下到底怎么计算的,
这个两点我们在注意一下:
事务在启动的时候会向InnoDB的事务系统申请事务ID,这个事务ID是严格递增的。 每行数据是多个版本,这个版本的id就是row trx_id,而事务「更新数据」(更新数据的时候才会生成一个新的版本)的时候会生成一个新的数据版本,并把事务ID赋值给这个数据的事务ID==row trx_id,
事务启动的时候,能看到所有已经提交事务的结果,但是他启动之后,其他事务的变更是看不到的。
当事务启动的瞬间,除了已经提交的事务,创建的瞬间还会存在正在运行的事务,MYSQL是把这些正在运行的事务ID放入到一个数组中。「数组中最小的事务ID」记为低水位,当前系统中「创建过的事务ID最大值+1」记为高水位。
❝
举个简单的例子。a. 注意一点:获取事务ID与创建数组不是一个原子操作,所以存在事务id为8,然后又存在当前MYSQL中存在活跃事务ID为9 10的事务。
❞b. 事务ID低于低水位那么对于当前事务肯定是可见的,事务ID高于高水位的事务ID值,则对当前事务不可见.
c. 事务ID 位于低水位与高水位之间分为两种情况。如果事务id是在活跃的数组中表示这个版本是正在执行,但是结果还没有提交,所以这些事务的变更是不会让当然事务看到的。 事务id如果没有在活跃数组中,代表这个事务是已经提交了,所以可见。比如现在创建了90,91,92三个事务,91执行的比较快,提交完毕,90和92还没有提交.这时候创建了一个新的事务id为93,那么在活跃的数组中的事务就是90,92,93,你看91是已经提交了,它的事务还在这个低水位与高水位之间,但结果对于93是可见。
总的上面来说就是你在我创建的时候事务结果已经提交,那么是可见的,之后提交那么就是不可见的。
读取流程
上面简单说了下老版本视图中的数据是通过最新的版本与undo log 计算出来的,那到底怎么就算的呢?
| 事务A | 事务B | 结果 |
|---|---|---|
| start transaction with consistent snapshot 事务 id 89 | 开启事务,并创建视图 | |
| -- | start transaction with consistent snapshot 事务id 92 | 开启事务,并创建视图 |
| select score from scors where id =2 | -- | 事务A中的值为3.65 |
| -- | update scores set scores = 10 where id =2 | 事务B修改为10 |
| -- | select score from scores where id =2 | 事务B显示为10 |
| select score from scores where id =2 | -- | 事务A显示为3.65 |
| commit | --- | --- |
还是看这个事务操作。下面是数据变动的流程。
假设开始之前有两个活跃的事务ID为 78,88. 事务A启动的时候会将78 88,包含它自己放入到活跃数组中。 事务A 操作的语句 select score from scors where id =2将其看到的结果认为是v1版本数据比如其现在row trx_id(**注意:**row trx_id是数据行被更新后事务id才会赋值给row trx id上)是86,并且保存好。事务B启动时,会发现在活跃数组是78,88,89,自己的92. 事务B 执行更新语句语句后,会生成一个新的版本V2,数据变换就是V1-->V2。记录中间变化的是「undo log」日志。这样ID 89存储的数据就变成了历史数据。数据版本row trx_id则是92 事务A 查询score数据,就会通过先查到现在的V2版本视图,找到对应的row trx_id = 92,发现row trx_id 位于高水位上,则抛弃这个值,通过V2找到V1,row trx_id为86,而86大于「低水位」,而低于「高水位」89+1.但是由于86没有在活跃数组中,而且属于已经提交的事务,则当前事务是能看到该结果的,所以事务A能拿到读取的值。
你看经过简单的几步,我们就拿到了想要读取的事务数据,所以不论事务A什么时候查询,它拿到的结果都是跟它读取的数据是一致的。
你看有了MVCC(多版本并发控制)计算别的事务更改了值也不会影响到当前事务读取结果的过程。
我们经常说不要写一个长事务,通过上面的读取流程可以看到,长事务存在时间长的话,数据版本就会有很多,那么undo log日志就需要保存好久,这些回滚日志会占用大量的「内存」存储空间。
当没有事务需要读取该日志与版本数据的时候,这个日志才可以删除,从而释放内存空间。
更新流程
| 事务A | 事务B | 结果 |
|---|---|---|
| start transaction with consistent snapshot 事务 id 89 | 开启事务,并创建视图 | |
| -- | start transaction with consistent snapshot 事务id 92 | 开启事务,并创建视图 |
| select score from scors where id =2 | -- | 事务A中的值为3.65 |
| -- | update scores set scores = 10 where id =2 | 事务B修改为10 |
| -- | select score from scores where id =2 | 事务B显示为10 |
| select score from scores where id =2 | -- | 事务A显示为3.65 |
| select score from scores where id =2 for update | -- | 会被锁住,等待事务B释放锁(间隙锁) |
| -- | commit | 提交事务B |
| select score from scores where id =2 for update | -- | 这个语句可以看到变成了10(利用了当前读) |
| select score from scores where id =2 | -- | 不加 for update 那么结果还是3.65 |
| commit | --- | --- |
上面说了读取的过程,其实在事务中,我们还有更新流程,更新流程比较简单,更新过程我们需要保证数据的一致性,不能说别人修改了,我们还看不到,那样就会造成数据的不一致。
为了保证看到最新的数据,会对更新行的操作加锁(行锁),加锁之后,其他事务对行进行更新操作,必须等待其他事务commit之后才能获取到最新的值,这个过程被称为「当前读」。
想要读取过程中获得最新的值可以使用 上面的语句select score from scores where id =2 for update ,就可以看到当前最新值。
总结
本小节主要梳理了事务的隔离级别,事务的MVCC多版本并发控制实现原理。
事务在面试中是比较多的一个点,这样的题目可以多种变换,面试官:说说MySQL的事务隔离?提到的三个问题已经可以解答了。
你来尝试回答下?
下期会说下数据库中的幻读,幻读也是面试中经常遇到的问题哦。
往期文章一览