
【Python】Python正则匹配必须掌握的10个函数
正则表达re模块共有12个函数,我将分类进行讲解,这样方便记忆与理解,先来看看概览:
search、match、fullmatch:查找一个匹配项
findall、finditer:查找多个匹配项
split:分割
sub,subn:替换
compile函数、template函数: 将正则表达式的样式编译为一个 正则表达式对象
print(dir(re))[...... 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall','finditer', 'fullmatch', 'functools', 'match', 'purge', 'search','split', 'sre_compile', 'sre_parse', 'sub', 'subn', 'template']
一、查找一个匹配项
查找并返回一个匹配项的函数有3个:search、match、fullmatch,他们的作用分别是:
search:查找任意位置的匹配项
match:必须从字符串开头匹配
fullmatch:整个字符串与正则完全匹配
1) search()
描述:在给定字符串中寻找第一个匹配正则表达式的子字符串,如果找到会返回一个Match对象,这个对象中的元素可以group()得到(之后将会介绍group的概念),如果没找到就会返回None。调用re.match,re.search方法或者对re.finditer结果进行遍历,输出的结果都是re.Match对象
语法:re.search(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式
re.search(r"(\w)(.\d)","as.21").group()
's.2'
假设返回的Match对象为m,m.group()来取某组的信息,group(1)返回与第一个子模式匹配的单个字符串,group(2)等等以此类推,start()方法得到对应组的开始索引,end()得到对应组的结束索引,span()以元组形式给出对应组的开始和结束位置,括号中填入组号,不填入组号时默认为0。
匹配对象m方法有很多,几个常用的方法如下:
m.start() 返回匹配到的字符串的起使字符在原始字符串的索引
m.end() 返回匹配到的字符串的结尾字符在原始字符串的索引
m.group() 返回指定组的匹配结果
m.groups() 返回所有组的匹配结果
m.span() 以元组形式给出对应组的开始和结束位置
其中的组,是指用()括号括起来的匹配到的对象,比如下列中的"(\w)(.\d)",就是两个组,第一个组匹配字母,第二个组匹配.+一个数字。
m = re.search(r"(\w)(.\d)","as.21")m<re.Match object; span=(1, 4), match='s.2'>m.group()s.2m.group(0)'s.2'm.group(1) #根据要求返回特定子组's'm.group(2)'.2'm.start()1m.start(2)#第二个组匹配的索引位置2m.groups()('s', '.21')m.span()(1, 5)
2) match()
描述:必须从字符串开头匹配,同样返回的是Match对象,对应的方法与search方法一致,此处不再赘述。
语法:re.match(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
#从头开始匹配,返回一个数字,发现报错,无法返回,因为不是数字开头的text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.match(pattern,text).group()AttributeError: 'NoneType' object has no attribute 'group'#从头开始匹配,返回一个单词,正常返回了开头的单词text = 'chi13putao14butu520putaopi666'pattern = r'[a-z]+'re.match(pattern,text).group()'chi'
3) fullmatch()
描述:整个字符串与正则完全匹配,同样返回的是Match对象,对应的方法与search方法一致,此处不再赘述
语法:(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
#必须要全部符合条件才能匹配
re.fullmatch(r'[a-z]+','chiputao14').group()AttributeError: 'NoneType' object has no attribute 'group're.fullmatch(r'[a-z]+','chiputao').group()'chiputao'
二、查找多个匹配项
讲完查找一项,现在来看看查找多项吧,查找多项函数主要有:findall函数 与 finditer函数:
1)findall: 从字符串任意位置查找,返回一个列表
2)finditer:从字符串任意位置查找,返回一个迭代器
两个函数功能基本类似,只不过一个是返回列表,一个是返回迭代器。我们知道列表是一次性生成在内存中,而迭代器是需要使用时一点一点生成出来的,运行时占用内存更小。如果存在大量的匹配项的话,建议使用finditer函数,一般情况使两个函数不会有太大的区别。
1)findall
描述:返回字符串里所有不重叠的模式串匹配,以字符串列表的形式出现。
语法:re.findall(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
