
CVPR 2021 | 视觉推理解释框架VRX:用结构化视觉概念作为解释网络推理逻辑的「语言」

极市导读
这项工作对神经网络推理逻辑的可解释性进行了探究:区分于大多数现有xAI方法通过可视化输入图像和输出结果之间的相关性对网络进行解释,本文提出用结构化的视觉概念对神经网络决策背后的推理逻辑和因果关系进行解释。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文主要介绍我们被 CVPR 2021 会议录用的一篇文章:A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts
文章链接:https://arxiv.org/pdf/2105.00290.pdf
项目主页:http://ilab.usc.edu/andy/vrx
代码:https://github.com/gyhandy/Visual-Reasoning-eXplanation
视频讲解:https://www.bilibili.com/video/BV1tb4y1C7yY/
这项工作对神经网络推理逻辑的可解释性进行了探究:区分于大多数现有xAI方法通过可视化输入图像和输出结果之间的相关性对网络进行解释,我们提出用结构化的视觉概念 (Structural Visual Concept) 对神经网络决策背后的推理逻辑和因果关系进行解释,通过解答网络决策中“为什么是A,为什么不是B?”的问题,用人们更容易理解的high-level视觉概念和视觉概念之间的结构和空间关系解释神经网络的推理逻辑,并将其作为指导来提升被解释网络的性能。
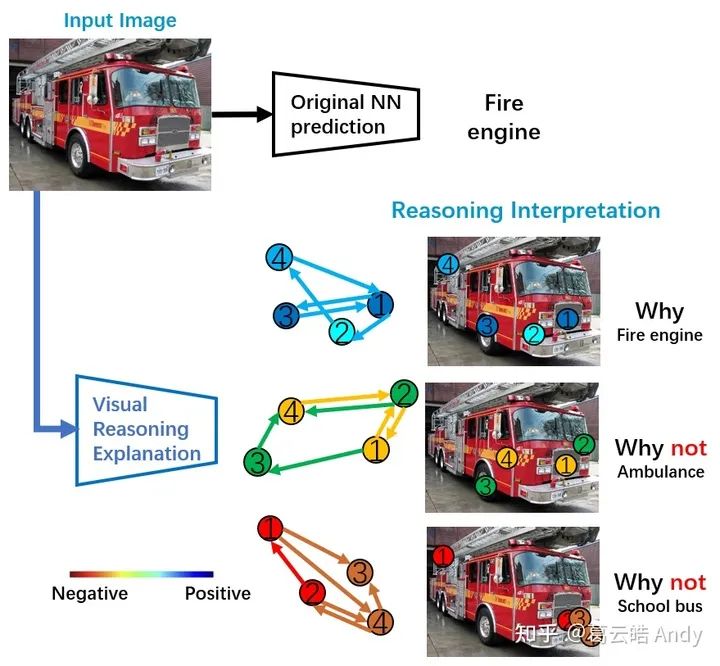
下面一张图概括我们做的事情:为了解释原网络决策背后的推理逻辑,我们回答如下问题:为什么是消防车?为什么不是救护车?又为什么不是校车?
