
后ResNet时代的顶流EfficientNet
其实,我对于EfficientNet流派的网络是排斥的,暴力搜索的方法看起来跟创新背道而驰,总觉得不太光彩,这对于深度学习的良性发展会产生一定的负面影响,EfficientNet可能是这个算力爆炸时代的必经之路吧,对工业界来说还是有一定的可取之处的。
下面来介绍一下EfficientNet和EfficientNetV2的设计思路,几个问题放在最后讨论
01
EfficientNet
经验上想要提升网络的精度和速度,就需要对width、depth和resolution三个维度进行平衡。那么如何同时对这三个维度进行平衡可以得到限制条件下最佳网络架构呢,之前的方法基本上都是对这三个维度的其中一个或者其中两个进行调参,通过实验来确定最佳的网络结构,显然这种手工得到的最佳很可能是局部最优,于是EfficientNet通过神经网络架构搜索(NAS)的方式同时对这三个维度进行平衡,搜索得到最优网络架构。
问题定义
首先将网络架构搜索定义成一个复合模型缩放优化问题,需要同时得到最优的width、depth和resolution。
假设一层卷积运算定义为
其中i表示第i个stage,
跟以往的网络架构设计不同的是,EfficientNet的网络搜索过程不改变
通过上述假设定义,EfficientNet的网络架构搜索变成了一个带限制条件的多目标优化问题。
其中w,d,r分别是width、depth和resolution三个维度的缩放系数。
问题定义完成后,就需要设计NAS搜索必需的三个东西:搜索空间、搜索策略和性能评估策略。
搜索空间
EfficientNet的最小搜索单元使用的是MBConv,整个网络架构搜索空间和MnasNet相同。先通过MnasNet得到最原始的EfficientNet-B0,然后通过复合缩放得到最优的EfficientNet-B0,最后得到一系列EfficientNet模型。

如上图所示,复合缩放主要由width、depth和resolution三个维度决定。(a)是一个baseline网络架构,(b)、(c)、(d)分别是对width、depth和resolution三个维度进行缩放,(e)是对width、depth和resolution三个维度进行复合缩放。比如(b)可以理解为width扩大2倍,(c)可以理解为depth扩大2倍,(d)可以理解为resolution扩大2倍,然后所有卷积层的缩放比例是一致的。
为了得到一系列不同大小的模型,EfficientNet提出compound scaling方法,通过一个复合系数来对width、depth和resolution三个维度进行统一缩放

因为网络架构的计算消耗主要由卷积决定的,那么一个搜索得到的网络架构比起baseline相当于FLOPS缩放了
4个缩放系数巧妙的将难以统一起来表示的depth、width和resolution给统一起来了,构成了一个可搜索的复合缩放搜索空间。
搜索策略
通过MnasNet相同的搜索方式搜索出最原始的EfficientNet-B0。EfficientNet通过两个搜索步骤,先确定最优的EfficientNet-B0,然后再确定EfficientNet-B1到EfficientNet-B7,两个步骤如下:
先将
固定为1,然后通过一个小的grid srach搜索得到最优的 三个缩放系数。EfficientNet-B0最优的缩放系数分别为 。 然后固定住
,缩放 获得EfficientNet-B1到EfficientNet-B7。
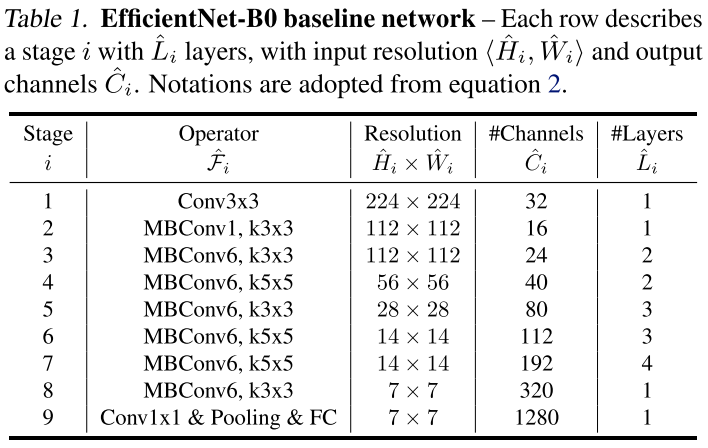
最原始的EfficientNet-B0结构如上图所示。
性能评估策略
性能评估策略和MnasNet保持一致,使用
作为优化目标,T和w作为平衡因子。
在当时大幅度超过之前的网络架构,如AmoebaNet、SENet等。
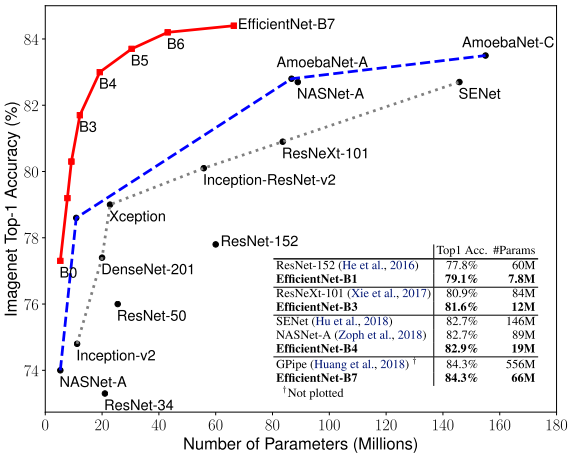
然而,深度可分离卷积当年用来降低参数量和FLOPS的操作,却成了使EfficientNet变慢的重要因素,为后续EfficientNetV2埋下了伏笔。
02
EfficientNetV2
EfficientNetV2指出了EfficientNet存在的三个问题:
EfficientNet在非常大的图片上训练速度慢。因为计算资源是固定的,图片尺寸的增大意味着更小的batch size,导致训练速度变慢。EfficientNetV2通过提出的Progressive Learning解决这个问题。
浅层的深度可分离卷积导致训练速度变慢。虽然深度可分离卷积比起普通卷积有更小的参数量和FLOPS,但是深度可分离卷积需要保存的中间变量比普通卷积多,大量时间花费在读写数据上,导致训练速度变慢。EfficientNetV2通过将浅层的MBConv替换成Fused-MBConv来解决这个问题。
每个stage的缩放系数相同是次优的。因为不同stage对训练速度和参数效率的贡献是不相同的。EfficientNetV2通过使用非均匀缩放策略来逐渐增加深层stage的层数。
Training-Aware NAS
为了解决2和3问题,EfficientNetV2提出了Training-Aware NAS。
搜索空间
搜索空间和MnasNet类似,EfficientNetV2的搜索空间为:operation types {MBConv、Fused-MBConv},kernel size {3x3, 5x5},expansion ratio {1, 4, 6},为了缩小搜索空间,去掉了不必要的操作,并且复用MnasNet搜索得到的通道数。
其中MBConv和Fused-MBConv结构如下
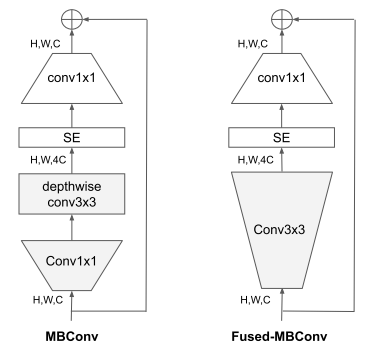
Fused-MBConv将MBConv的3x3深度可分离卷积和1x1卷积合并成一个3x3的普通卷积。
搜索策略
因为搜索空间已经足够小了,可以在更大(EffcientNet-B4大小相当)的网络上使用random search进行搜索。
搜索得到的EfficientNetV2-S架构如下:

