
【万字长文】帮助小白快速入门 Spark
大家好,我是Tom哥
互联网时代,随着业务数据化,数据越来越多。如何用好数据,做好数据业务化,我们需要有个利器。
很多人都用过Hadoop,包含两部分 HDFS 和 MapReduce,其中 MapReduce 是Hadoop的分布式计算引擎,计算过程中需要频繁落盘,性能会弱一些。
今天,带大家 快速熟悉一个大数据框架,Spark
Spark 是内存计算引擎,性能更好一些。盛行自 2014年,支持 流计算 Streaming、数据分析 SQL、机器学习 MLlib、图计算 GraphFrames 等多种场景。
语言支持很多,如 Python、Java、Scala、R 和 SQL。提供了种类丰富的开发算子,如 RDD、DataFrame、Dataset。
有了这些基础工具,开发者就可以像搭乐高一样,快速完成各种业务场景系统开发。
一、先来个体感
首先,我们看一个简单的代码示例,让大家有个体感
import org.apache.spark.rdd.RDD
val file: String = "/Users/onlyone/spark/demo.txt"
// 加载文件
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
wordCounts.foreach(wordCount => println(wordCount._1 + " appeared " + wordCount._2 + " times"))
我们看到,入口代码是从第四行的 spark 变量开始。
在 spark-shell 中 由系统自动创建,是 SparkSession 的实例化对象,可以直接使用,不需要每次自己 new 一个新对象。
SparkSession 是 Spark 程序的统一开发入口。开发一个 Spark 应用,必须先创建 SparkSession。
二、RDD
弹性分布式数据集,全称 Resilient Distributed Datasets,是一种抽象,囊括所有内存和磁盘中的分布式数据实体,是Spark最核心的模块和类。
RDD 中承载数据的基本单元是数据分片。在分布式计算环境中,一份完整的数据集,会按照某种规则切割成多份数据分片。这些数据分片被均匀地分发给集群内不同的计算节点和执行进程,从而实现分布式并行计算。
RDD 包含 4大属性:
数据分片,partitions 分片切割规则, partitioner RDD 依赖关系, dependencies 转换函数,compute
RDD 表示的是分布式数据形态,RDD 到 RDD 之间的转换,本质上是数据形态上的转换,这里面的一个重要角色就是算子。