import retext = 'Python太强大,我爱学Python'pattern = 'Python're.findall(pattern,text)['Python', 'Python']#找出下列字符串中的数字text = 'chi13putao14butu520putaopi666'#\d+表示匹配任意数字pattern = r'\d+'re.findall(pattern,text)['13', '14', '666', '520']text = 'ab-abc-a-cccc-d-aabbcc'pattern = 'ab*'re.findall(pattern,text)['ab', 'ab', 'a', 'a', 'abb']#找到所有副词'''findall() 匹配样式 所有 的出现,不仅是像 search() 中的第一个匹配。比如,如果一个作者希望找到文字中的所有副词,他可能会按照以下方法用 findall()'''text = "He was carefully disguised but captured quickly by police."re.findall(r"\w+ly", text)['carefully', 'quickly']
2)finditer()
描述:返回一个产生匹配对象实体的迭代器,能产生字符串中所有RE模式串的非重叠匹配。
语法:re.finditer(pattern, string, flags=0)
pattern 匹配的正则表达式
string 要匹配的字符串
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
m = re.finditer("Python","Python非常强大,我爱学习Python")m<callable_iterator at 0x18b5eca58c8>for i in m:print(i.group(0))PythonPython#找到所有副词和位置'''如果需要匹配样式的更多信息, finditer() 可以起到作用,它提供了 匹配对象 作为返回值,而不是字符串。继续上面的例子,如果一个作者希望找到所有副词和它的位置,可以按照下面方法使用 finditer()'''text = "He was carefully disguised but captured quickly by police."for m in re.finditer(r"\w+ly", text):print('%02d-%02d: %s' % (m.start(), m.end(), m.group(0)))07-16: carefully40-47: quic
三、匹配项分割
1)split()
描述:split能够按照所能匹配的字串将字符串进行切分,返回切分后的字符串列表
形式.切割功能非常强大
语法:re.split(pattern, string, maxsplit=0, flags=0)
pattern:匹配的字符串
string:需要切分的字符串
maxsplit:分隔次数,默认为0(即不限次数)
flags:标志位,用于控制正则表达式的匹配方式,flags表示模式,就是上面我们讲解的常量!支持正则及多个字符切割。
正则表达的分割函数与字符串的分割函数一样,都是split,只是前面的模块不一样,正则表达的函数为, ,用pattern分开string,maxsplit表示最多进行分割次数,
re.split(r";","var A;B;C:integer;")['var A', 'B', 'C:integer', '']re.split(r"[;:]","var A;B;C:integer;")['var A', 'B', 'C', 'integer', '']text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.split(pattern,text)['chi', 'putao', 'butu', 'putaopi', '']line = 'aac bba ccd;dde eef,fff'#单字符切割re.split(r';',line)['aac bba ccd', 'dde eef,fff']#两个字符以上切割需要放在 [ ] 中re.split(r'[;,]',line)['aac bba ccd', 'dde eef', 'fff']#所有空白字符切割re.split(r'[;,\s]',line)['aac', 'bba', 'ccd', 'dde', '', '', 'eef', 'fff']#使用括号捕获分组,默认保留分割符re.split(r'([;])',line)['aac bba ccd', ';', 'dde eef,fff']#不想保留分隔符,以(?:...)的形式指定re.split(r'(?:[;])',line)['aac bba ccd', 'dde eef,fff']#不想保留分隔符,以(?:...)的形式指定re.split(r'(?:[;,\s])',line)['aac', 'bba', 'ccd', 'dde', '', '', 'eef', 'fff']
注意:str模块也有一个split函数 ,那这两个函数该怎么选呢?str.split函数功能简单,不支持正则分割,而re.split支持正则。关于二者的速度如何?来实际测试一下,在相同数据量的情况下使用re.split函数与str.split函数执行次数 与 执行时间 对比图:
#运行时间统计 只计算了程序运行的CPU时间,且每次测试时间有所差异
import time#统计次数n = 1000``start_t = time.perf_counter()for i in range(n):re.split(r';',line)##re.splitend_t = time.perf_counter()print ('re.split: '+str(round(1000000*(end_t-start_t),2)))start_t = time.perf_counter()for i in range(n):line.split(';')##str.splitend_t = time.perf_counter()print ('str.split: '+str(round(1000000*(end_t-start_t),2)))
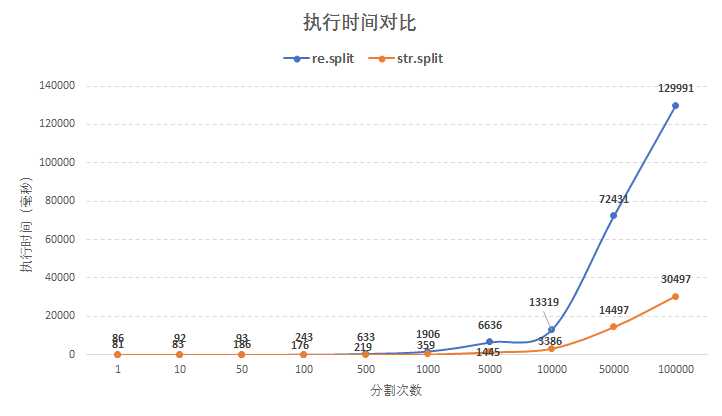
通过上图对比发现,5000次循环以内str.split函数和re.split函数执行时间差异不大,而循环次数1000次以上后str.split函数明显更快,而且次数越多差距越大!