我们用结构化的视觉概念图(Structural Concept Graph) 作为解释的语言,其中概念图的点 (node) 代表视觉概念(visual concept),边 (edge) 代表视觉概念之间的结构和空间关系,点和边的颜色代表其对该类最终决策的贡献度(冷色:正向 或 暖色:负向):为什么是消防车?从视觉概念角度,所有检测到的四个与消防车最相关的视觉概念(保险杠,消防车头,车轮,救援架)都对最终消防车的决策有正向贡献;从视觉概念的空间结构关系角度,四个概念之间的空间关系也都对决策有正向贡献,这说明视觉概念和他们之间的关系都像一辆消防车。
为什么不是校车?从视觉概念角度:从图中检测到的与校车视觉概念最接近的四个部分及其相关结构和空间关系都对校车的决策起到负向贡献(否定该图是校车的决策)尤其是概念1和概念2,与真正的校车概念最不相符。为什么不是救护车也同样可以得到相似的人们容易理解的,逻辑上的,视觉概念角度的解释。
下面将详细介绍工作的具体内容。
1 Motivation (研究动机)
在深度学习日益蓬勃发展的今天,深度神经网络不透明的决策导致的安全事故和隐患也越来越多,神经网络的可解释性对于人们如何更加信任,安全,可靠的使用他们至关重要。
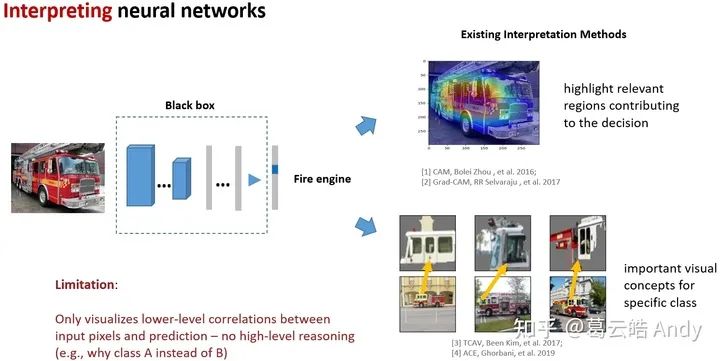
近年来有越来越多关注可解释性的研究,例如 pixel-level 的方法 (CAM[1]Grad-CAM[2]等) 通过可视化输入图像和输出结果之间的相关性解释网络的决策,为理解神经网络决策依据找到了线索;concept-level 的方法 (TCAV[3]ACE[4]等) 可以找到对用给定类别重要的视觉概念。
然而,这些方法是否局限于解释相对low-level的相关性?是否有更加方便人们理解的更直观的high-level的解释方法?我们是否可以揭示神经网络内在的推理逻辑和因果关系?逻辑解释能否作为线索进一步帮助提高原网络的性能?
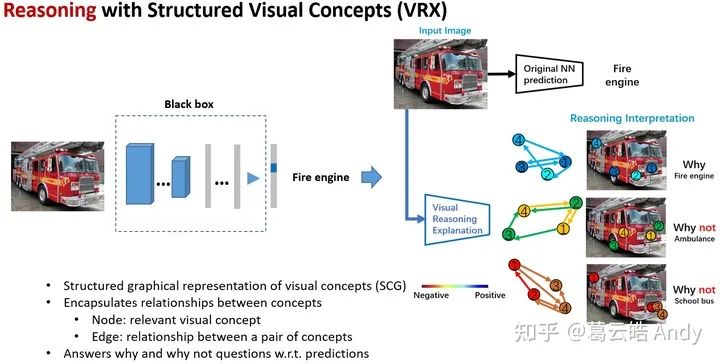
为了回答这些问题,我们探究如何模拟和解释神经网络的推理逻辑,提出用结构化的视觉概念对神经网络决策背后的推理逻辑和因果关系进行解释,通过解答网络决策中“为什么是A,为什么不是B?”的问题,用人们更容易理解的high-level视觉概念和视觉概念之间的关系解释神经网络的推理逻辑,并将其作为指导来提升原网络的性能。
2 Method (方法详述)
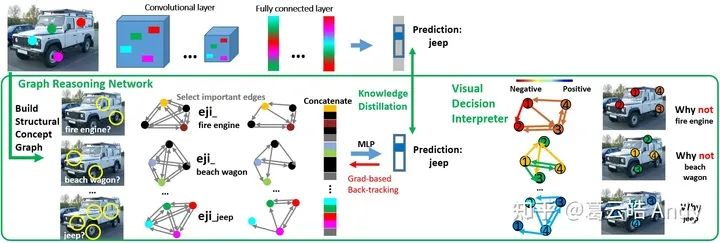
我们提出的视觉推理解释框架(VRX:Visual Reasoning eXplaination Framework)包括三个主要部分:
(1) 视觉概念提取器 (VCE: Visual Concept Extractor) 用来提取特定类别相关的重要视觉概念,并将图像表示为结构化的视觉概念图 (SCG: Structural Concept Graph);