三、算子
算子分为两大类,Transformations 和 Actions
Transformations 算子:通过函数方法对数据从一种形态转换为另一种形态 Actions 算子:收集计算结果,或者将数据物化到磁盘 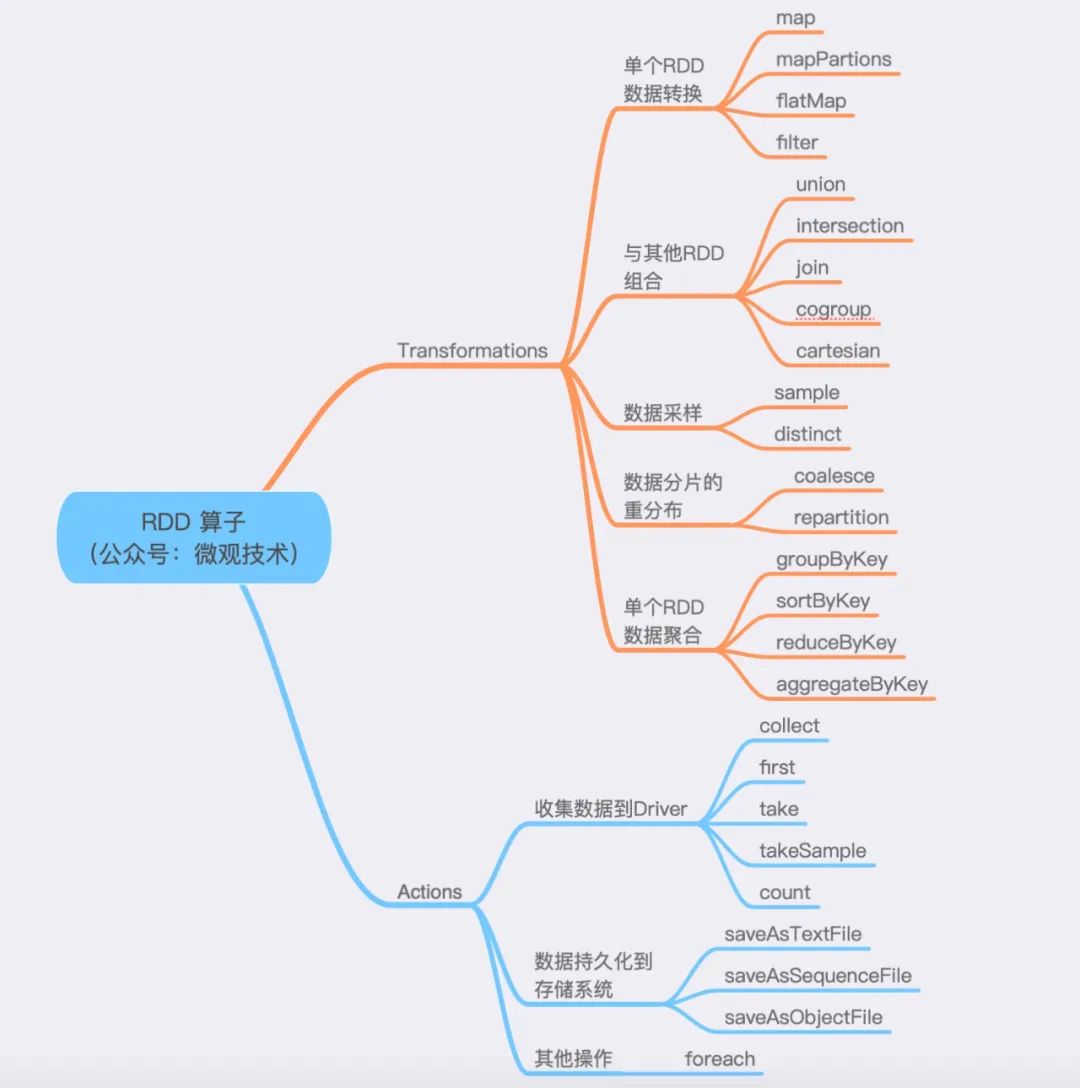
划重点:mapPartitions 与 map 的功能类似,但是mapPartitions 算子是以数据分区为粒度初始化共享对象,比如:数据库连接对象,S3文件句柄等
结合上面的两类算子,Spark 运行划分为两个环节:
不同数据形态之间的转换,构建计算流图 (DAG) 通过 Actions 类算子,以 回溯的方式去触发执行这个计算流图
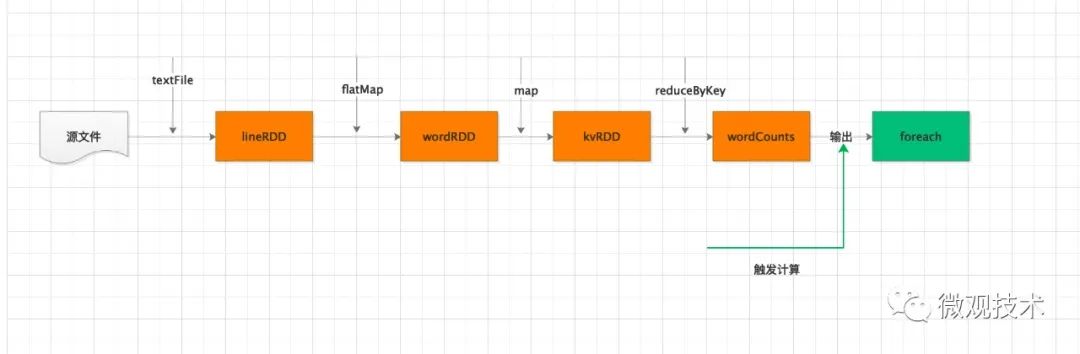
题外话,回溯在Java 中也有引入,比如 Stream 流也是类似机制
一个流程可能会引入很多算子,但是他们并不会立即执行,只有当开发者调用了 Actions 算子,之前调用的转换算子才会执行。这个也称为 延迟计算
延迟计算是 Spark 分布式运行机制的一大亮点。可以让执行引擎从全局角度来优化执行流程。
四、分布式计算
Spark 应用中,程序的入口是带有 SparkSession 的 main 函数。
SparkSession 提供了 Spark 运行时的上下文,如 调度系统、存储系统、内存管理、RPC 通信),同时为开发者提供创建、转换、计算分布式数据集的开发 API。
运行这个 SparkSession 的main函数的JVM进程,我们称为 Driver。
Driver 职责:
解析用户代码,构建 DAG 图,然后将计算流图转化为分布式任务,将任务分发给集群的 Executor 执行。定期与每个 Executor 通信,及时获取任务的进展,从而协调整体的执行进度。
Executors 职责:
调用内部线程池,结合事先分配好的数据分片,并发地执行任务代码。每个 Executors 负责处理 RDD 的一个数据分片子集。
分布式计算的核心是任务调度,主要是 Driver 与 Executors 之间的交互。
Driver 的任务调度依赖于 DAGScheduler、TaskScheduler 和 SchedulerBackend。
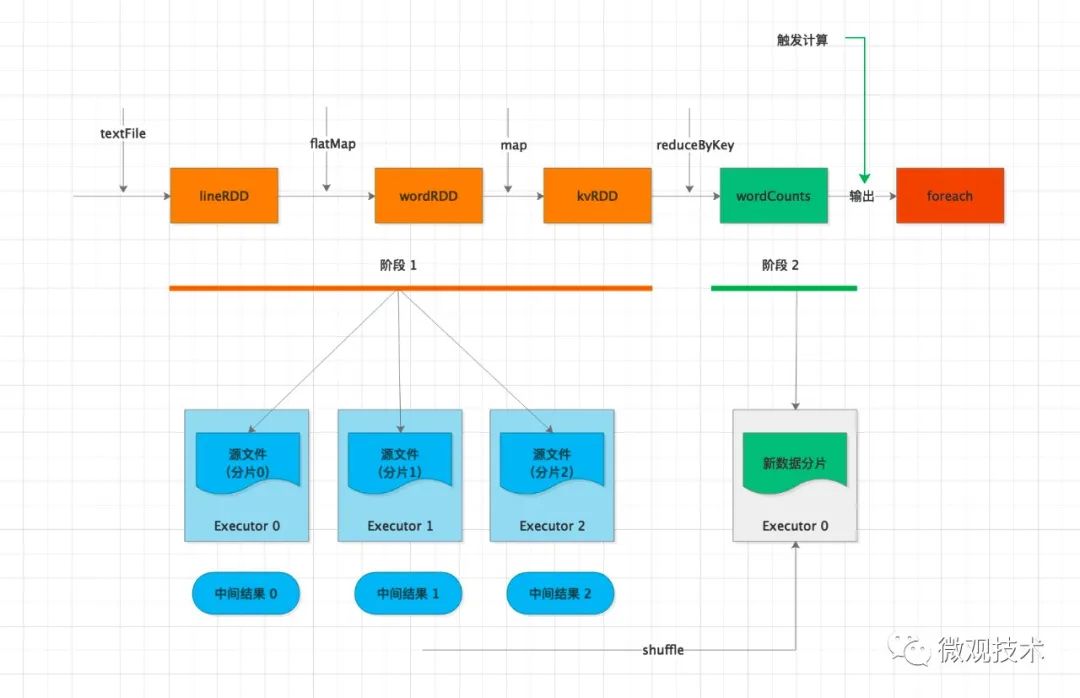
计算过程:
Driver 通过 foreach 这个 Action 算子,触发计算流图的执行,上图自左向右执行,以 shuffle 为边界,创建、分发分布式任务。
