九月份的时候胡萝卜参加了讯飞的人岗匹配挑战赛,后面机缘巧合和老肥组队打团。比赛过程可谓跌宕起伏,非常有意思。在这里和大家分享一下我们的建模方案。
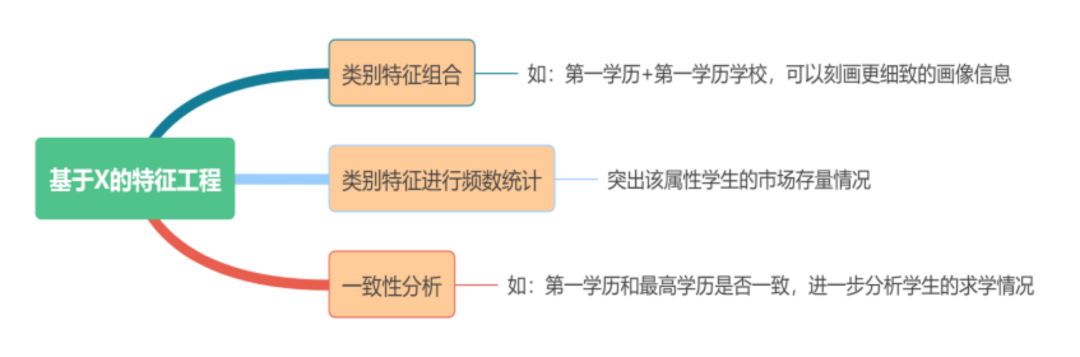
智能人岗匹配需要强大的数据作为支撑,本次大赛提供了大量的岗位JD和求职者简历的加密脱敏数据作为训练样本,参赛选手需基于提供的样本构建模型,预测简历与岗位匹配与否。实质上,可以看做一个多分类问题。本次比赛为参赛选手提供了大量的岗位JD和求职者简历,其中:岗位JD数据包含4个特征字段:job_id, 职位名称, 职位描述, 职位要求。求职者简历数据包含15个特征字段:id, 学校类别, 第一学历, 第一学历学校, 第一学历专业, 最高学历, 最高学历学校, 最高学历专业, 教育经历, 学术成果, 校园经历, 实习经历, 获奖信息, 其他证书信息, job_id。这里面的数据都是加密脱敏的,不太会bert的我们只能说:xgb/lgb yyds!本模型依据提交的结果文件,采用macro-F1 score进行评价。1 模型有lgb和xgb,其中xgb要比lgb效果好!!!!3 特征工程包括业务特征如下图,还有一些类别特征之间count、nunique和count/nunique计算,以及计算个人信息与每一个职位之间的余弦相似度(个人信息=学校类别+教育经历+学术成果+校园经历+实习经历+获奖信息+其他证书信息,职位信息=职位名称+职位描述+职位要求,采用TFIDF(2-gram)算法处理),人个信息用TFIDF(2-gram)进一步处理生成文本特征矩阵。4 个人信息生成的文本特征矩阵非常高维,降维处理会降低精度,不降维训练时间长,需要人工调整min_df和max_df参数。5 结果概率后处理提分,老肥神操作,看不懂!知乎的包包大人有关于这方面的详细解答,详见https://zhuanlan.zhihu.com/p/106766826。写在末尾,数据挖掘一些的tricks基本有用,关键是多做特征和多尝试。温馨提示:如果你觉得离冠军很远,直接艾特前排冠军组队就好。感谢胡萝卜同学的精彩分享,如果还有同学想要分享比赛相关内容的,可以在群内或者私聊戳我,大家一起交流学习!
 下载APP
下载APP