(2) 概念图推理网络 (GRN: Graph Reasoning Network) 以视觉概念图为输入,通过知识蒸馏和迁移来模拟原网络的决策过程;
(3) 可视化决策解释器 (VDI: Visual Decision Interpreter) 用来解释原网络决策背后的推理逻辑和因果关系。接下来我们对每个部分进行详细解释。
2.1 视觉概念提取器 和 结构化的视觉概念
我们首先介绍一下什么是视觉概念 (Visual Concept),简单来说视觉概念展示了给定神经网络对不同类别的理解,同时人们也更容易接受符合直觉的概念级别的解释:以下图警车为例,在给定的神经网络“眼里”,警车Top2重要的视觉概念可视化为最右边绿色圈中的patch (看起来像轮子和驾驶室侧面)。ACE[4]中作者对视觉概念进行了定义:类别相关的视觉概念是像素点的集合 (group of pixels) 并满足以下三个要求:
(1) 有意义 (Meaningfulness):即视觉概念需要具有语义上的涵义,单个的像素就没有语义涵义,所以需要是像素点的集合,比如图片patch。
(2) 一致性 (Coherency):同一视觉概念在不同图片中的表现应该相似,不同视觉概念之间应该不同。
(3) 重要性 (Importance):如果一个视觉概念的存在对于该类样本的真实预测是必要的,那么它对于该类的预测就是“重要的”。
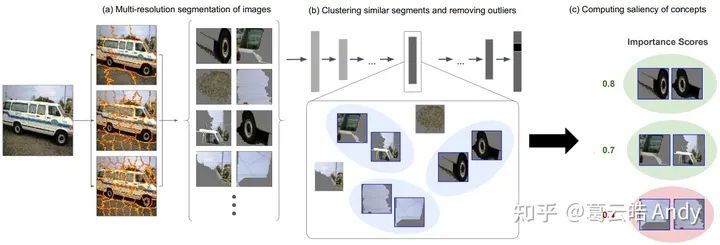
下图描述了ACE中对给定网络,给定类别的视觉概念的提取过程:
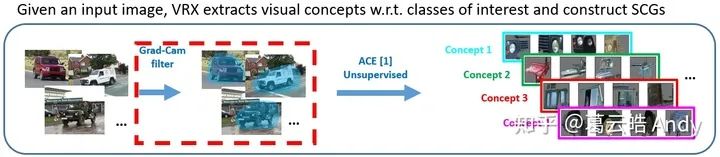
以警车为例,首先(a) 用多分辨率的分割算法对图片进行分割得到patch(这里的分割采用的是SLIC[5],一种基于规则的分割算法,选择该方法是对于其速度和效果的综合考虑); 然后(b)将分割得到的patch resize 为统一大小,通过给定网络将patch 转化为向量,并在向量空间做聚类; 最后(c) 利用 Testing with Concept Activation Vectors (TCAV) [3]得到每个聚类得到的潜在视觉概念对警车类别的重要性分数,并剔除outlier,留下对警车类别来说最重要的 top 视觉概念。
但是我们发现,ACE 提取concept的效果非常依赖用于提取concept的图片的质量,一般每一类选取50~100张左右的图片用于提取concept,如果图片有一些bias或者不是很具有代表性,就会导致很多提取的concept落在背景区域,比如下图(左),这些concept并不能代表网络学习了该类1000张图像(ImageNet)以后对该类(救护车)的理解。
