
原创 | 一张图秒杀滴滴大数据场景题(已拿offer)
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群

大家好,我是峰哥。
之前有同学在微信上问了我滴滴的一个大数据场景题,今天我们就聊聊解决这道题的思路。

在面试中,我们不仅要手写算法,还会碰到一些算法场景题,比如数据量太大,内存完全不够该如何处理,今天我们就结合两个具体问题来探讨一下。
问题一
A 文件有 50 亿条 URL,B 文件也有 50 亿条 URL,每条 URL 大小为 64B,在一台只有 4G 内存的机器上,怎么找出 A、B 中相同的 URL?
不用算都知道内存肯定不够,否则就不会这么问了。面试时,如果对自己的算数能力不够自信,那就直接说出思路,不用计算具体数值,免得尴尬。
针对这种大数据量的问题,通常要想到「分而治之」。为了方便讲解,我这里就先计算一下。
50 亿条 URL 文件的大小:50 * 10^8 * 64 Byte ≈ 32 * 10^10 Byte ≈ 320G
一图胜千言,点击图片即可放大查看。
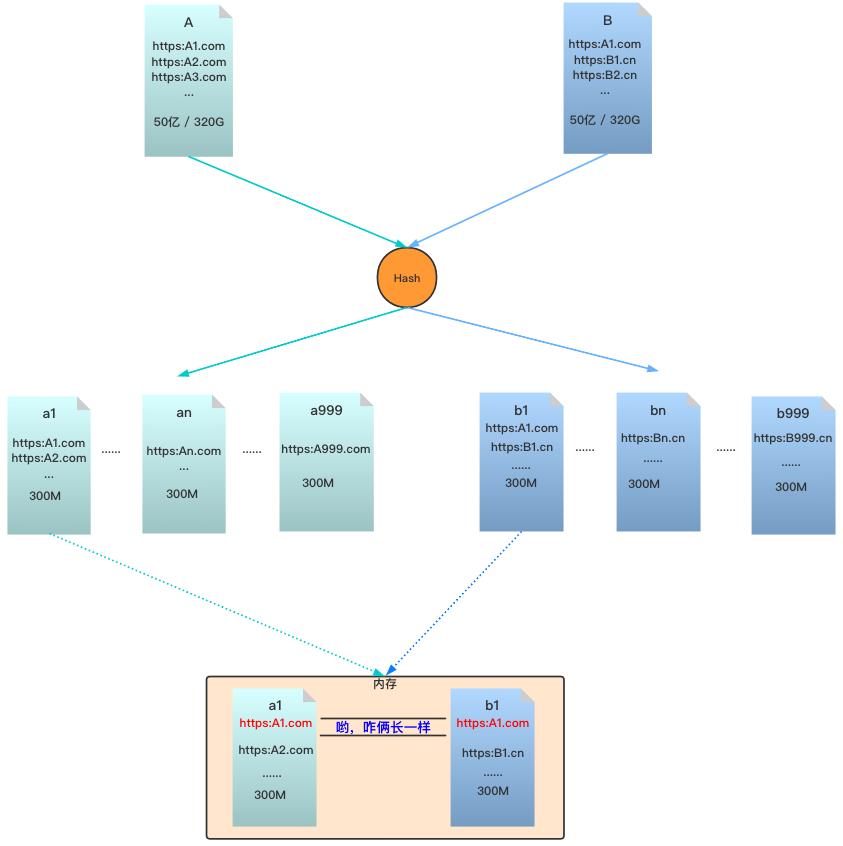
借助 Hash 函数,依次扫描 A、B 两个文件,将 URL 分别存储到 1000 个小文件中,那么每个文件大约 300M,满足内存的需求,文件以 0-999 的数字结尾作为编号,下面说下具体过程。
首先遍历 A 文件,对每个 URL 取 hash(url)%1000 的值,该值就是 URL 要存储到小文件的编号,最终所有 URL 分别存储在 1000 个小文件中,文件名记成以下形式: a0、a1、…、a999。
再遍历 B 文件,用同样的方法将 B 文件的 URL 分别存储在 b0、b1、…、b999 这 1000 个小文件中。
我们知道 Hash 的一个特点:相同的 key,hash 之后的 value 一定是相同的。所以,对于 A、B 文件中相同的 URL,Hash 之后,一定会存储到相同下标的文件中。
如果 Hash 函数设计合理,将数据均匀分散,每个文件大致 300M。
我们再读取相同下标的小文件到内存中,判断是否存在相同的 URL 即可。
是不是 so easy ?
这让我想起极客时间专栏中同样是内存不够的一个问题。
问题二
如何对 10G 的订单数据按照金额排序?
此时要借助桶排序的思想,订单金额一般是在某个范围内,跨度不会太大。先扫描一遍 10G 的订单数据,找出订单金额的范围,再根据范围进行切分,划分到不同的桶。
比如订单金额在 1 到 10万,切分到 100 个桶里,每个桶中保存的金额范围就是 1000,每个桶其实就是一个小文件,给文件编个号,比如 00 文件:1-1000 元,01 文件:1001-2000,以此类推。
假设订单金额比较均匀,那么每个文件大概 100M,每次读取一个文件进行排序即可。文件之间本来就按照金额划分,已经是有序的。最后将划分的小文件按照编号依次写入结果文件中,那么所有订单就按照金额排好序了。
再一图胜千言。
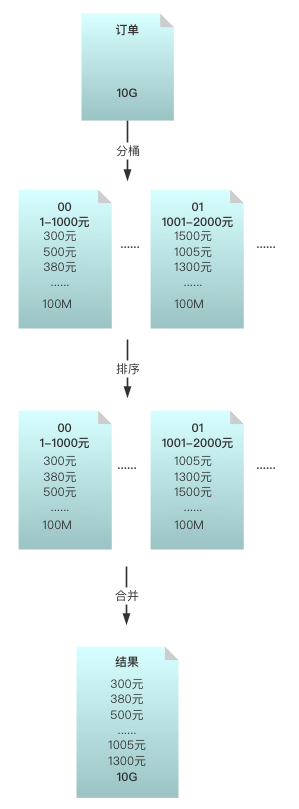
实际情况中,订单金额一般是分布不均匀的,此时针对较大的文件复用上面的方法,划分成更小的文件分别排好序,最后再统一汇总。
通过以上两个问题,我们发现大数据处理的重要思想是「分而治之」,下次碰到这类题目不妨从这个角度出发,即使不能吊打面试官,但也能回答个七七八八。
最后这位同学也不枉峰哥的细心指导,顺利拿下滴滴offer。
·················END·················
你好,我是峰哥,一个骚气的肌肉男。独自穷游过15个国家,60座城市,也是国家级健身教练。
二本车辆工程转型大数据开发,拿过66个大数据offer,现任某知名外企高级数据工程师。
毕业一年,靠自己在上海买房,点此看我2020年总结。为人亲和,欢迎添加我的微信 Fawn0504 进行交流或围观朋友圈。