其中的 textFile、flatMap、map 三个算子合并成一份任务,分发给每一个 Executor。Executor 收到任务后,对任务进行解析,把任务拆解成 textFile、flatMap、map 3 个步骤,然后分别对自己负责的数据分片进行处理。
每个 Executor 执行完得到中间结果,然后向 Driver 汇报任务进度。接着 Driver 进行后续的聚合计算,由于数据分散在多个分片,会触发 shuffle 操作。
shuffle 机制是将原来多个 Executor中的计算结果重新路由、分发到同一个 Executor,然后对汇总后的数据再次处理。在集群范围内跨进程、跨节点的数据交换。可能存在网络性能瓶颈,需要特别关注。
在不同 Executor 完成数据交换之后,Driver 分发下一个阶段的任务,对单词计数。
同一个key的数据已经分发到相同的 Executor ,每个 Executor 独自完成计数统计。
最后,Executors 把最终的计算结果统一返回给 Driver。
划重点:DAG 到 Stages 的拆分过程,以 Actions 算子为触发起点,从后往前回溯 DAG,以 Shuffle 为边界划分 Stages。
收集结果:
收集结果,按照收集的路径不同,主要分为两类:
1、把计算结果从各个 Executors 收集到 Driver 端
2、把计算结果通过 Executors 直接持久化到文件系统。如:HDFS 或 S3 分布式文件系统。
五、调度系统
1、DAGScheduler
根据用户代码构建 DAG,以 Shuffle 为边界切割 Stages。每个Stage 根据 RDD中的Partition分区个数决定Task的个数,然后构建 TaskSets,然后将 TaskSets 提交给 TaskScheduler 请求调度。
2、TaskScheduler
按照任务的本地倾向性,挑选出 TaskSet 中适合调度的 Task,然后将 Task 分配到 Executor 上执行
3、SchedulerBackend
通过ExecutorDataMap 数据结构,来记录每一个计算节点中 Executors 的资源状态,如 RPC 地址、主机地址、可用 CPU 核数和满配 CPU 核数等
4、Task
运行在Executor上的工作单元
5、Job
SparkContext提交的具体Action操作,常和Action对应
6、Stage
每个Job会被拆分很多组任务(task),每组任务被称为Stage,也称 TaskSet
调度系统的核心思想:数据不动、代码动
六、内存管理
Spark 的内存分为 4 个区域,Reserved Memory、User Memory、Execution Memory 和 Storage Memory