为了解决这个问题,我们提出使用自顶向下的梯度注意力 (Attention Map) 对concept提取区域进行约束, 因为Grad-CAM 的attention map可以帮助我们高亮出对网络决策重要的区域(多为前景),这样可以帮助剔除掉提取concept图片中与类别无关的背景部分,使得提取的concept更能代表原网络对该类的理解,如下图右。

下图中吉普车类别为例,总结了视觉概念提取器提取视觉概念的步骤。
提取出类别相关的视觉概念后,我们认为视觉概念之间有潜在的空间结构关系,这种空间关系对类别表达至关重要:比如我们并不能说,只要能在图像中检测到吉普车的四个最重要的视觉概念就代表一定是吉普车,他们之间的空间关系是相对确定的,例如轮子不能在车顶上方。
我们人类做决策也是相似的:我们认为这是一辆吉普车,不仅关键的特征(视觉概念)符合认知,特征之间的空间关系同样会影响我们的推理和最终决策。因此我们认为结构化的视觉概念 才是更符合人们直觉的,解释神经网络推理决策的重要“语言”。我们后续的模拟并解释神经网络的推理决策过程也是基于此展开的。
结构化视觉概念的一种表达便是结构概念图 (SCG: Structural Concept Graph),graph中不同颜色的点代表不同重要性 (Top k) 的视觉概念,边代表视觉概念之间的空间关系。
如下图吉普车和斑马的例子,我们可以把任意图片表达为对应类别的结构概念图。note:目前是image-level 的 SCG (I-SCG),后续我们会用 基于learning 的方法,学习到class-level 的 SCG(c-SCG).

2.2 概念图推理网络 (GRN: Graph Reasoning Network)
有了结构概念图作为人们容易理解的,解释神经网络的“语言”,接下来我们便用这种“语言”解释神经网络决策背后的推理逻辑。ACE[4]的作者为了验证提取到的视觉概念对神经网络决策的重要性,实验验证发现:如果只保留输入图片中表达重要视觉概念的像素(mask 掉与重要视觉概念无关的区域),神经网络能保留原本80%以上的准确率。因此一个比较直接的想法便是:我们能不能追踪并可视化神经网络决策过程中重要视觉概念相关feature的流动,这样我们便能找到最终决策与重要视觉 concept 之间的关系,从而对决策进行解释。
以下图为例对于一个经典的由卷积层和全连接层构成的神经网络,我们用不同的颜色代表 jeep 最重要的四个concept,在卷积层,我们可以根据结构不变性 tracking 每个 concept 对应的representation feature。但是全连接层中,所有 feature 耦合到了一起,使得追踪变得困难。我们分析这是由于神经网络结构上信息流动不够透明和难以解耦导致的,与此同时我们想到另一种解决办法:如果我们可以用另一个结构比较解耦的,信息流动更加透明的模型B,全方位模拟原始神经网络A的推理和决策,是不是就可以通过解释B的推理逻辑来解释A呢?
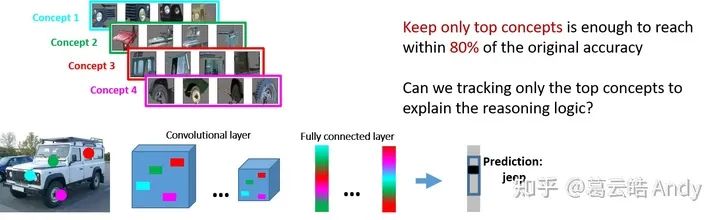