和EfficientNet相比较,有4点不同:
在浅层使用Fused-MBConv
更小的expansion ratio
堆叠更多层3x3的MBConv
移除掉最后一个stride为1的stage
和EfficientNet类似,使用复合缩放的方法来得到EfficientNetV2-M/L。这一步还做了两点优化:
1.将最大推理图片尺寸限制在480以下
2.在后面的stage逐渐添加更多的层
性能评估策略
结合模型精度A、归一化后的训练时间S和参数大小P三个参数,构造了性能评估策略:
Progressive Learning
作者做了个实验,当图像尺寸较小时,数据增强效果较弱,精度最好;但对于更大的图像,数据增强效果越强,精度越好。实验证明随着图像尺寸的变大,需要更强的正则化来防止过拟合。

上图展示了作者提出的progressive learning的训练过程: 在训练的早期,使用较小的图像和弱正则化来训练网络,使网络能够轻松快速地学习简单的表示。然后,随着图像大小的逐渐增加,也逐渐增加更强的正则化,使学习更加困难。
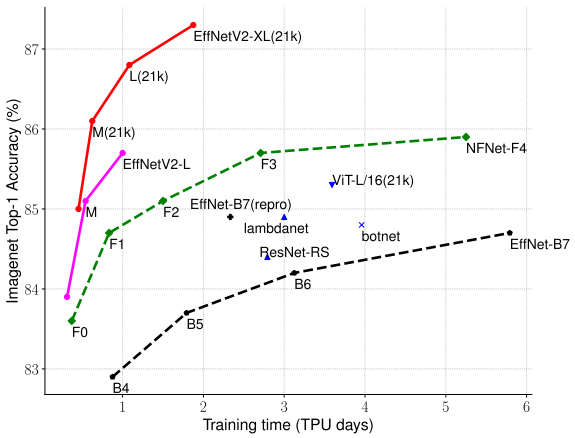
EfficientNet和EfficientNetV2的对比
最终的实验结果,训练速度上大幅度超过之前的网络架构,并且精度进一步提升。
几个问题
深度可分离卷积为什么会导致速度变慢?
虽然深度可分离卷积比起普通卷积有更小的参数量和FLOPS,但是深度可分离卷积需要保存的中间变量比普通卷积多,大量时间花费在读写数据上,导致训练速度变慢。
详细解析: Phoenix Li:FLOPs与模型推理速度
自适应正则化为什么有效?

这里讲一下我的理解,如上图所示,随着epoch的增加,图像尺寸越大,帕累托最优前沿越往向上移动,需要更强的正则化来使网络性能接近帕累托最优前沿。
帕累托解析: 木木松:多目标优化之帕累托最优
总结
EfficientNetV2还是延续了EfficientNet的风格,利用强大的计算资源暴力搜索,得到一些看不懂的超参,令人惊喜的地方在于对训练速度的改进。EfficientNet槽点固然很多,但是不可否认,它对于工业界的影响力之大。
时至今日,对手换了一批又一批,EfficientNet还是那个EfficientNet,一个只有谷歌能玩的游戏。多年以后人们还会记得那个让人又爱又恨的网络。
Reference
[1] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks Mingxing
[2] EfficientNetV2: Smaller Models and Faster Training
---------------------------End---------------------------
10000+人已加入矩阵司南
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
非常感谢对我们的支持! 