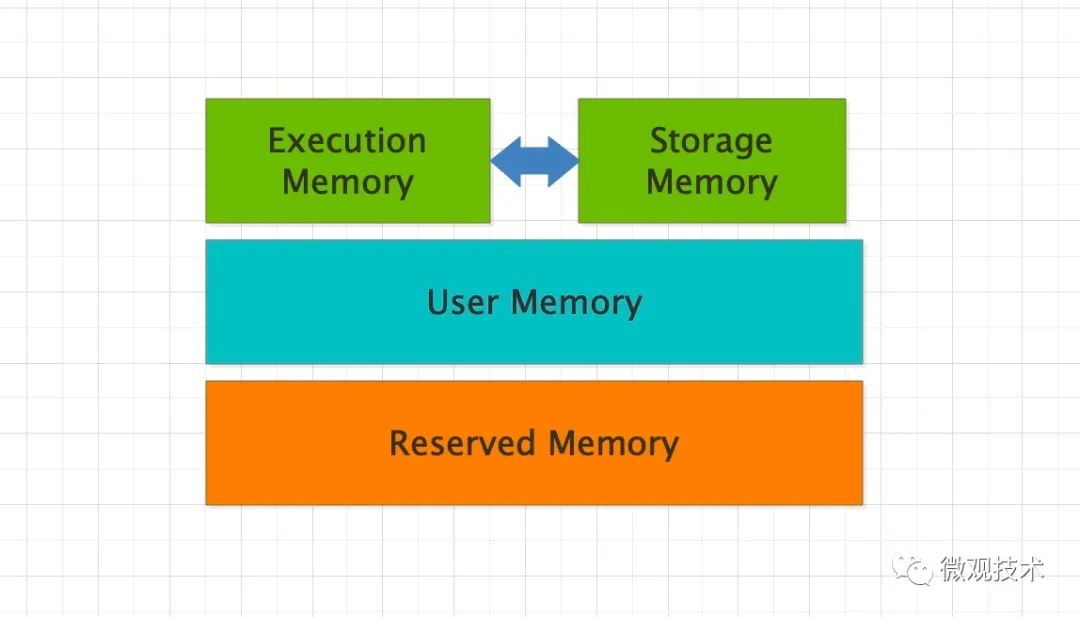
1、Reserved Memory:固定为 300MB,Spark 预留的,用来存储各种 Spark 内部对象的内存区域
2、User Memory:存储开发者自定义的数据结构,例如 RDD 算子中引用的数组、列表、映射
3、Execution Memory:执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等
4、Storage Memory:缓存分布式数据集,如 RDD Cache、广播变量等
整个内存区域,Execution Memory 和 Storage Memory 最重要。在 1.6 版本之后,Spark 推出了统一内存管理模式,这两者可以相互转化。
七、共享变量
Spark 提供两类共享变量,分别是广播变量(Broadcast variables)和累加器(Accumulators)
1、广播变量
val list: List[String] = List("Tom哥", "Spark")
// sc为SparkContext实例
val bc = sc.broadcast(list)
广播变量的用法很简单,通过调用 SparkContext 下的 broadcast 即可完成广播变量的创建
如果要读取封装的共享数据内容,调用它的 bc.value 函数
好奇宝宝会问,既然 list 可以获取字符串列表,为什么还要封装广播变量呢?
答案:
Driver 端对普通的共享变量的分发是以 Task 为粒度的,系统中有多少个 Task,变量就需要在网络中分发多少次,存在巨大的内存资源浪费。
使用广播变量后,共享变量分发的粒度以 Executors 为单位,同一个 Executor 内多个不同的 Tasks 只需访问同一份数据拷贝即可。也就是说,变量在网络中分发与存储的次数,从 RDD 的分区数,减少为集群中 Executors 的个数。
2、累加器
累加器也是在 Driver 端定义,累计过程是通过在 RDD 算子中调用 add 函数为累加器计数,从而更新累加器状态。
应用执行完毕之后,开发者在 Driver 端调用累加器的 value 函数,获取全局计数结果。
Spark 提供了 3 种累加器,longAccumulator、doubleAccumulator 和 collectionAccumulator ,满足不同的业务场景。
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。