为此我们提出概念图推理网络 (GRN: Graph Reasoning Network),以结构概念图为输入,通过知识蒸馏和迁移来模拟原网络的决策过程(如下图)。
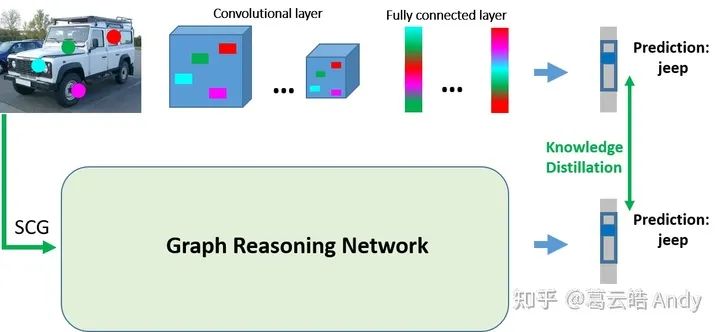
下图解释了概念图推理网络的训练过程:对于输入图片,我们首先构建对于每个感兴趣类别的结构概念图(即先将图像进行分割,然后在所有patch中分别检测每个感兴趣类别的重要视觉概念:从下图中检测到2个消防车的视觉概念(黄色圆圈),2个老爷车的视觉概念 ... 4个吉普车的视觉概念),这些检测到的视觉概念组成相应类别的结构概念图,表示对其决策的假设(该图是消防车吗?是老爷车吗 ... 是吉普车吗?)很多类别我们只能检测到部分视觉概念,检测不到的视觉概念我们用dummy node来表示(黑色node)。
然后概念图推理网络利用图卷积,对每一个结构概念图进行representation,学习其视觉概念及其之间的关系对最终决策的影响。
最后我们把所有点和边 concatenate 为一个向量, 通过非常简单的 MLP 输出对所有感兴趣类别的决策向量,我们用知识蒸馏的方法使得概念图推理网络与原网络的决策一致。
为了提升模拟的鲁棒性,我们还用mask out concept 添加扰动的方法使得概念图推理网络与被解释的原网络在面对扰动时决策一致。(详细训练过程和公式推导请见原始paper)。
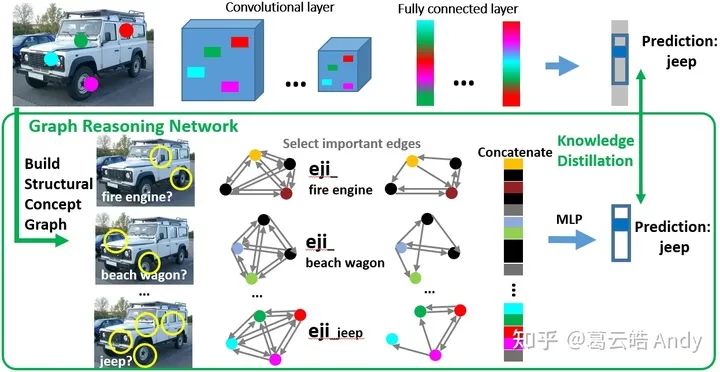
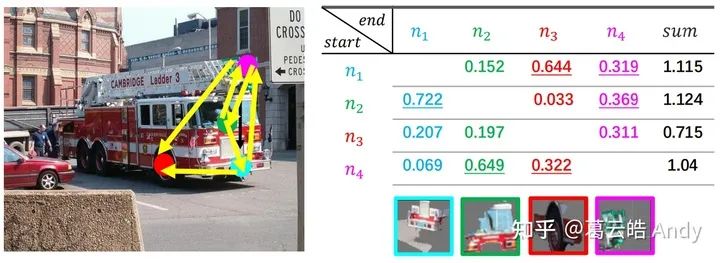
训练中,所有类别的结构概念图共享一套图卷积的参数,但是每个类别在 message passing 中有专属的注意力权重参数 eji,类别专属的注意力权重参数是为了学习每个类别独特的视觉概念之间的空间和依赖关系,一方面可以解释并可视化概念图推理网络学习到的每个类别视觉概念之间潜在的关系(下图),另一方面为最终推理过程的解释提供了支持。
下图是用学习到的消防车的 eji 筛选出重要的视觉概念之间的关系。边的 eji 值越大,代表点 j 对点 i 的贡献越大;从右边的 sum 可以看到消防车的视觉概念 1 和 2 对其他的视觉概念贡献最大,这也意味着他们是对消防车来说最有区分度的视觉概念。
2.3 可视化决策解释器 (VDI: Visual Decision Interpreter)
训练好的概念图推理网络便是原网络的 representation,基于图卷积神经网络的概念图推理网络具有信息传递透明且容易追踪的特点,为了用结构概念图对推理过程进行解释,我们提出了基于梯度的贡献度分配算法,为每个参与决策的点(视觉概念)和边(概念之间的关系)计算其对于特定决策的贡献值,贡献值的高低代表了其肯定还是否定了该决策。最后决策解释器可视化了对原网络输出的解释并回答 why jeep? why not others?