所以结论是,在不需要正则支持的情况下使用str.split函数更合适,反之则使用re.split函数。具体执行时间与测试数据有关!且每次测试时间有所差异
四、匹配项替换
替换主要有sub函数与subn函数两个函数,他们功能类似,不同点在于sub只返回替换后的字符串,subn返回一个元组,包含替换后的字符串和替换次数。
python 里面可以用 replace 实现简单的替换字符串操作,如果要实现复杂一点的替换字符串操作,需用到正则表达式。
re.sub用于替换字符串中匹配项,返回一个替换后的字符串,subn方法与sub()相同, 但返回一个元组, 其中包含新字符串和替换次数。
sub是substitute表示替换。
1)sub
描述:它的作用是正则替换。
语法:re.sub(pattern, repl, string, count=0, flags=0)
pattern:该参数表示正则中的模式字符串;
repl:repl可以是字符串,也可以是可调用的函数对象;如果是字符串,则处理其中的反斜杠转义。如果它是可调用的函数对象,则传递match对象,并且必须返回要使用的替换字符串
string:该参数表示要被处理(查找替换)的原始字符串;
count:可选参数,表示是要替换的最大次数,而且必须是非负整数,该参数默认为0,即所有的匹配都会被替换;
flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
把字符串 aaa34bvsa56s中的数字替换为 *号
import rere.sub('\d+','*','aaa34bvsa56s')#连续数字替换'aaa*bvsa*s're.sub('\d','*','aaa34bvsa56s')#每个数字都替换一次'aaa**bvsa**s'#只天换一次count=1,第二次的数字没有被替换re.sub('\d+','*','aaa34bvsa56s',count=1)'aaa*bvsa56s'把chi13putao14butu520putaopi666中的数字换成...text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.sub(pattern,'...',text)'chi...putao...butu...putaopi...'关于第二个参数的用法,我们可以看看下面的内容#定义一个函数def refun(repl):print(type(repl))return('...')re.sub('\d+',refun,'aaa34bvsa56s')<class 're.Match'><class 're.Match'>'aaa...bvsa...s'从上面的例子看来,似乎没啥区别原字符串中有多少项被匹配到,这个函数就会被调用几次。至于传进来的这个match对象,我们调用它的.group()方法,就能获取到被匹配到的内容,如下所示:def refun(repl):print(type(repl),repl.group())return('...')re.sub('\d+',refun,'aaa34bvsa56s')<class 're.Match'> 34<class 're.Match'> 56Out[113]: 'aaa...bvsa...s'这个功能有什么用呢?我们设想有一个字符串moblie18123456794num123,这个字符串中有两段数字,并且长短是不一样的。第一个数字是11位的手机号。我想把字符串替换为:moblie[隐藏手机号]num***。不是手机号的数字,每一位数字逐位替换为星号。def refun(repl):if len(repl.group()) == 11:return '[隐藏手机号]'else:return '*' * len(repl.group())re.sub('\d+', refun, 'moblie18217052373num123')'moblie[隐藏手机号]num***'
2)subn
描述:函数与 re.sub函数 功能一致,只不过返回一个元组 (字符串, 替换次数)。
语法:re.subn(pattern, repl, string, count=0, flags=0)
参数:同re.sub
re.subn('\d+','*','aaa34bvsa56s')#连续数字替换('aaa*bvsa*s', 2)re.subn('\d','*','aaa34bvsa56s')#每个数字都替换一次('aaa**bvsa**s', 4)text = 'chi13putao14butu520putaopi666'pattern = r'\d+'re.subn(pattern,'...',text)('chi...putao...butu...putaopi...', 4)
五、编译正则对象
描述:将正则表达式的样式编译为一个正则表达式对象(正则对象),可以用于匹配
语法:re.compile(pattern, flags=0)
参数:
pattern:该参数表示正则中的模式字符串;
flags:可选参数,表示编译时用的匹配模式(如忽略大小写、多行模式等),数字形式,默认为0。
prog = re.compile(pattern)result = prog.match(string)等价于result = re.match(pattern, string)
如果需要多次使用这个正则表达式的话,使用re.compile()和保存这个正则对象以便复用,可以让程序更加高效。
六、转义函数
re.escape(pattern) 可以转义正则表达式中具有特殊含义的字符,比如:. 或者 * re.escape(pattern) 看似非常好用省去了我们自己加转义,但是使用它很容易出现转义错误的问题,所以并不建议使用它转义,而建议大家自己手动转义!
七、缓存清除函数
re.purge()函数作用就是清除正则表达式缓存,清除后释放内存。
··· END ···
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码