(颜色代表肯定:冷色,或否定:暖色)如下图右:why jeep?从视觉概念角度,所有检测到的四个与吉普车最相关的视觉概念(前灯,挡风玻璃,后窗,车轮)都对最终吉普车的决策有正向贡献(深蓝或浅蓝);从视觉概念的空间结构关系角度,四个概念之间的空间关系也都对决策有正向贡献,这说明视觉概念和他们之间的关系都像一辆吉普车。为什么不是消防车?从视觉概念角度:从图中检测到的与消防车视觉概念最接近的四个部分及其相关结构和空间关系都对消防车的决策起到负向贡献(否定该图是消防车的决策)尤其是概念1和概念2,与真正的消防车概念最不相符。为什么不是老爷车等也同样可以得到相似的人们容易理解的,逻辑上的,视觉概念角度的解释。
3 Experiments and results (实验和结果)
3.1 视觉推理解释 (VRX) 与原网络之间逻辑一致性实验
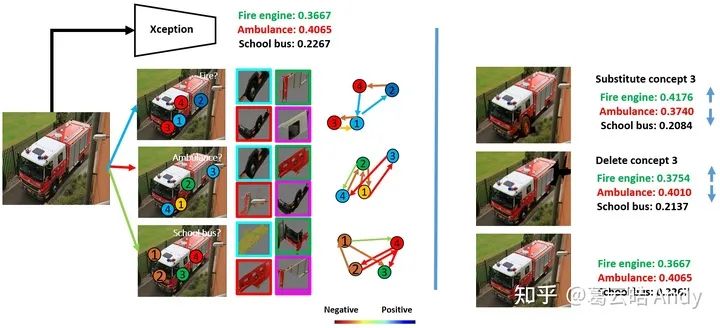
第一个实验目的是验证视觉推理解释框架 (VRX) 做出的推理解释与原网络的逻辑是一致的。如下图,原网络 Xception 错把一张消防车分类成了救护车,VRX给出解释(如左图):为什么不是消防车?因为从图像中检测到的消防车的视觉概念3 和 4 都对消防车的决策起到负向贡献即否定该决策。为什么是救护车?因为检测到的救护车的视觉概念3 和 4 都对救护车的决策起到正向贡献,即肯定该决策。即使所有消防车视觉概念之间的空间关系(边)相对救护车的空间关系更加合理,但是综合来看,Xception还是做出了救护车的决策。
为了验证解释的合理性以及与原网络决策逻辑的一致性。我们做两个实验 :
(1)我们把原图中检测到的对消防车决策起负向作用的消防车的概念 3 (车轮) 替换为另外一张消防车图片中的更合理的概念3 (右图第一行),然后让 Xception 对新的图片再次分类,发现错误被纠正了。我们也做了对比试验:如果我们用一张随机的消防车的 patch 去替换概念3,或者用另外一张消防车的同样合理的概念1 和 2 替换 原始的概念1和2,Xception都无法纠正错误。所以我们认为 VRX 对 Xception 推理的解释符合原网络的逻辑。
(2)我们把原图中检测到的对救护车的决策起正向作用的救护车的概念3 mask 掉,发现 Xception 对新图片的预测结果有纠正的趋势(消防车概率增大,救护车概率减小)。对比试验发现如果随机删除 patch 则不会有纠正的效果。
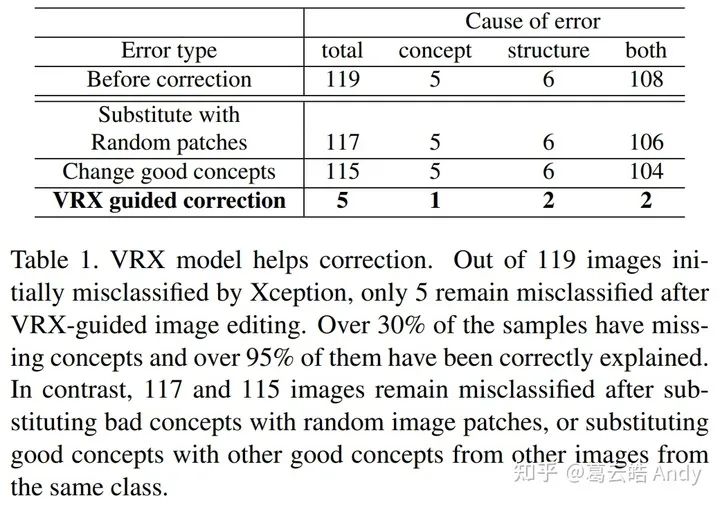
上述验证实验我们一共在119张 Xception 错分的图片中实施,我们用 VRX 对错误原因背后推理逻辑的解释作为修改建议,通过视觉概念的替换和删除,原网络超过95%的错分可以被正确的纠正(如下表1)。
3.2 VRX对视觉和结构解释的敏感性实验(Sensitivityof Appearance and Structures)
VRX 可以从视觉概念(点)和视觉概念之间的空间关系(边)两个角度为决策提供解释。我们通过添加扰动,分别预设输入图像的视觉层面不合理和空间结构的不合理,探究 VRX 的解释对视觉和结构的敏感性。
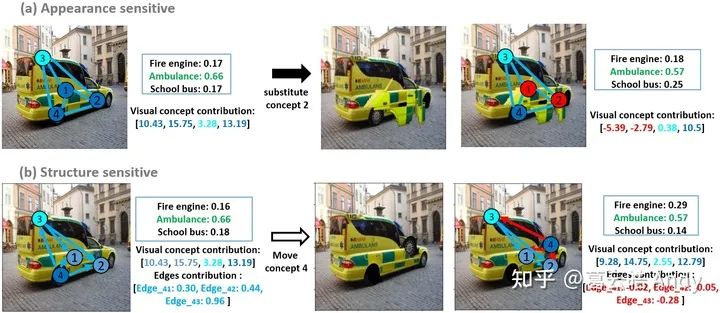
给定一张 Xception 正确预测的救护车图片,VRX可以给出了解释。
(a)如果我们把一个救护车相对合理的视觉概念2(对救护车决策起到正向贡献)替换为一个相对不合理的视觉概念2(在另一张救护车图像中对决策起到负向贡献),VRX对新图片决策的解释可以正确捕捉到不合理的部分:被替换的概念2。
(b)如果我们把视觉概念4(车轮)移动到一个不合理的位置(挡风玻璃上方),VRX对新图片决策的解释可以正确捕捉到不合理的部分:概念4和其他concept之间的空间关系。由此我们认为 VRX 可以准确的定位视觉和结构的不合理,并给出准确的解释。
3.3 VRX 根据解释对原网络进行诊断并提升原网络的表现 (Model diagnosis with VRX)
之前的实验展示了VRX 对原网络的解释可以帮助原网络纠正对图片的错误分类,接下来的实验中,VRX将利用可解释性对原网络进行诊断,发现原网络训练中存在的问题(比如训练数据 的bias),从而提出针对性修改建议,进而提升原网络的表现。
如下图,我们用Resnet-18 训练了一个三种车辆的分类器 ,(a) 训练数据有pose的bias,所有的公共汽车都是pose 1,所有坦克都是pose 2,所有军用汽车都是 pose 3;但测试数据没有pose bias,即所有车辆都有全部的pose 1,2 和3。(b) 测试发现分类器的准确率较低,我们用 VRX 对模型进行诊断,发现大部分错分的图像其实都能找到正确的视觉概念,错误原因是因为概念之间的关系否定了正确的决策,导致错分。
以下图 (b) 为例,一辆军用汽车被错分为坦克,解释为什么不是军用汽车的时候发现是军用汽车视觉概念之间的空间关系否定了该图是军用汽车的决策,而从图中检测到的坦克的视觉概念虽然较差,但是空间关系支持是坦克的决策,综合以上导致了错分。所以 VRX 诊断给出的建议是增加视觉概念之间空间关系的多样性和鲁棒性 。

根据诊断建议,最直接的实现方法便是增加不同pose的图片,我们做了接下来的验证实验:setting 1:为每类增加150张不同于原始数据集pose的图片;setting 2:为每类增加150张与原始数据集pose相同的图片(对照组)。我们用新的数据集分别重新训练了Resnet-18分类器并测试数据集准确率 (结果如下表2)。VRX根据解释性的诊断帮助提升了原始模型的效果。

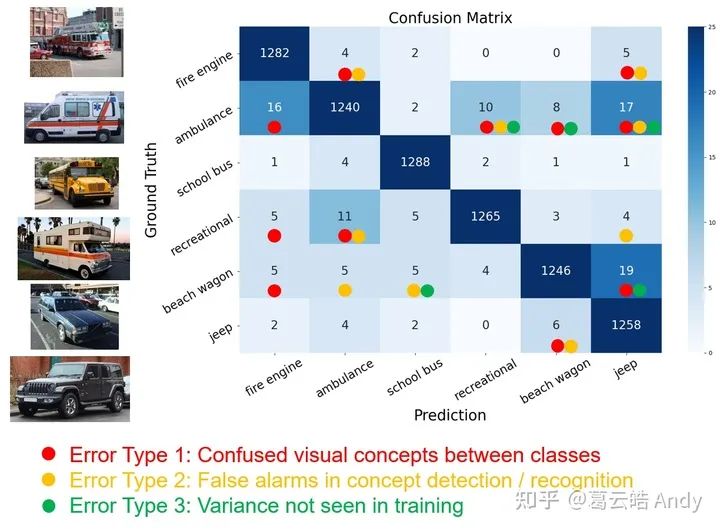
VRX对原模型的诊断可以总结模型的不同问题并提出相应提升建议。下图是 VRX 对在 ImageNet 上预训练的 Xception 其中六类的诊断,VRX 将其错误总结为三种类别,并对每种错误的修改提出建议。(细节请参考原paper)
4 Conclusion (总结和展望)
总结来说,这项工作在神经网络的可解释性方向做了进一步探索:解释神经网络决策背后的推理逻辑。我们提出了一个视觉推理解释框架 (VRX: Visual Reasoning eXplanation), 将人们容易理解的,high-level 的结构化的视觉概念作为“语言”,通过回答为什么是A,为什么不是B 解释神经网络的推理逻辑。VRX 还可以利用解释对网络进行诊断,进一步提升原网络的性能。我们相信这是朝着更透明,更安全,更可信的 AI 方向迈出的小但是重要的一步。
更多细节请参考原paper,欢迎大家follow我们的工作:)
title={A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts},author={Ge, Yunhao and Xiao, Yao and Xu, Zhi and Zheng, Meng and Karanam, Srikrishna and Chen, Terrence and Itti, Laurent and Wu, Ziyan},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},pages={2195--2204},year={2021}}
如果有任何问题,欢迎大家留言或者给我发邮件讨论,最后附上我的主页链接:
https://gyhandy.github.io/
参考
^CAM, Bolei Zhou , et al. 2016 https://openaccess.thecvf.com/content_cvpr_2016/papers/Zhou_Learning_Deep_Features_CVPR_2016_paper.pdf ^Grad-CAM, RR Selvaraju , et al. 2017 https://arxiv.org/pdf/1610.02391.pdf ^TCAV, Been Kim, et al. 2017; https://arxiv.org/pdf/1711.11279.pdf ^ACE, Ghorbani, et al. 2019 https://arxiv.org/pdf/1902.03129.pdf ^SLIC, Radhakrishna Achanta, et al. 2011 https://core.ac.uk/download/pdf/147983593.pdf
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标跟踪”获取目标跟踪综述~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
